一种ViT蒸馏训练方法、系统、装置及可读存储介质与流程
本发明涉及算机视觉和深度学习,更具体的说是涉及一种vit蒸馏训练方法、系统、装置及可读存储介质。
背景技术:
1、随着深度学习技术的快速发展,视觉transformer(vision transformer,vit)作为一种新兴的深度学习模型,在图像识别、分类等任务中展现出了强大的性能。然而,在实际应用中,尤其是在处理长尾数据集(long-tailed datasets)时,vit模型面临着诸多挑战。长尾数据集指的是数据集中某些类别的样本数量远多于其他类别,这种不平衡的数据分布往往导致模型在少数类别上的性能显著下降,即所谓的“长尾效应”。
2、传统的深度学习模型,包括卷积神经网络(convolutional neural networks,cnns),在长尾数据集上也存在类似的问题。尽管cnn在图像识别领域取得了显著成就,但其对局部特征的依赖使得模型在处理少数类别时容易陷入过拟合,特别是在这些类别的样本数量有限的情况下。
3、为了克服这一挑战,研究者们提出了多种方法,如重采样、重加权损失函数等,以平衡不同类别在训练过程中的贡献。然而,这些方法在提升模型对少数类别识别能力的同时,也可能对多数类别的性能产生负面影响。
4、知识蒸馏(knowledge distillation)作为一种模型压缩和迁移学习技术,近年来在深度学习领域得到了广泛关注。通过将复杂教师模型(teacher model)的知识传递给简单学生模型(student model),知识蒸馏能够在保持或提升模型性能的同时,减少模型的复杂度和计算成本。在长尾数据集的背景下,知识蒸馏技术有望通过教师模型对少数类别的有效学习,帮助学生模型提升对少数类别的识别能力。
5、然而,现有的知识蒸馏方法大多针对平衡数据集设计,直接应用于长尾数据集时效果有限。因此,需要一种专门针对长尾数据集优化的知识蒸馏训练方法,以有效提升vit模型在长尾数据集上的分类性能和泛化能力。
技术实现思路
1、针对以上问题,本发明的目的在于提供一种vit蒸馏训练方法、系统、装置及可读存储介质,通过结合长尾数据集预处理、教师网络训练、知识蒸馏及损失重加权等技术,有效提升vit模型在长尾数据集上的分类性能和泛化能力。
2、本发明为实现上述目的,通过以下技术方案实现:
3、第一方面,本发明公开了一种vit蒸馏训练方法,包括:
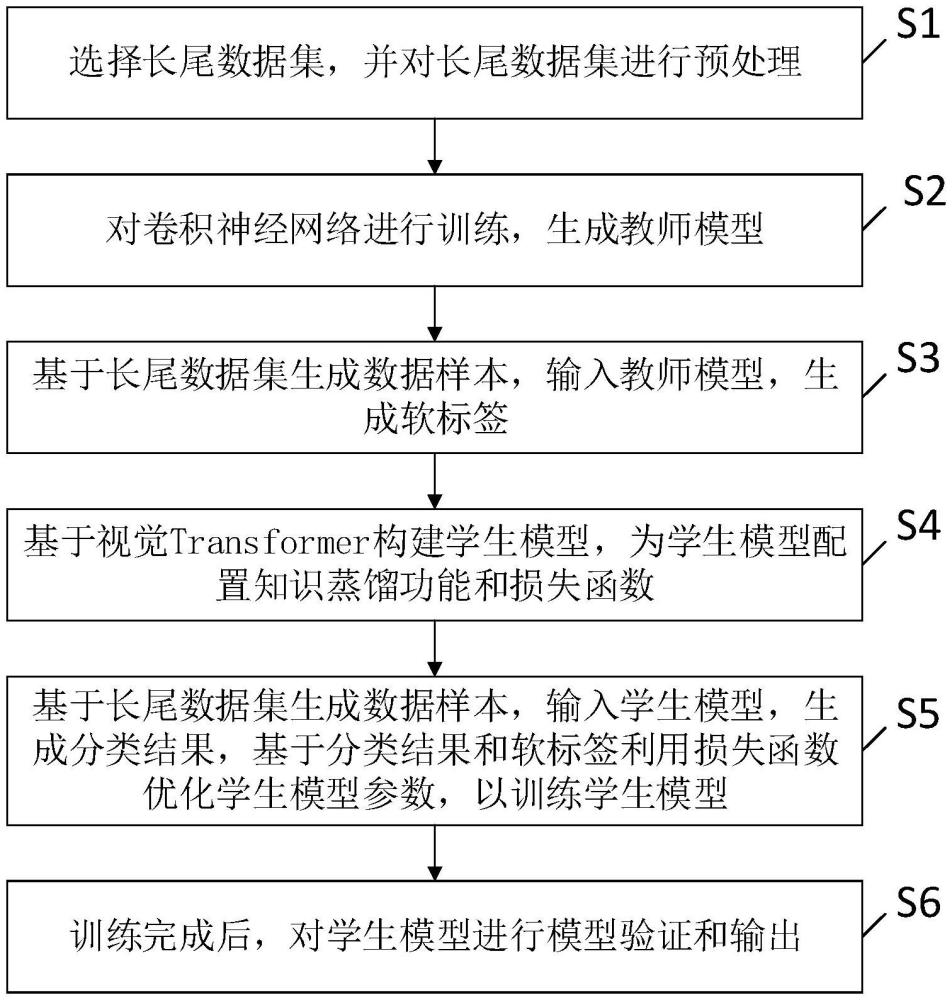
4、选择长尾数据集,并对长尾数据集进行预处理;
5、对卷积神经网络进行训练,生成教师模型;
6、基于长尾数据集生成数据样本,输入教师模型,生成软标签;
7、基于视觉transformer构建学生模型,为学生模型配置知识蒸馏功能和损失函数;
8、基于长尾数据集生成数据样本,输入学生模型,生成分类结果,基于分类结果和软标签利用损失函数优化学生模型参数,以训练学生模型;
9、训练完成后,对学生模型进行模型验证和输出。
10、进一步,所述选择长尾数据集,并对长尾数据集进行预处理,包括:
11、选择cifar-10-lt或imagenet-lt作为长尾数据集;
12、对长尾数据集的尾部类别进行过采样,对长尾数据集的头部类别进行欠采样,以生成数据样本;
13、根据每个类别的数据样本的数量调整类别权重并在计算损失函数时重加权尾部类别的损失;
14、对所有样本数据进行弱增强处理,并对尾部类别的样本数据进行强增强处理,以生成分布外图像。
15、进一步,所述对卷积神经网络进行训练,生成教师模型,包括:
16、对卷积神经网络cspdarknet进行训练;
17、训练时,通过计算sam扰动方向及扰动后的梯度来更新模型参数;
18、训练完成后,生成教师模型。
