车联网数据的处理方法、装置、电子设备及存储介质与流程
本技术涉及车辆领域,并且更具体地,涉及车辆领域中的一种车联网数据的处理方法、装置、电子设备及存储介质。
背景技术:
1、车联网是以行驶中的车辆为信息感知对象,通过信息通信技术,实现车与车、人、路、服务平台之间的网络连接,提升车辆整体的智能驾驶水平,为用户提供安全、舒适、智能、高效的驾驶感受与交通服务。通过对车联网数据进行数据挖掘,确定不同属性特征之间的关联度,能够为用户提供更好的车辆服务。
2、但是,现有技术中在使用聚类算法对车联网进行数据挖掘时,对不同簇的边界点识别不准确以及无法确定车联网中的关键属性特征,导致聚类效果较差;因此,如何提高聚类算法的准确性,从而实现对车联网数据的挖掘是当前需要解决的技术问题。
技术实现思路
1、本技术提供了一种车联网数据的处理方法、装置、电子设备及存储介质,该方法基于目标权重与尺度参数,确定样本数据的目标聚类中心,并对样本数据进行聚类处理,能够提高聚类算法的准确性,以确定车联网数据中各属性特征的关联度。
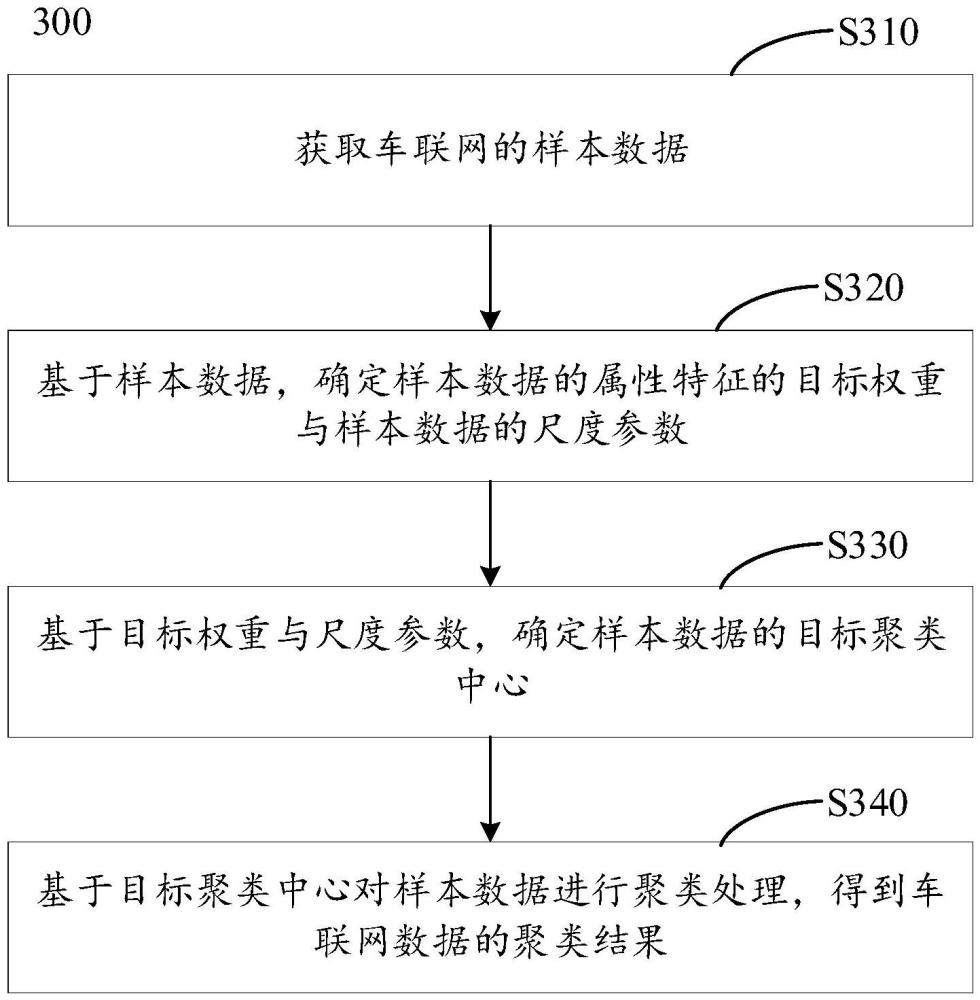
2、第一方面,提供了一种车联网数据的处理方法,该方法包括:
3、获取车联网的样本数据;
4、基于样本数据,确定样本数据的属性特征的目标权重与样本数据的尺度参数;其中,目标权重用于表示属性特征对聚类结果的影响程度;尺度参数用于表示样本数据之间的距离对聚类结果的影响程度;
5、基于目标权重与尺度参数,确定样本数据的目标聚类中心;
6、基于目标聚类中心对样本数据进行聚类处理,得到车联网数据的聚类结果;其中,车联网数据的聚类结果用于表示车联网数据中属性特征的关联度。
7、在本技术的实施例中,在获取到车联网的样本数据后,根据样本数据的属性特征的目标权重与样本数据的尺度参数,确定样本数据的聚类中心;由于目标权重用于表示样本数据的各属性特征对聚类结果的影响程度,不同属性特征对聚类结果的影响程度不同,对应的目标权重不同。此外,由于不同的样本数据对于距离的影响程度存在区别,即不同样本数据对应的尺度参数存在区别;在上述方案中,在确定样本数据的聚类中心时,能够同时考虑到属性特征的目标权重与样本数据的尺度参数两个方面对聚类结果的影响,因此能够确保得到较为准确的聚类中心;在聚类中心更准确的前提下,对样本数据进行聚类处理,能够提高车联网数据的聚类结果的准确性。
8、结合第一方面,在第一方面的某些实现方式中,基于目标权重与尺度参数,确定样本数据的目标聚类中心,包括:
9、基于目标权重与尺度参数,确定目标局部密度排序;其中,目标局部密度排序为样本数据中各样本数据的局部密度排序;
10、基于样本数据与目标样本数据之间的目标距离,确定目标距离排序;其中,目标样本数据为样本数据中局部密度大于各样本数据的局部密度的数据;目标距离为各样本数据与目标样本数据的距离中的最小距离;目标距离排序为样本数据中各样本数据的最小距离排序;
11、基于目标局部密度排序与目标距离排序,确定目标聚类中心。
