一种基于神经网络的高填方路基沉降预测方法
本发明涉及土木工程建设运维,具体涉及一种基于神经网络的高填方路基沉降预测方法。
背景技术:
1、在我国社会经济不断发展的背景下,铁路行业的发展也正步入一个新的阶段,高速铁路建造技术以不断提高运行速度作为发展目标之一,对路基稳定性提出了严苛的要求,路基工后沉降直接影响着列车运营的安全性、稳定性以及使用年限。相较于一般路基,高填方路基因自身填筑高度大且自重大,加之外部列车荷载作用,更易产生沉降变形。这些特点使得高填方路基有更高的填筑质量要求和更严格的沉降控制要求,如何合理利用观测数据,准确可靠的预测高填方路基沉降变形成为工程研究热点之一。
2、高速铁路路基沉降预测包括传统预测方法、数值分析预测方法以及基于实测数据的沉降预测方法三大类。传统预测方法和数值分析预测方法在面对路基沉降数据“沉降变形小和数据波动大”的特点时,难以考虑土体压缩、土体固结和模型参数确定等问题,相比之下基于实测数据的沉降预测方法在实践中更具优势,基于实测数据的沉降预测方法包括双曲线法、三点法、指数曲线法和灰色系统等。随着计算机技术的发展,人工智能技术为解决路基沉降预测问题带来了新思路,机器学习算法被应用于路基沉降预测当中,多采用循环神经网络模型及其变体网络模型。传统的机器学习方法在预测路基沉降时采用数据驱动,借助实测数据进行训练学习并给出预测结果,这种纯数据驱动的预测方法对训练样本需求量较大,观测偏差导致模型泛化能力差。因此,融合物理信息和数据信息的双驱动神经网络被提出,考虑内在物理机理,弥补了纯数据驱动神经网络中预测结果与实际物理力学模型规律契合度不高的缺陷。物理信息双驱动神经网络在时序数据预测任务实现中,能够将高填方路基沉降变形与填筑高度映射关系嵌入损失函数,有助于确保预测结果符合路基沉降发展物理过程,并且在一定程度上泛化未见过的数据,对于时序数据长期预测尤为重要。但传统的物理数据双驱动神经网络在时序预测任务中,在对时序数据时间依赖性处理时表现较差,导致监测数据时序特征捕捉不佳,影响路基沉降预测的可靠度和精准度。
技术实现思路
1、本发明为了解决以上问题,提出了一种基于神经网络的高填方路基沉降预测方法。
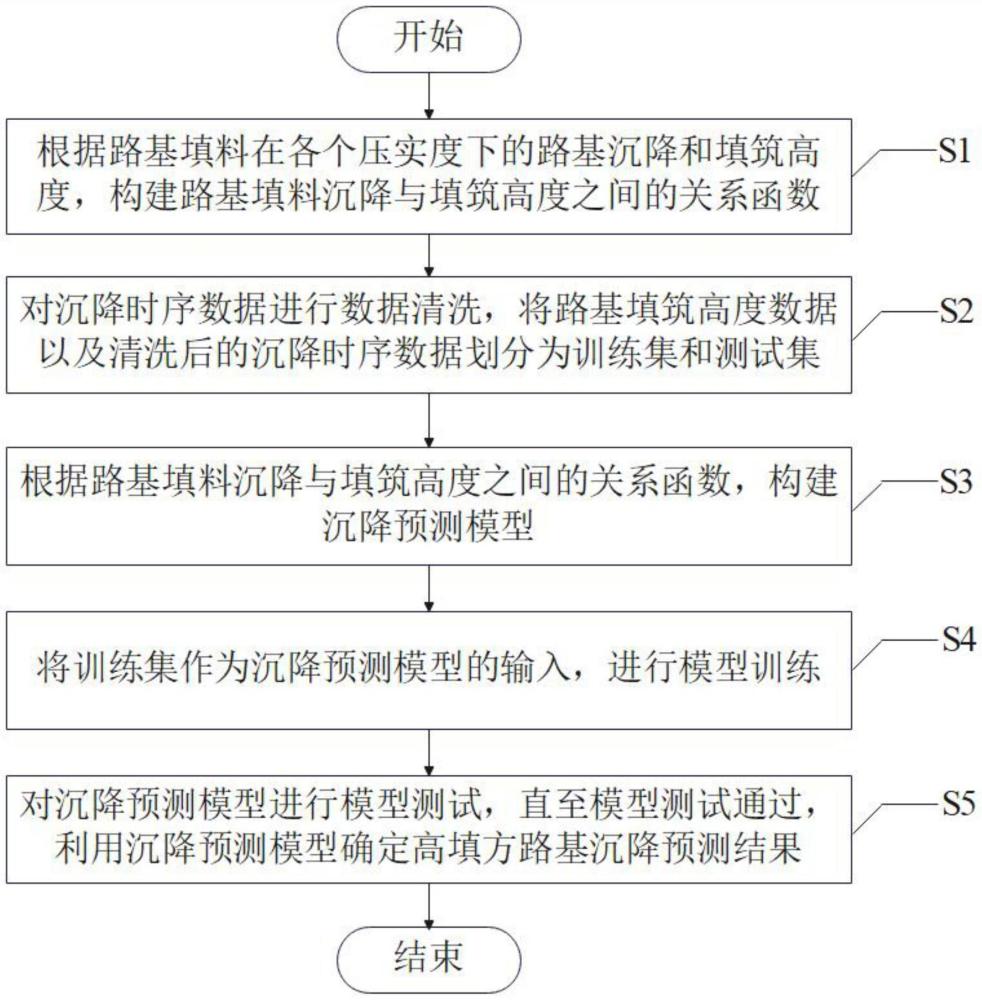
2、本发明的技术方案是:一种基于神经网络的高填方路基沉降预测方法包括以下步骤:
3、s1、根据路基填料在各个压实度下的路基沉降和填筑高度,构建路基填料沉降与填筑高度之间的关系函数;
4、s2、采集待预测工程现场的路基填筑高度数据和沉降时序数据,并对沉降时序数据进行数据清洗,将路基填筑高度数据以及清洗后的沉降时序数据划分为训练集和测试集;
5、s3、根据路基填料沉降与填筑高度之间的关系函数,构建沉降预测模型;
6、s4、将训练集作为沉降预测模型的输入,进行模型训练;
7、s5、利用测试集对训练完成的沉降预测模型进行模型测试,直至模型测试通过,并利用测试通过的沉降预测模型确定待预测工程现场的高填方路基沉降预测结果。
8、进一步地,s1中,路基填料沉降与填筑高度之间的关系函数f(ξ,h)的表达式为:f(ξ,h)=ue-h/t+ξi;式中,ξi表示第一系数,u表示第二系数,t表示第三系数,h表示填筑高度,e表示指数。
9、进一步地,s2包括以下子步骤:
10、s21、采集待预测工程现场的路基填筑高度数据和沉降时序数据;
11、s22、对沉降时序数据依次进行奇异值检验、缺失值插补、数据降噪处理以及数据标准化处理;
12、s23、将路基填筑高度数据以及清洗后的沉降时序数据划分为训练集和测试集。
