一种基于大数据的服务器集群化部署监测系统及方法与流程
本发明涉及大数据,具体是一种基于大数据的服务器集群化部署监测系统及方法。
背景技术:
1、服务器集群化部署是一种将多台服务器组合起来协同工作的方式。它能显著提升性能,把工作负载分摊到各服务器,加快处理速度;还可增强可用性,一台服务器故障不影响整体服务;此外,集群化部署便于扩展,随业务增长添加新服务器。常见类型有负载均衡、高可用和高性能计算集群;部署时要考虑硬件、网络和算法等因素,是构建强大it基础设施的重要途径。
2、服务器集群部署通常依赖于专家经验和固定的规则来进行决策,这可能导致部署方案缺乏灵活性和适应性,尤其是在面对复杂、多变的需求时,容易产生不适用或低效的部署方案;此外,现有技术中,部署后的效果反馈机制通常不完善,难以通过历史部署效果来指导未来的部署,缺乏持续改进的能力。
技术实现思路
1、本发明的目的在于提供一种基于大数据的服务器集群化部署监测系统及方法,以解决现有技术中提出的问题。
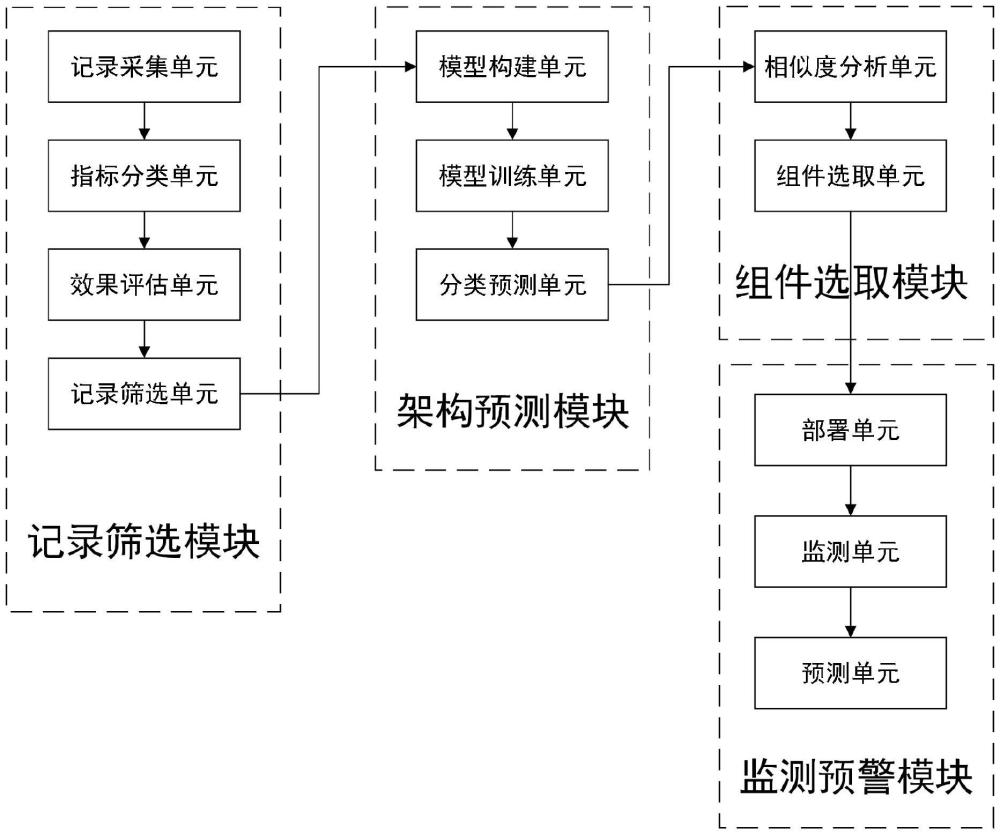
2、为实现上述目的,本发明提供如下技术方案:一种基于大数据的服务器集群化部署监测系统,该系统包括记录筛选模块、架构预测模块、组件选取模块和监测预警模块;
3、所述记录筛选模块用于收集和通过指标效果筛选服务器集群化部署记录;所述架构预测模块用于根据部署需求和部署架构来构建模型对新部署需求进行对应部署架构的分类预测;所述组件选取模块用于根据同一架构下部署需求和新部署需求之间的相似度来选取组件;所述监测预警模块用于根据选取的架构和组件集群化部署服务器并进行监测和预测;
4、所述记录筛选模块的输出端与所述架构预测模块的输入端相连接;所述架构预测模块的输出端与所述组件选取模块的输入端相连接;所述组件选取模块的输出端与所述监测预警模块的输入端相连接。
5、所述记录筛选模块包括记录采集单元、指标分类单元、效果评估单元和记录筛选单元;
6、所述记录采集单元用于采集历史服务器集群化部署记录和新部署需求;所述指标分类单元用于对采集到的指标数据进行分类;所述效果评估单元用于根据指标数据对集群化部署效果做出评估;所述记录筛选单元用于设置阈值并筛选出效果不小于阈值的记录;
7、所述记录采集单元的输出端与所述指标分类单元的输入端相连接;所述指标分类单元的输出端与所述效果评估单元的输入端相连接;所述效果评估单元的输出端与所述记录筛选单元的输入端相连接;所述记录筛选单元的输出端与所述架构预测模块的输入端相连接。
8、所述架构预测模块包括模型构建单元、模型训练单元和分类预测单元;
9、所述模型构建单元用于根据部署需求和其对应的部署架构构建模型;所述模型训练单元用于对模型进行训练;所述分类预测单元用于根据训练的模型对新部署需求进行分类预测;
10、所述模型构建单元的输出端与所述模型训练单元的输入端相连接;所述模型训练单元的输出端与所述分类预测单元的输入端相连接;所述分类预测单元的输出端与所述组件选取模块的输入端相连接。
11、所述组件选取模块包括相似度分析单元和组件选取单元;
12、所述相似度分析单元用于计算新部署需求与分类预测架构对应每一条记录的部署需求之间的余弦相似度;所述组件选取单元用于选取余弦相似度值最高的一条记录对应的组件作为新部署需求部署所用组件;
13、所述相似度分析单元的输出端与所述组件选取单元的输入端相连接;所述组件选取单元的输出端与所述监测预警模块的输入端相连接。
14、所述监测预警模块包括部署单元、监测单元和预警单元;
15、所述部署单元用于根据分类预测的架构和选取的组件对服务器进行集群化部署;所述监测单元用于定时收集服务器集群的指标数据;所述预测单元用于根据收集到的指标数据建立时间序列预测模型进行预测并设置阈值用于预警;
16、所述部署单元的输出端与所述监测单元的输入端相连接;所述监测单元的输出端与所述预测单元的输入端相连接。