12、在本技术的实施例中,基于目标权重与尺度参数,确定各样本数据的局部密度;并对各样本数据的局部密度进行排序,得到目标局部密度排序;确定样本数据与目标样本数据之间的目标距离,并对目标距离进行排序,得到目标距离排序;由于局部密度用于表示各样本数据邻域内的数据密度,即邻近区域内样本数据的密集程度;而目标距离用于表示样本数据到其它局部密度更大的样本数据之间的最小距离;因此,基于目标局部密度排序与目标距离排序,确定目标聚类中心;使得得到的目标聚类中心的局部密度较大,且距离局部密度更大的样本数据的距离较远;确保得到较为准确目标聚类中心。
13、结合第一方面和上述实现方式,在第一方面的某些实现方式中,基于目标局部密度排序与目标距离排序,确定目标聚类中心,包括:
14、将位于目标局部密度排序中的前n个,且位于目标距离排序的前n个的第一样本数据,确定为第一聚类中心;
15、若第一聚类中心的评估指标大于预设阈值,将第一聚类中心确定为目标聚类中心;其中,评估指标用于表示第一聚类中心的聚类效果。
16、在本技术的实施例中,将位于目标局部密度排序中的前n个,且位于目标距离排序中的前n个第一样本数据,确定为第一聚类中心;并通过第一聚类中心的评估指标对第一聚类中心进行评估;若第一聚类中心的评估指标大于预设阈值,则将第一聚类中心确定为目标聚类中心;由于是在评估指标大于预设阈值时,将第一聚类中心确定为目标聚类中心;确保能够对聚类中心进行评估;将聚类结果较好的第一聚类中心确定为目标聚类中心;从而能够得到较为准确的聚类结果。
17、结合第一方面和上述实现方式,在第一方面的某些实现方式中,基于样本数据,确定样本数据的属性特征的目标权重与样本数据的尺度参数,包括:
18、确定属性特征相对于目标均值的离散程度;其中,目标均值为样本数据中属性特征的均值;
19、基于离散程度,确定属性特征的目标权重;
20、基于目标权重,确定样本数据的尺度参数。
21、在本技术的实施例中,基于属性特征相对于目标均值的离散程度,确定属性特征的目标权重;若属性特征的离散程度较大,表示该属性特征包含更多的信息,能够表现出不同的样本数据之间的差异;因此,对应的目标权重更大;并基于目标权重,确定样本数据的尺度参数。
22、结合第一方面和上述实现方式,在第一方面的某些实现方式中,基于目标权重,确定样本数据的尺度参数,包括:
23、基于目标权重,确定各样本数据的第一距离与第二距离;其中,第一距离为各样本数据与第二样本数据的距离;第二距离为各样本数据与候选数据集合中各候选数据的距离之和;候选数据集合包括第二样本数据与第二样本数据的邻域内的样本数据;
24、基于各样本数据的第一距离与第二距离的比值,确定各样本数据之间的尺度参数。
25、在本技术的实施例中,基于目标权重,确定各样本数据的第一距离与第二距离;即确定各样本数据与第二样本数据的距离,以及各样本数据与第二样本数据的候选数据集合之间的距离之和;由于候选数据集合包括第二样本数据与第二样本数据的邻域内的样本数据;因此,第二距离能够反映各样本数据与第二样本数据邻域内各样本数据的距离;即第二样本数据的分布不同,第二样本数据的邻域内的样本数据不同,对应的第二距离不同;基于第一距离与第二距离的比值,确定各样本数据之间的尺度参数,得到的尺度参数能够反映两个样本数据之间的距离以及样本数据与候选数据集合之间的距离。