19、进一步,所述基于长尾数据集生成数据样本,输入教师模型,生成软标签,包括:
20、将强增强处理后的数据样本输入教师模型,生成软标签。
21、进一步,所述基于视觉transformer构建学生模型,为学生模型配置知识蒸馏功能和损失函数,包括:
22、使用视觉transformer作为学生模型;
23、在学生模型中引入用于蒸馏学习的ds token,利用ds token通过模仿教师模型的软标签来学习特征;
24、为学生模型配置用于计算分类损失和蒸馏损失的损失函数;
25、采用交叉熵损失计算分类损失,采用最小化kl散度函数计算蒸馏损失。
26、进一步,所述基于分类结果和软标签利用损失函数优化学生模型参数,包括:
27、基于分类结果和软标签利用损失函数计算分类损失和蒸馏损失来联合优化学生模型的参数;
28、在计算蒸馏损失时,通过提高尾部类别样本数据的软标签的权重,确保尾部类别的样本数据的关注度。
29、进一步,所述弱增强处理包括:
30、随机裁剪处理、水平翻转处理和颜色调整处理;所述强增强处理包括:随机旋转处理、预设幅度的裁剪处理和颜色抖动处理。
31、第二方面,本发明还公开了一种vit蒸馏训练系统,包括:
32、预处理模块,用于选择长尾数据集,并对长尾数据集进行预处理;
33、教师模型构建模块,用于对卷积神经网络进行训练,生成教师模型;
34、软标签生成模块,用于基于长尾数据集生成数据样本,输入教师模型,生成软标签;
35、学生模型构建模块,用于基于视觉transformer构建学生模型,为学生模型配置知识蒸馏功能和损失函数;
36、模型训练模块,用于基于长尾数据集生成数据样本,输入学生模型,生成分类结果,基于分类结果和软标签利用损失函数优化学生模型参数,以训练学生模型;
37、模型验证输出模块,用于训练完成后,对学生模型进行模型验证和输出。
38、第三方面,本发明还公开了一种vit蒸馏训练装置,包括:
39、存储器,用于存储vit蒸馏训练程序;
40、处理器,用于执行所述vit蒸馏训练程序时实现如上文任一项所述vit蒸馏训练方法的步骤。
41、第四方面,本发明还公开了一种可读存储介质,所述可读存储介质上存储有vit蒸馏训练程序,所述vit蒸馏训练程序被处理器执行时实现如上文任一项所述vit蒸馏训练方法的步骤。
42、对比现有技术,本发明有益效果在于:
43、1、本发明通过引入知识蒸馏技术,将教师模型(cnn)生成的软标签传递给学生模型(vit),增强了学生模型对局部特征的提取能力,特别是对少数类别的特征学习能力。
44、2、本发明在学生模型中引入ds token作为蒸馏正则化的工具,提高了vit在蒸馏过程中的效果,进一步提升了模型对长尾数据集的适应性。
45、3、本发明对教师模型使用sam技术进行优化,通过在参数空间中寻找平坦区域进行训练,减少了模型对训练数据的过拟合现象,提高了模型在长尾数据集上的鲁棒性和泛化能力。
46、4、本发明公开了一种专门在长尾数据集训练vit的优化策略,使用cnn作为教师网络,vit作为学生网络进行蒸馏训练;通过使用cspdarknet作为cnn教师网络指导学生网络训练优化,通过在训练cnn时候通过低秩特征学习得到平坦最优解,提升cnn网络对冗余特征的抵抗能力和泛化能力。在训练vit的时,除了cls token和token作为输入外,再增加一个ds token作为蒸馏训练的特征提取优化器,最终的损失函数为vit分类损失和蒸馏损失的加权,由此,vit既可以充分发挥其捕捉长距特征的能力,也可以学习到cnn捕捉局部特征的能力,增强模型再长尾数据集的分类能力。
47、由此可见,本发明与现有技术相比,具有突出的实质性特点和显著的进步,其实施的有益效果也是显而易见的。
- 还没有人留言评论。精彩留言会获得点赞!