17、一种基于大数据的服务器集群化部署监测方法,该方法包括以下步骤:
18、step1、从历史部署和相应的日志中收集服务器集群化部署记录;
19、step2、设置阈值a,评估每条记录的部署效果,筛选部署效果不小于a的记录;
20、step3、对于筛选出的记录,根据其需求和所选择的架构构建机器学习模型,使用模型对新需求进行预测;
21、step4、根据选取架构对应的所有记录得到与新部署需求相似度最高的一条记录对应的架构组件作为新的部署需求的组件;
22、s5、根据得到的架构及架构组件对服务器进行集群化部署,监测集群的负载情况并进行预测。
23、在步骤step1中,每一条所述服务器集群化部署记录包括:部署需求、部署架构、架构组件以及指标日志;
24、所述部署需求是指在服务器集群化部署过程中,系统或应用需要满足的业务需求或性能目标;表示为:[r1,r2,…,rr];其中,r为正整数,表示部署需求的数量,rr表示第r个部署需求;
25、所述部署架构是指实现部署需求的整体设计和结构安排,包括服务器集群的组织方式、服务的分布方式以及网络拓扑结构;表示为:[s1,s2,…,sh];其中,h为正整数,表示部署架构的种类数量,sh表示第h个部署架构种类;
26、所述架构组件是指组成部署架构的各个具体硬件和软件部分;这些组件是实际构建和运行部署架构的基础元素;表示为:[m1,m2,…,mm];其中,m为正整数,表示架构组件的数量,mm表示第m个架构组件;
27、所述指标日志是指收集到的一段时间内的服务器集群系统性能数据和运行状态的记录;时间表示为:[t1,t2,…,tt];每次收集的指标表示为:[d1,d2,…,dd];其中,t为正整数,表示收集指标数据的次数,tt表示第t次收集指标数据的时间;d为正整数,表示指标的数量,dd表示第d个指标;
28、一条完整的服务器集群化部署记录表示为:[r1,r2,…,rr,sb,m1,m2,…,mm,(t1)d1,d2,…,dd,(t2)d1,d2,…,dd,…,(tt)d1,d2,…,dd];其中,sb∈{s1,s2,…,sh},表示每条记录只对应一种部署架构。
29、在步骤step2中,所述阈值a表示一种效果,0<a<100%;
30、所述评估每条记录的部署效果具体方式为:根据指标数据计算部署效果;将指标分为最佳范围类指标和极端优化类指标;所述最佳范围类指标表示指标在一个特定的范围内效果最佳;所述极端优化类指标表示指标越高效果越好或越低效果越好;
31、对于最佳范围类指标,设置上限阈值a1,下限阈值a2,a1>a2;设置(a1+a2)/2处效果为100%,设置阈值a1、a2处效果为a;当指标数据v(di)>a1或v(di)<a2时效果设置为0;当指标数据a2<v(di)<a1时,效果e(di)可表示为:e(di)=1-|v(di)-(a1+a2)/2|/(a1-(a1+a2)/2)×(1-a);
32、其中,i为正整数,i∈{1,2,…,d};v(di)表示第i个指标di的值;e(di)表示第i个指标di的效果;
33、对于极端优化类指标,将其分为高端优化类指标和低端优化类指标;对于高端优化类指标,设置下限阈值a31、高端阈值a32,a32>a31,设置高端阈值a32处效果为100%,设置下限阈值a31处效果为a;当指标数据v(dj)<a31时,效果为0;当指标数据v(dj)>a32时,效果为100%;当指标数据a31<v(dj)<a32时,效果e(dj)可表示为:
34、e(dj)=a+(v(dj)-a31)/(a32-a31)×(1-a);
35、其中,j为正整数,j∈{1,2,…,d};v(dj)表示第j个指标dj的值;e(dj)表示第j个指标dj的效果;
36、对于低端优化类指标,设置上限阈值a4,设置指标数据为0时效果为100%,设置阈值a4处效果为a;当指标数据v(dk)>a4时效果设置为0;当指标数据0<v(dk)<a4时,效果e(dk)可表示为:e(dk)=1-v(dk)/a4×(1-a);