26、结合第一方面和上述实现方式,在第一方面的某些实现方式中,基于目标聚类中心对样本数据进行聚类处理,得到车联网数据的聚类结果,包括:
27、确定各样本数据与目标聚类中心的第三距离;
28、基于各样本数据的第三距离与目标聚类中心,得到车联网数据的聚类结果。
29、在本技术的实施例中,基于各样本数据与目标聚类中心的第三距离与目标聚类中心,得到车联网数据的聚类结果;即遍历各样本数据,并将各样本数据与距离最近的目标聚类中心划分为同一簇数据,得到车联网数据的聚类结果。
30、结合第一方面和上述实现方式,在第一方面的某些实现方式中,在获取车联网的样本数据之前,还包括:
31、获取车联网的初始数据;
32、获取车联网的样本数据,包括:对初始数据进行数据预处理,得到样本数据;其中,数据预处理包括数据清洗、数据转换与数据聚集中的至少一项。
33、在本技术的实施例中,在获取完初始数据后,对初始数据进行数据预处理;从而去除车联网数据中的噪声数据、减少数据维度,提高数据质量,从而能够更好地对样本数据进行聚类,发现车联网数据之间的内在关系,提高聚类分析的准确性。
34、结合第一方面和上述实现方式,在第一方面的某些实现方式中,基于样本数据,确定样本数据的属性特征的目标权重,包括:
35、基于目标需求对样本数据进行特征提取,得到样本数据的属性特征;
36、基于样本数据与属性特征,确定属性特征的目标权重。
37、在本技术的实施例中,由于车联网数据通常包含多种维度的特征;但是并非所有维度的特征都对聚类有实质性的作用;若提取的特征过多,可能导致属性特征的冗余,降低聚类的效率和准确性;因此,基于目标需求对预处理后的样本数据进行特征提取得到样本数据的属性特征,确保得到的属性特征是与目标需求的一致性,从而避免属性特征冗余对聚类的效率与准确性的影响。
38、第二方面,提供了一种车联网数据的处理装置,装置包括:
39、获取模块,用于获取车联网的样本数据;
40、第一确定模块,用于基于样本数据,确定样本数据的属性特征的目标权重与样本数据的尺度参数;其中,目标权重用于表示属性特征对聚类结果的影响程度;尺度参数用于表示样本数据之间的距离对聚类结果的影响程度;
41、第二确定模块,用于基于目标权重与尺度参数,确定样本数据的目标聚类中心;
42、处理模块,用于基于目标聚类中心对样本数据进行聚类处理,得到车联网数据的聚类结果;其中,车联网数据的聚类结果用于表示车联网数据中属性特征的关联度。
43、第三方面,提供了一种电子设备,包括存储器和处理器,该存储器用于存储可执行程序代码,该处理器用于从存储器中调用并运行该可执行程序代码,使得该电子设备执行上述第一方面或第一方面任意一种可能的实现方式中的方法。
44、第四方面,提供了一种计算机程序产品,该计算机程序产品包括:计算机程序代码,当该计算机程序代码在计算机上运行时,使得该计算机执行上述第一方面或第一方面任意一种可能的实现方式中的方法。
45、第五方面,提供了一种计算机可读存储介质,该计算机可读存储介质存储有指令,当该指令在电子设备上运行时,使得该电子设备执行上述第一方面或第一方面任意一种可能的实现方式中的方法。
- 还没有人留言评论。精彩留言会获得点赞!