一种文本驱动的数字人高精度音唇同步系统及方法与流程
本发明涉及计算机信息处理,更具体的说是涉及一种文本驱动的数字人高精度音唇同步系统及方法。
背景技术:
1、数字人是指以数字形式存在于数字空间中,具有拟人或真人的外貌、行为和特点的虚拟人物,涉及到建模、物理仿真、渲染、动作捕捉、面部捕捉和人工智能等多种技术。随着人工智能技术和计算机技术的不断完善,数字人的应用和需求不断增长,已经在元宇宙、直播、综艺、游戏、金融、传媒、文旅、科教、泛娱乐、康养等诸多领域有了大范围的落地应用,具体呈现形式包括虚拟主持人、虚拟主播、时装秀模特、虚拟偶像、虚拟教师、短视频虚拟形象等。
2、数字人可以降低人类的重复性劳动,保持24小时不间断在线,大大提高所在行业的生产效率。高质量数字人与真人类似,需要做到“形神兼备”。“形”指的是具有非常逼真的头发、皮肤等外观视觉效果,“神”指的是具有生动灵活的动作、表情、唇形动画细节。
3、随着渲染技术的进步,数字人的外观已经可以实现非常逼真的效果,例如unreal,unity,adobe等公司都推出了自己的数字人渲染系统,可以实现次世代的高精度渲染。但是很多数字人只是形似而神不似,不够生动灵活,比较呆板,没有丰富的表情、动作和唇形动画,并且有的时候唇形动画和声音难以做到精确匹配,这会导致数字人仿佛一具没有灵魂的精致模型,降低数字人的体验感,极大影响了数字人的推广,有时候甚至会带来“恐怖谷效应”。
4、只有具备拟人化的思想和行为,具备生动灵活的动画细节,数字人才能给用户带来亲切感、参与感、互动感和沉浸感。数字人要想做到与真人神似需要至少做到:肢体动作自然流畅、面部表情自然、音唇同步。
5、相关技术中:
6、1、随机唇动,这是最简单的唇动方案。这些方法随机播放唇动动画,以此产生似乎在说话的感觉,但是这种随机播放精度很低,大大降低了数字人的观感和真实度。只适合模型很粗糙或者某些2d图片场景。
7、2、音频驱动唇动技术,例如wav2lip、lipsync等技术,这些技术需要输入音频,比输入文本来说代价更高;由于缺乏精确的音素信息,常见的音频驱动唇动方法在处理动态和无约束的说话情况下,通常无法准确合成口型,导致生成的唇形动画与音频不同步,精度比较差,从而让用户产生不真实的感觉和割裂感。
8、3、视频驱动技术,例如苹果的面捕技术。基于面捕的方法在精确度上可以实现比较准确的效果,但是有两个巨大缺点使其目前难以大规模应用:
9、1)每次都需要真人在专业设备前进行录制,需要消耗较大的人力,不适合快速高效部署和日常使用。
10、2)设备相对昂贵,需要比较好的面捕硬件支持,一般用户不会愿意购买,操作成本也比较高。
11、因此,上述缺陷限制了数字人技术在提升用户参与感、互动感和沉浸感方面的能力,尤其是在需要高度拟真的场景中,现有技术手段难以全面满足市场需求。
技术实现思路
1、有鉴于此,本发明提供了一种文本驱动的数字人高精度音唇同步系统及方法,本发明致力于解决数字人的音唇同步问题,改善现有数字人唇形动画不准确、音频不自然、细节不丰富以及音唇不同步的问题。
2、为了实现上述目的,本发明采用如下技术方案:
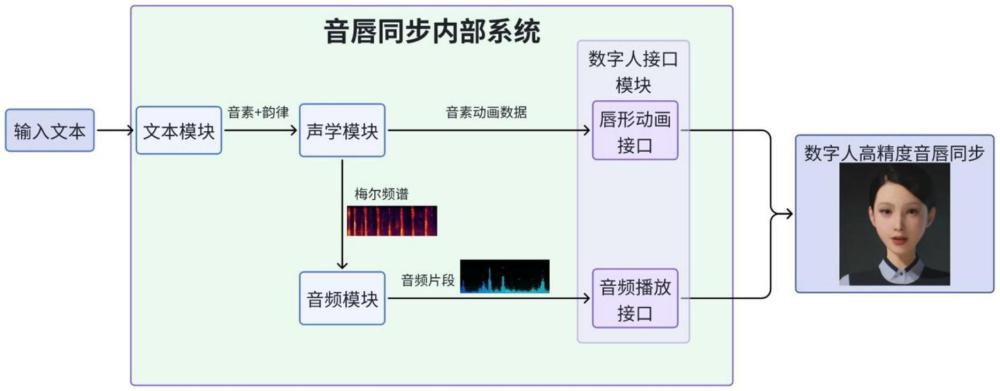
3、第一方面,本发明提供一种文本驱动的数字人高精度音唇同步系统,包括:
4、文本模块,用于将输入的文本转化为语言学特征,包括音素和韵律;
5、声学模块,用于将所述语言学特征转化为声学特征和音素动画数据;
6、音频模块,用于将所述声学特征采样生成音频片段;
7、数字人接口模块,用于接收所述音素动画数据和音频片段并同步播放,以实现数字人音唇同步。
8、进一步地,所述文本模块,包括:
9、文本规范化单元,用于将输入的文本作为书面文本词转换成口语词;
10、生成音素单元,用于对所述口语词利用bert模型和softmax分类器实现多音字的消歧处理,生成对应的音素;
11、韵律预测单元,用于对所述口语词基于bert模型和softmax分类器进行韵律分析,输出对应的韵律等级。
12、进一步地,所述声学模块,包括:
13、向量化单元,用于将文本模块生成的音素和韵律信息通过嵌入技术转化为嵌入向量形式;
14、编码器单元,使用前馈transformer块来分析和理解音素及其关联的韵律特征,提取音素和韵律信息的上下文语义关联;
15、语音转换器单元,用于提取与音素相关的语音特征,包括:音调、能量和权重、时间信息和频谱级序列;