13、进一步地,s22中,进行数据降噪处理的计算公式为:
14、s(t)=sd(t)+sk(t);
15、式中,s(t)表示进行数据降噪处理后的沉降时序数据,sd(t)表示实际变形信号,sk(t)表示确定性噪声。
16、进一步地,沉降预测模型包括输入层、第一1d卷积层、第一relu激活层、第一因果卷积层、第二relu激活层、第二1d卷积层、第三relu激活层、第二因果卷积层、第四relu激活层、线性层以及输出层;
17、输入层的输入端作为沉降预测模型的输入端;输入层的输出端、第一1d卷积层以及第一relu激活层的输入端依次连接;第一relu激活层的第一输出端、第一因果卷积层以及第二relu激活层的输入端依次连接;第一relu激活层的第二输出端和第二relu激活层的第一输出端均与第二1d卷积层的输入端连接;第二1d卷积层的输出端和第三relu激活层的输入端连接;第二relu激活层的第二输出端和第三relu激活层的第一输出端均与第二因果卷积层的输入端连接;第二因果卷积层的输出端和第四reluc激活层的输入端连接;第三relu激活层的第二输出端和第四relu激活层的输出端均与线性层的输入端连接;线性层的输出端和输出层的输入端连接;输出层的输出端作为沉降预测模型的输出端。
18、进一步地,输入层和输出层之间的表达式为:
19、y=n(x;θ);
20、式中,θ=[w,b],x表示沉降预测模型的输入变量,y表示沉降预测模型的输出变量,θ表示沉降预测模型的待识别参数,n(·)表示待识别参数的神经网络算子,w表示不同网络层之间的权重,b表示神经网络的偏置。
21、进一步地,沉降预测模型损失函数loss_g的表达式为:
22、loss_g=λ1loss_gu+λ2loss_gf;
23、
24、式中,loss_gu表示数据驱动项,loss_gf表示物理方程残差项,λ1表示第一权重系数,λ2表示第二权重系数,n表示样本总数,s'i表示观测数据,表示网络预测值,hi表示路基的填筑高度,f(ξ,h)表示路基填料沉降与填筑高度之间的关系函数。
25、进一步地,沉降预测模型损失函数中第一权重系数和第二权重系数的确定方法为:构建自适应优化函数,并将当前第一权重系数和当前第二权重系数输入至自适应优化函数,若自适应优化函数值大于0.05,则增大当前第一权重系数或当前第二权重系数,直至自适应优化函数值小于或等于0.05,否则采用当前第一权重系数和当前第二权重系数。
26、进一步地,自适应优化函数a的表达式为:
27、且λ1+λ2=1;
28、式中,loss_gu表示数据驱动项,loss_gf表示物理方程残差项,λ1表示第一权重系数,λ2表示第二权重系数,max(·)表示最大值函数,min(·)表示最小值函数。
29、本发明的有益效果是:本发明区别于以往的路基沉降预测模型,考虑高填方路基填料荷载作用下力学特征演化,通过试验拟合获得路基填料的物理力学模型,以数据信息作为沉降预测模型驱动,以物理信息控制方程作为沉降预测模型约束,构建了沉降预测模型,降低了沉降预测模型对于训练数据量的过度依赖,降低了数据收集成本;有效修正沉降预测模型在路基沉降预测中的偏差,提高了沉降预测模型的预测精度,使得模型预测结果符合路基结构物理力学变化规律。本发明对原始物理信息神经网络进行改进,采用1d卷积与因果卷积交错排列的网络结构,有效提取监测数据时序特征,保证其时间因果性。同时,本发明为铁路高填方路基沉降预测提供新思路,对于铁路路基运维与不均匀沉降病害防治具有一定意义。
- 还没有人留言评论。精彩留言会获得点赞!