一种基于神经网络的3D语义场景图构建方法与流程
本发明属于点云数据处理,具体涉及一种基于神经网络的3d语义场景图构建方法。
背景技术:
1、了解复杂的3d真实世界环境对于包括机器人、ar/vr和导航在内的各种应用至关重要。在此背景下,三维语义场景图(3dssg)的预测得到了广泛的关注。其重点在于预测3d点云环境中的实例类别,并确定它们的潜在关系。对于任意的主体-客体实例对,关系三元组<主体类别,主客体关系,客体类别>结构化的表征了二者的信息,同时也是构成3d语义场景图的基本元素。
2、传统的方法主要集中在全局场景处理上,而同时识别这些复杂场景中的所有实例及其潜在关系使得其无法进行更精细的细粒度特征提取。其主要的局限性来自三个因素:
3、(1)所使用的3d包围盒采样算法获取的点云子场景粗糙且不均匀,导致用于特征提取的上下文环境信息不完整;
4、(2)依赖于单尺度点云特征提取,无法提供实例识别所需的细粒度局部模式和实例对关系预测所需的大感受野特征;
5、(3)局部上下文信息提取过程中采用的pointnet算法缺乏对复杂环境的感知能力。
技术实现思路
1、为解决现有技术的不足,实现提升3d语义场景中实例分类预测效果的目的,本发明采用如下的技术方案:
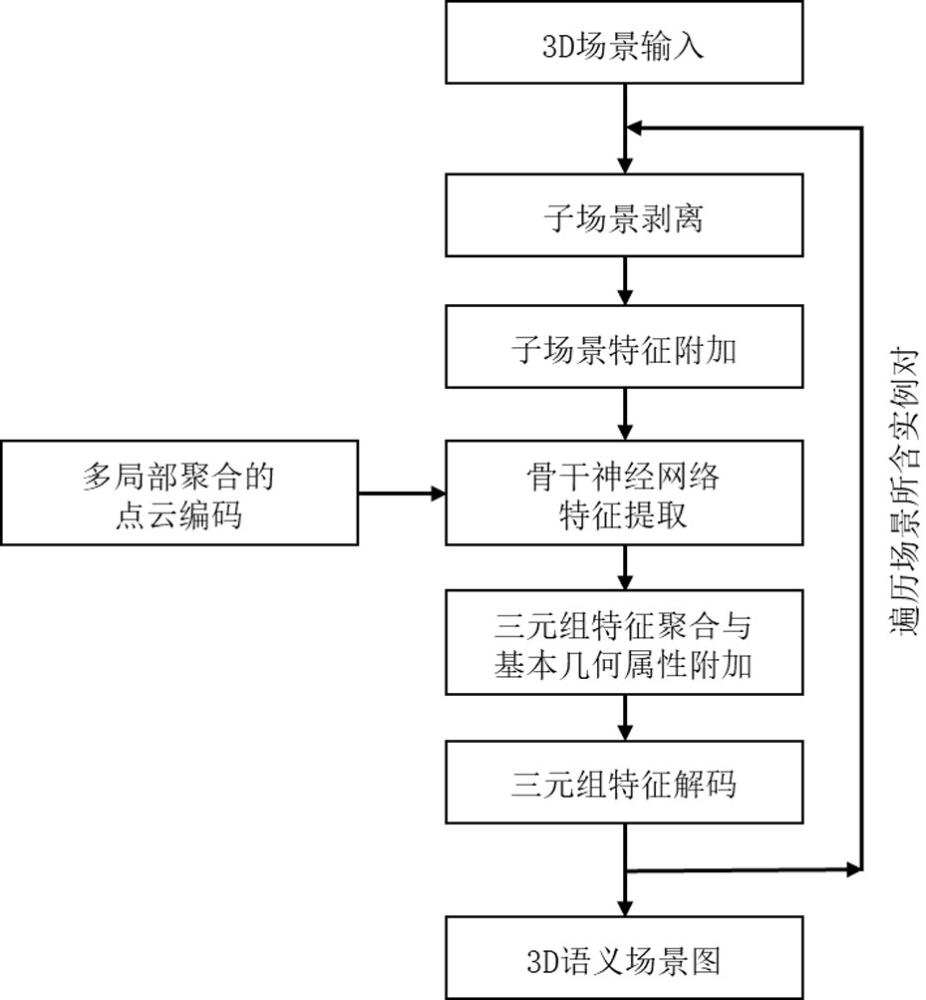
2、一种基于神经网络的3d语义场景图构建方法,包括如下步骤:
3、步骤1:获取点云信息,从点云信息的实例场景中剥离出主体实例、客体实例及其上下文环境点云的子场景;
4、步骤2:构建多层次的特征提取骨干神经网络,进行不同层次的特征提取;通过多局部聚合的点云编码,先对子场景进行各点的局部上下文特征提取,再对子场景中的各点进行多层次的实例和实例对的特征聚合,寻找并聚合多个包含自身特征点的局部点集中目标点的特征,增强各点对周围邻域的模式识别能力,实现多局部特征的交互;
5、步骤3:基于多层次的特征提取骨干神经网络,获取实例和实例对的语义特征并对其解码,得到实例类别和主、客体关系;
6、步骤4:返回步骤1直至遍历完全局子场景,得到所有关系三元组,以构建完整的3d语义场景图。
7、进一步地,所述步骤1中,确定主、客体实例对,采用自适应包络方法,通过最远点采样法对实例进行关键点的均匀采样,提取一系列实例中的关键点集合,采用球形采样捕获关键点周边的上下文点云信息,由于物体的包络结构可由有限个球体接近,该算法可以自适应的得到实例的周边环境;融合主、客体实例的周边环境,生成三元组特征提取所需的子场景。从而避免引入与目标主体-客体无关的远距离点云,同时,尽可能的保留了连续且重要的实例周边上下文环境点云。
8、进一步地,所述子场景生成公式如下:
9、
10、其中,分别表示主、客体实例,f(·)表示最远点采样算法,分别表示主、客体关键点,n、n’分别表示主、客体关键点的数量,b(·)表示球形采样算法,r表示球形采样的半径,分别表示主、客体实例的周边环境,表示主、客体实例对的上下文环境点云的子场景,优选的,采样半径为1m。
11、进一步地,所述步骤1中进行子场景特征附加,计算子场景点云中各点与主、客体实例的距离,通过前述剥离的子场景点云进行进一步的距离属性附加,能够辅助实例间空间关系的提取;子场景各点距离目标实例的距离特征需要经过标准化,以优化神经网络的特征提取,计算公式如下:
12、
13、其中,表示子场景s中的第m个点,dist(·)表示点到实例的最近距离,max(·)表示取最大值操作,表示第m个点与主体实例的距离特征,表示第m个点与客体实例的距离特征。
14、进一步地,所述步骤2中,对于子场景中每个点的局部点集,引入位置与距离编码,提升对主客体实例位置的感知;
15、对于中心点xa的局部邻域点集引入位置与距离编码来表征集合内任意点xi与中心的相对几何关系,编码的计算过程表示如下:
16、