16、自回归解码器单元,采用依次相连的prenet、gru模块以及全连接层结构,根据输入的频谱级序列,生成最终的梅尔频谱,用于音频合成。
17、进一步地,所述编码器单元,由4个前馈transformer块组成,输入是304维度的嵌入向量,并加入位置编码,经过编码器内部网络结构变成隐状态序列;所述transformer结构包括多头自注意力层以及一维卷积,提取到音素和韵律的上下文语义关联。
18、进一步地,所述位置编码用于向模型提供序列中各个音素位置信息,使用正弦和余弦函数的固定位置编码:
19、对于音素序列位置pos处的第2i维度,为偶数维度:
20、
21、对于音素序列中位置pos处的第2i+1维度,为奇数维度:
22、
23、其中,pos是位置索引,i是维度索引,dmodel是模型隐藏层的维度。
24、进一步地,所述语音转换器单元,包括:
25、特征提取器,用于从编码器单元输出的隐状态序列中,基于预训练的循环神经网络模型提取声学特征;
26、音调预测器,用于基于预训练的音调预测模型,从所述声学特征中获得音调信息;
27、能量预测器,用于基于预训练的能量预测模型,从所述声学特征中获得能量信息;
28、权重预测器,用于基于预训练的权重预测模型,从所述声学特征中获得权重信息;
29、自回归长度预测器,将预测获得的音调、能量、权重信息和编码器单元提取的音律、韵律一起编码拼接,输入预训练的自回归长度预测模型,输出音素的时间信息,以及所述时间信息经过长度调节器,输出频谱级序列。
30、进一步地,所述音调预测模型、能量预测模型和权重预测模型,为相同的网络模型结构,均由两个卷积层和一个全连接层组成,分别单独建模,均采用均方误差损失进行优化;
31、其中,所述音调预测模型使用连续小波变换将连续音调序列分解为音调谱图,并将音调谱图作为训练目标;
32、所述能量预测模型,将计算每个短时傅里叶变化帧的幅度的l2范数作为能量;所述能量作为训练目标;
33、所述权重预测模型直接将音素对应发音的动画权重作为训练目标。
34、进一步地,所述音频模块具体采用hifi-gan网络,对作为声学特征的梅尔频谱进行上采样以生成高质量音频;所述hifi-gan网络使用对抗损失、梅尔频谱损失和特征匹配损失,进行训练。
35、进一步地,所述数字人接口模块,包括:
36、唇形动画接口层,用于接收声学模块生成的音素权重和时间信息,并将其转化为对应的唇形动画;
37、音频播放接口层,用于接收音频模块生成的音频,并将所述音频与唇形动画同步播放。
38、第二方面,本发明实施例还提供一种文本驱动的数字人高精度音唇同步方法,使用如第一方面任一项所述的文本驱动的数字人高精度音唇同步系统,包括如下步骤:
39、获取输入文本并通过文本模块转化为语言学特征,包括音素和韵律;
40、将文本模块输出的语言学特征通过声学模块转化为声学特征和音素动画数据;
41、利用音频模块采样声学特征生成对应的音频片段;
42、将音素动画数据和音频片段同步输入数字人接口模块,实现数字人音唇同步。
43、经由上述的技术方案可知,与现有技术相比,本发明具有如下技术优势:
44、1.创新性与实用性兼具:本发明创新性地提出了一种文本驱动的数字人高精度音唇同步系统,可以同时生成高质量音频和音唇动画数据,极大提高数字人的语音交互流畅度、自然感和真实度,改善现有数字人唇形动画不准确、音频不自然、细节不丰富以及音唇不同步的问题,提升用户体验。
45、2.现有方案的唇形动画大多基于英文音素设计,难以完美覆盖中文场景,本发明基于《汉语拼音方案》标准,创新性地引入中文声母和韵母的音素来进行学习和驱动,做到唇形动画100%覆盖中文发音场景,实现中文场景下极高的音唇精度。
46、3.易于使用,降低生成的成本,提高生成效率。本发明不需要输入音频、佩戴复杂面捕设备等,仅需要输入文本即可生成高精度的音唇同步,本发明系统内部会自动生成音唇同步需要的音频数据和动画数据。
47、4.系统性的学习框架:本发明利用神经网络从文本生成音频和音素动画数据的统一模型,可以保证声音频谱和动画数据的同步学习,精度更高;音素的音调、能量和权重可以对音素长度的学习和预测起到更好的信息补充,得到更优的时间预测信息。这些都会让最终音唇同步的结果更加准确。
48、5.可重复性和可优化性:本发明设计可以不断输入新的训练资料来强化已有模型,不断优化效果;模块化设计使得后续每个模块都可以替换成更优的组件结构,进一步改善效果。
- 还没有人留言评论。精彩留言会获得点赞!