一种基于人工智能的互联网信息智能决策系统的制作方法
本发明涉及数据处理领域,具体是一种基于人工智能的互联网信息智能决策系统。
背景技术:
1、随着互联网的迅猛发展,信息量呈现爆炸式增长,如何从海量信息中快速、准确地提取有价值的信息,辅助决策,成为了一个重要的研究课题和实际需求,传统的信息处理方法已经无法满足当前复杂多变的需求,因而基于人工智能的互联网信息智能决策系统应运而生;
2、如何获得互联网信息数据切分的词语的活跃值,根据所获得的互联网信息数据切分的词语的活跃值进行智能决策,从而提高互联网信息数据推送的可靠性,是我们需要解决的问题,为此,现提供一种基于人工智能的互联网信息智能决策系统。
技术实现思路
1、为了解决上述技术问题,本发明的目的在于提供一种基于人工智能的互联网信息智能决策系统。
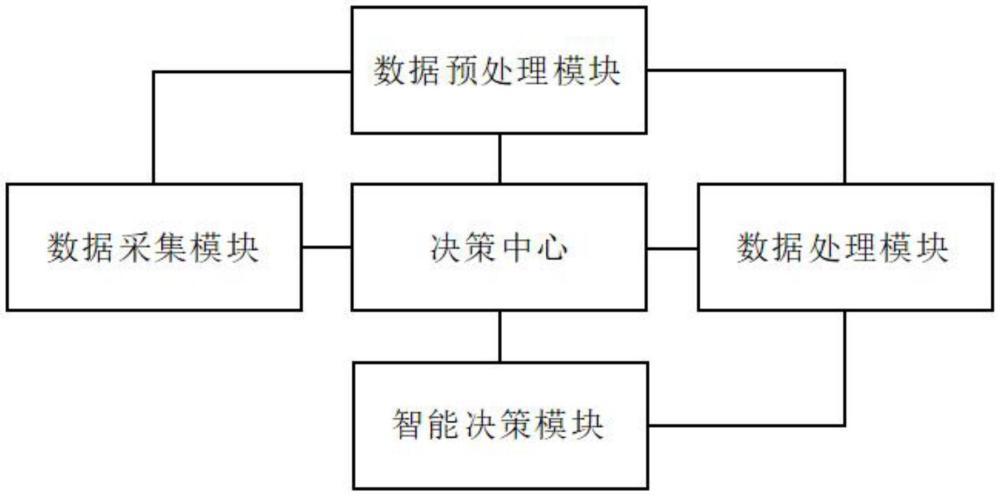
2、本发明的目的可以通过以下技术方案实现:一种基于人工智能的互联网信息智能决策系统,包括决策中心,所述决策中心通信连接有数据采集模块、数据预处理模块、数据处理模块以及智能决策模块;
3、所述数据采集模块用于对待推送的互联网信息数据进行采集;
4、所述数据预处理模块用于对所采集的待推送的互联网信息数据进行预处理,获得互联网信息数据切分的词语;
5、所述数据处理模块用于对所获得的互联网信息数据切分的词语进行处理,获得互联网信息数据切分的词语的活跃值;
6、所述智能决策模块用于根据所获得的互联网信息数据切分的词语的活跃值进行智能决策。
7、进一步的,所述数据采集模块对待推送的互联网信息数据进行采集的过程包括:
8、所述数据采集模块由若干个互联网信息数据采集终端构成,所述互联网信息数据采集终端用于采集待推送给用户的互联网信息数据;
9、对每个互联网信息数据采集终端进行配置,并生成对应的配置通道,通过所生成的配置通道,链接对应的服务器,互联网信息数据采集终端通过配置通道,获取对应服务器内的待推送的互联网信息数据。
10、进一步的,所述数据预处理模块对所采集的待推送的互联网信息数据进行预处理的过程包括:
11、所述预处理模块中设置有词语数据库,所述词语数据库中存储有若干个词语;
12、获取词语数据库中存储的最长词语的长度,将所获取的词语数据库中存储的最长词语的长度记为l;
13、通过人工智能技术对互联网信息数据进行一级分词预处理,获得一级分词预处理的结果,所述一级分词预处理的结果包括若干个词语;
14、通过人工智能技术对互联网信息数据进行二级分词预处理,获得二级分词预处理的结果,所述二级分词预处理的结果包括若干个词语;
15、将一级分词预处理获得的词语数量与二级分词预处理获得的词语数量进行比较,若比较结果相同,则将一级分词预处理获得的词语作为互联网信息数据切分的词语;
16、若比较结果不同,则将一级分词预处理获得的词语和二级分词预处理获得的词语进行混合,将混合后的词语作为互联网信息数据切分的词语。
17、进一步的,通过人工智能技术对互联网信息数据进行一级分词预处理的过程包括:
18、设定一级最大匹配长度,将一级最大单词长度设定为l;
19、从互联网信息数据的第一个字符开始,获取前l个字符,将所获取的l个字符作为待匹配字符片段;
20、获取前l个字符组成的待匹配字符片段切分的词语;
21、获取第(l+1)至2l个字符组成的字符片段,将所获取的第(l+1)至2l个字符组成的字符片段作为待匹配字符片段,获取第(l+1)至2l个字符组成的待匹配字符片段切分的词语,获取第(2l+1)至3l个字符组成的字符片段,将所获取的第(2l+1)至3l个字符组成的字符片段作为待匹配字符片段,获取第(2l+1)至3l个字符组成的待匹配字符片段切分的词语,以此类推,获取互联网信息数据剩余字符组成的字符片段切分的词语。
22、进一步的,获取前l个字符组成的待匹配字符片段切分的词语的过程包括:
23、将前l个字符组成的待匹配字符片段与词语数据库中存储的词语进行匹配,若词语数据库中存在与待匹配字符片段相同的词语,则将待匹配字符片段作为一个词语从互联网信息数据中切分出来,若词语数据库中不存在与待匹配字符片段相同的词语,则将待匹配字符片段的前(l-1)个字符与词语数据库中存储的词语进行匹配;
24、若词语数据库中存在与待匹配字符片段的前(l-1)个字符相同的词语,则将待匹配字符片段的前(l-1)个字符作为一个词语从互联网信息数据中切分出来,并将切分后剩余的待匹配字符片段与词语数据库中存储的词语进行匹配,若词语数据库中存在与切分后剩余的待匹配字符片段相同的词语,则将切分后剩余的待匹配字符片段作为一个词语从互联网信息数据中切分出来,若词语数据库中不存在与待匹配字符片段相同的词语,则保留切分后剩余的待匹配字符片段;
25、若词语数据库中不存在与待匹配字符片段的前(l-1)个字符相同的词语,则将待匹配字符片段中剩余未匹配的字符与词语数据库中存储的词语进行匹配;
26、若词语数据库中存在与待匹配字符片段中剩余未匹配的字符相同的词语,则将待匹配字符片段中剩余未匹配的字符作为一个词语从互联网信息数据中切分出来,若词语数据库中不存在与待匹配字符片段中剩余未匹配的字符相同的词语,则保留待匹配字符片段中剩余未匹配的字符,并将待匹配字符片段的前(l-2)个字符与词语数据库中存储的词语进行匹配,以此类推,……,直至将待匹配字符片段的第一个字符与词语数据库中存储的词语进行匹配,或词语数据库中存在与待匹配字符片段的前l个或前(l-1)个或前(l-2)个或前(l-3)个或前(l-4)个或……或前两个字符相同的词语,获得前l个字符组成的待匹配字符片段切分的词语。
27、进一步的,通过人工智能技术对互联网信息数据进行二级分词预处理的过程包括:
28、设定二级最大匹配长度,将二级最大单词长度设定为l,即二级最大单词长度和词语数据库中存储的最长词语的长度相同;
29、从互联网信息数据的最后一个字符开始,获取后l个字符,将所获取的后l个字符作为待匹配字符片段,获取后l个字符组成的待匹配字符片段切分的词语;
30、获取后(l+1)至2l个字符组成的字符片段,将所获取的后(l+1)至2l个字符组成的字符片段作为待匹配字符片段,获取后(l+1)至2l个字符组成的待匹配字符片段切分的词语,以此类推,获取互联网信息数据剩余字符组成的字符片段切分的词语。
31、进一步的,所述数据处理模块对所获得的互联网信息数据切分的词语进行处理的过程包括:
32、获取互联网信息数据切分的词语的出现频次,根据所获取的互联网信息数据切分的词语的出现频次获得互联网信息数据切分的词语的活跃值;
33、对所获得的互联网信息数据切分的词语的活跃值从大到小进行排序,获取前k个活跃值对应的互联网信息数据切分的词语,k为不为零的正偶数,将所获取的前k个活跃值对应的互联网信息数据切分的词语记为参考词语。
34、进一步的,所述智能决策模块根据所获得的互联网信息数据切分的词语的活跃值进行智能决策的过程包括:
35、获取用户正在浏览的互联网信息数据,并获取用户正在浏览的互联网信息数据切分的词语的活跃值,对所获取的用户正在浏览的互联网信息数据切分的词语的活跃值从大到小进行排序,获取前k个活跃值对应的用户正在浏览的互联网信息数据切分的词语,将所获取的前k个活跃值对应的用户正在浏览的互联网信息数据切分的词语记为标准词语;
36、将所获取的标准词语与参考词语进行比较,若存在k/2及以上个参考词语与标准词语相同,则将待推送的互联网信息数据推送给用户,若不存在k/2及以上个参考词语与标准词语相同,则禁止将待推送的互联网信息数据推送给用户。
37、与现有技术相比,本发明的有益效果是:对待推送的互联网信息数据进行采集,对所采集的待推送的互联网信息数据进行预处理,获得互联网信息数据切分的词语,对所获得的互联网信息数据切分的词语进行处理,获得互联网信息数据切分的词语的活跃值,根据所获得的互联网信息数据切分的词语的活跃值进行智能决策,根据用户的兴趣进行推送,从而提高了互联网信息数据推送的可靠性。
- 还没有人留言评论。精彩留言会获得点赞!