37、其中,k为正整数,k∈{1,2,…,d};v(dk)表示第k个指标dk的值;e(dk)表示第k个指标dk的效果;
38、计算出每一指标一段时间内的平均效果:
39、emean(dg)=(et1(dg)+et1(dg)+…+ett(dg))/t;
40、其中,g为正整数,g∈{1,2,…,d};ett(dg)表示在tt时刻第g个指标dg的效果;emean(dg)表示t个时刻第g个指标dg的平均效果;
41、计算出所有指标的综合效果e(d):
42、e(d)=(emean(d1)+emean(d2)+…+emean(dd))/d,筛选出部署效果不小于a的记录。
43、在步骤step3中,对于筛选出的记录,根据其需求和所选择的架构构建机器学习模型;
44、数据处理:对于输入特征部署需求值[r1,r2,…,rr]以及输出标签部署架构[s1,s2,…,sh],对其中类别型特征进行one-hot编码转换为二进制特征,对数值型特征进行标准化;
45、输入特征矩阵表示为:
46、
47、其中,x表示输入特征矩阵,大小为n×r;n为正整数,表示记录的数量;r是特征的数量,rnr表示数值化和标准化后的第n条记录的第r个部署需求特征值;
48、输出标签矩阵表示为:
49、
50、其中,y表示输入特征矩阵,大小为n×1;n为正整数,表示记录的数量;s(1),…,s(n)分别表示部署需求特征r1r,…,rnr对应的数值化和标准化后的部署架构标签;
51、使用机器学习算法lightgbm对部署需求及其对应的部署架构构建模型并进行训练;
52、模型构建:模型通过输入特征矩阵x预测输出标签y,表示为函数f:y=f(x;θ);
53、其中,f是lightgbm模型的函数表示形式;θ是模型的参数集;
54、模型通过最小化损失函数来学习输入和输出之间的关系:
55、
56、其中,l是损失函数,衡量模型预测值与真实值之间的误差;k∈{1,2,…,h},k是所有可能的类别数量;p∈{1,2,…,n},q∈{1,2,…,k},ypq表示第p条记录的真实类别标签,属于第q类时为1,否则为0;表示模型预测的第p条记录属于第q类的概率;
57、lightgbm通过迭代方式训练多个决策树,每棵树都试图纠正前一棵树的错误:
58、
59、其中,表示在第e次迭代后的模型预测结果;η表示学习率,控制每棵树对模型预测的贡献大小;fe(x;θe)是第e棵决策树,根据输入特征矩阵x进行预测;
60、对于新的部署需求特征向量x′,模型预测出最合适的部署架构标签s′:s′=f(x′;θ)。
61、在步骤step4中,根据选取架构对应的所有记录得到与新部署需求相似度最高的一条记录对应的架构组件作为新的部署需求的组件具体方式为:
62、新部署需求分类得到的部署架构对应的记录中,对每一条记录的部署需求进行数值化和标准化处理,得到每一条记录的部署需求向量;对新部署需求进行数值化和标准化处理得到新部署需求向量;计算新部署需求向量与每一条记录的部署需求向量之间的余弦相似度,选取余弦相似度值最高的记录对应的架构组件作为新的部署需求的组件;
63、在步骤step5中,对服务器集群负载情况进行预测的具体方式为:
64、定时收集服务器集群的各项指标并形成指标日志,使用时间序列预测模型预测各指标走向;设置各指标阈值,当存在指标预测值超出对应设定阈值时向管理人员发出预警。
65、与现有技术相比,本发明的有益效果是:
66、1、本发明通过引入机器学习模型,能够根据历史记录中筛选出的优质部署架构,对新的部署需求进行精确预测;
67、2、本发明通过集成机器学习和相似度匹配的自动化决策过程,减少了人工干预的需求,简化了服务器集群化部署的操作流程,提升了整体运维效率;
68、3、本发明充分利用大数据进行动态的部署效果评估和预测,使得系统能够更好地适应复杂和变化的环境需求。
- 还没有人留言评论。精彩留言会获得点赞!