一种数字人口唇和肢体实时协同的方法、装置、设备及存储介质与流程
本发明涉及实时协同领域,尤其涉及一种数字人口唇和肢体实时协同的方法、装置、设备及存储介质。
背景技术:
1、随着科技的发展,2d数字人技术涵盖了计算机图形学、人工智能、计算机视觉、虚拟现实和增强现实以及用户界面设计和交互设计等多个领域的知识和技术。这些技术的融合与应用,使得2d数字人在文博领域具备了更加逼真、互动性强的特点,为用户提供了更加丰富和沉浸式的体验。
2、目前,在文博领域,同类2d数字人中都只是口唇的同步动作,数字人的肢体动作如手部、肩膀等等没有和问答的内容同步,无法根据具体的问答内容做出相对于的肢体动作,缺乏灵活性和互动感,体验感单一。
3、因此,怎样让2d数字人的肢体动作与问答的内容同步,是一个亟需解决的问题。
技术实现思路
1、本发明提供了一种数字人口唇和肢体实时协同的方法、装置、设备及存储介质,能让数字人的肢体动作与问答的内容同步。
2、本发明一实施例提供一种数字人口唇和肢体实时协同的方法,包括:
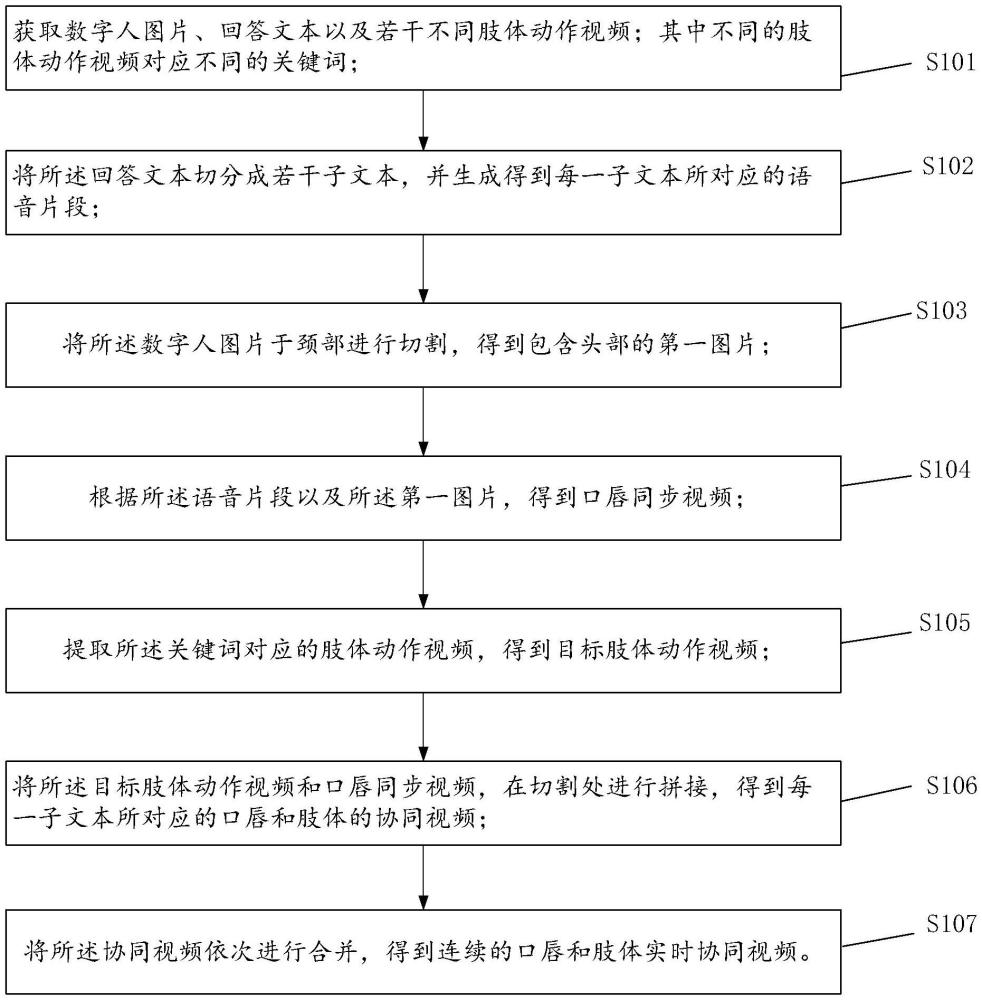
3、获取数字人图片、回答文本以及若干不同肢体动作视频;其中不同的肢体动作视频对应不同的关键词;
4、将上述回答文本切分成若干子文本,并生成得到每一子文本所对应的语音片段;
5、将上述数字人图片于颈部进行切割,得到包含头部的第一图片;
6、根据上述语音片段以及上述第一图片,得到口唇同步视频;
7、提取上述关键词对应的肢体动作视频,得到目标肢体动作视频;
8、将上述目标肢体动作视频和口唇同步视频,在切割处进行拼接,得到每一子文本所对应的口唇和肢体的协同视频;
9、将上述协同视频依次进行合并,得到连续的口唇和肢体实时协同视频。
10、进一步的,上述将上述回答文本切分成若干子文本,包括:
11、识别上述回答文本中的所有标点符号;
12、根据上述标点符号,将上述回答文本切分成若干子文本。
13、进一步的,上述根据上述标点符号,将上述回答文本切分成若干子文本,包括:
14、将上述所有标点符号转化为正则表达式;
15、使用上述正则表达式对上述回答文本进行切分,并移除空字符串,得到上述若干子文本。
16、进一步的,上述将上述数字人图片于颈部进行切割,得到包含头部的第一图片,包括:
17、将上述数字人图片输入预设的颈部识别模型中,以使上述颈部识别模型识别出上述数字人图片中人物对象的颈部区域;
18、根据所识别的颈部区域,对上述数字人图片进行切割,得到包含头部的第一图片;
19、其中,上述颈部识别模型的构建包括:
20、获取若干数字人图片样本,并对每一若干数字人图片样本的颈部区域进行标记,得到若干训练样本;
21、以各训练样本为输入,以各训练样本所对应的颈部预测区域为输出对神经网络模型进行迭代训练,直至神经网络模型收敛,将收敛的神经网络模型作为上述颈部识别模型;其中,在每次迭代训练过程中,将颈部预测区域与训练样本所对应的真实的颈部区域进行比对,根据比对结果计算损失函数值,根据损失函数值对神经网络模型的参数进行调整。
22、在上述方法项实施例的基础上,本发明对应提供了装置项实施例;
23、本发明提供了一种数字人口唇和肢体实时协同的装置,包括:
24、媒体内容获取模块、文本切分模块、图片切割模块、视频合成模块、目标视频提取模块、视频拼接模块以及视频合并模块;
25、上述媒体内容获取模块,用于获取数字人图片、回答文本以及若干不同肢体动作视频;其中不同的肢体动作视频对应不同的关键词;