17、其中,pa表示中心点位置信息,pi表示任意点位置信息,表示中心点与主体实例的距离,表示任意点与主体实例的距离,表示中心点与客体实例的距离,表示任意点与客体实例的距离,cat(·)表示拼接函数,mlppos(·)表示该编码的特征映射函数;
18、将点的原始特征与其对应的编码相加,得到经过相对空间特征增强的点特征及对应更新后的点集
19、进一步地,所述步骤2中,对于中心点xa的局部邻域点集采用自注意力算法对对子场景进行各点的局部上下文特征提取,公式如下:
20、
21、其中,q、k和v表示自注意力机制的查询、键和值,wq、wk和wv分别表示q、k和v对应的可训练权重矩阵,t表示矩阵的转置,dk表示键的维度,表示尺度因子,表示编码后的点集特征。
22、进一步地,所述特征聚合,采用k近邻算法对每个目标点搜索其邻近点集合对于以邻近点为中心的局部点集中,提取该点集中与采样点xa有关的编码特征表示与采样点xa有关的编码后的点集特征,并行抽取所有邻近点中的相关特征,以构建多邻域视角下的采样点特征集合并在获得特征集合后,该编码使用一组共享参数的mlp(shared mlp)在特征通道维度进行特征聚合,最终得到聚合后的特征ga,特征聚合的后,属于实例和实例对的基本几何属性也以特征编码的形式附加于聚合特征,公式如下:
23、
24、其中,s表示子场景,knn(·)表示k近邻算法函数,a表示采样点编号,b、c表示采样点的邻近点编号,xk表示第k个邻近点,ga(·)表示通道层面的特征聚合函数。
25、进一步地,所述步骤1中进行子场景特征附加,向剥离的子场景中添加主体-客体实例掩膜,以指导关系三元组中的实例辨别;所述步骤3中,在骨干神经网络中具有不同分辨率的两个特定阶段,分别通过主体-客体实例掩膜,剥离并聚合子场景中主体、客体实例以及二者实例对的特征,主体、客体实例的特征为其实例掩膜对应特征图的聚合特征,主体-客体实例对的特征为二者特征图并集的聚合特征。
26、进一步地,所述步骤1中,使用点云语义分割算法对原始点云中的各类别实例进行分割,并采用点云聚类算法进行单个实例的聚类,得到环境中各实例的掩膜,公式如下:
27、
28、其中,表示环境中的各个实例,对于每个实例,均分配一个不重复的实例掩膜{m1,...,mn},cluster(·)表示聚类算法,seg(·)表示室内点云语义分割算法。
29、进一步地,所述步骤3中,为单个实例以及实例对附加表征物体基本几何属性的特征编码,减少因骨干网络下采样导致的基本几何属性的丢失;
30、对于单个实例所补充的基本几何特征,包括物体几何中心的三维坐标g=(gx,gy,gz)和物体包围盒的尺寸s=(sx,sy,sz),下标x、y、z分别表示三维分量;
31、对于实例对所补充的基本几何特征,包括两物体的几何中心差值、包围盒尺寸差值,以及物体体积v=sxsysz的差值;
32、对于两类特征补充,分别采用两组多层感知机进行编码,算法公式如下:
33、
34、δrel=mlprel(cat(gi-gj,si-sj,ln(vi/vj)))
35、其中,mlpins(·)和mlprel(·)分别表示实例编码函数和关系编码函数,cat(·)表示特征拼接函数,表示编码后的第i个实例特征,δrel表示编码后的实力对特征,优选的,对于物体间体积的差值采用对数函数进行处理,以减小数值范围,稳定网络训练;
36、再通过两组多层感知机mlp对实例特征及实例对特征进行解码,得到预测的关系三元组,模型使用加权的组合损失作为总损失,优选的,对于实例类别的预测,选用cross-entropy作为损失函数,对于实例对的关系预测,选用binary-cross-entropy作为损失函数。
37、本发明的优势和有益效果在于:
38、本发明的一种基于神经网络的3d语义场景图构建方法,通过精细全面的子场景构建、多尺度针对性的点云特征提取网络以及融合多局部点集特征的编码器,实现高精度的场景图构建,建立了3d场景图预测的新范式。实验表明,本发明达到了目前3d语义场景图预测的最好效果,尤其提升了复杂场景中的实例分类效果。
- 还没有人留言评论。精彩留言会获得点赞!