26、上述文本切分模块,用于将上述回答文本切分成若干子文本,并生成得到每一子文本所对应的语音片段;
27、上述图片切割模块,用于将上述数字人图片于颈部进行切割,得到包含头部的第一图片;
28、上述视频合成模块,用于根据上述语音片段以及上述第一图片,得到口唇同步视频;
29、上述目标视频提取模块,用于提取上述关键词对应的肢体动作视频,得到目标肢体动作视频;
30、上述视频拼接模块,用于将上述目标肢体动作视频和口唇同步视频,在切割处进行拼接,得到每一子文本所对应的口唇和肢体的协同视频;
31、上述视频合并模块,用于将上述协同视频依次进行合并,得到连续的口唇和肢体实时协同视频。
32、进一步的,上述文本切分模块,包括:标点符号识别子模块以及子文本生成子模块;
33、上述标点符号识别子模块,用于识别上述回答文本中的所有标点符号;
34、上述子文本生成子模块,用于根据上述标点符号,将上述回答文本切分成若干子文本。
35、进一步的,上述子文本生成子模块,包括:正则表达式生成单元以及文本切分单元;
36、上述正则表达式生成单元,用于将上述所有标点符号转化为正则表达式;
37、上述文本切分单元,用于使用上述正则表达式对上述回答文本进行切分,并移除空字符串,得到上述若干子文本。
38、进一步的,上述图片切割模块,包括:模型识别单元以及图片切割单元;
39、上述模型识别单元,用于将上述数字人图片输入预设的颈部识别模型中,以使上述颈部识别模型识别出上述数字人图片中人物对象的颈部区域;
40、上述图片切割单元,用于根据所识别的颈部区域,对上述数字人图片进行切割,得到包含头部的第一图片。
41、在上述方法项实施例的基础上,本发明对应提供了一终端设备项实施例;
42、本发明提供了一种终端设备,包括处理器、存储器以及存储在上述存储器中且被配置为由上述处理器执行的计算机程序,上述处理器执行上述计算机程序时实现本发明任意一实施例所述的一种数字人口唇和肢体实时协同的方法。
43、在上述方法项实施例的基础上,本发明对应提供了一存储介质项实施例;
44、本发明提供了一种存储介质,包括处理器、存储器以及存储在上述存储器中且被配置为由上述处理器执行的计算机程序,上述处理器执行上述计算机程序时实现本发明任意一实施例所述的一种数字人口唇和肢体实时协同的方法。
45、本发明的实施例,具有如下有益效果:
46、本发明提供了一种数字人口唇和肢体实时协同的方法、装置、终端设备及存储介质。上述方法,首先获取数字人图片、回答文本以及若干不同肢体动作视频;其中不同的肢体动作视频对应不同的关键词;随后将上述回答文本切分成若干子文本,并生成得到每一子文本所对应的语音片段;然后将上述数字人图片于颈部进行切割,得到包含头部的第一图片;再根据上述语音片段以及上述第一图片,得到口唇同步视频;随后提取上述关键词对应的肢体动作视频,得到目标肢体动作视频;再将上述目标肢体动作视频和口唇同步视频,在切割处进行拼接,得到每一子文本所对应的口唇和肢体的协同视频;最后将上述协同视频依次进行合并,得到连续的口唇和肢体实时协同视频。因此本发明通过将回答文本切割成若干条小文本,随后依次对每一条小文本进行处理,得到每一条小文本对应的语音片段以及每一条语音片段对应的口唇同步视频,再通过识别小文本中的关键词,将每一个关键词对应的肢体动作视频与口唇同步视频进行拼接,实现2d数字人的肢体动作与问答的内容同步的效果。
- 还没有人留言评论。精彩留言会获得点赞!