一种基于全局规划的异构算力统一调度方法和系统与流程
本发明涉及算力管理和智能调度领域,具体涉及一种基于全局规划的异构算力统一调度方法和系统。
背景技术:
1、随着aigc和数字智能的不断发展,计算需求和算力规模日益增加,传统的cpu算力已不能适配和满足大多算力应用场景。此时,各大硬件厂商纷纷推出各种异构算力设备,如gpu、npu、fpga等,以满足不同场景的用户使用。各种异构算力被逐渐用于普通模型和大模型的训练、微调、推理等多样化场景,根据对资源的使用方式不同,又可将算力资源分为资源隔离和资源共享两种使用方式,其中资源隔离包括整卡隔离和部分隔离,资源共享指整卡共享。
2、现有技术中,异构算力设备的管理和调度面临诸多挑战。首先,异构算力设备种类繁多,性能参数各异,导致对其进行统一管理和调度变得极为复杂。其次,多租户环境中,差异化的算力需求需要确保每个租户都能获得所需的算力资源,同时还要保证系统的整体稳定性和资源的高效利用。然而,现有的调度方法往往不能兼顾不同类型算力设备的高效利用,导致资源利用率低下,甚至出现资源浪费的情况。此外,现有技术在处理算力需求的实时变化和资源分配时,缺乏灵活性和智能化手段,容易导致系统性能瓶颈和算力分配不均。
3、这些问题的后果是显而易见的。首先,资源利用率低下和资源浪费直接增加了计算成本,降低了系统的经济效益。其次,算力分配不均和系统性能瓶颈会导致算力应用的运行不稳定,影响用户体验,甚至可能导致关键任务的失败。最后,复杂的管理和高昂的管理成本给运维人员带来了巨大压力,降低了系统的可维护性和可扩展性。
4、因此,亟需提出一种有效的异构算力统一调度方法,以解决现有技术中存在的问题,提高异构算力资源的利用率和生产力,保障各种算力应用的平稳运行。
技术实现思路
1、为克服现有技术的不足,本发明提出一种基于全局规划的异构算力统一调度方法和系统,通过简单定义全局算力规划,即可划分出隔离资源、共享资源和算力池,构建逻辑严密的统一调度过程,加之多维度的异构算力资源监控能力,实现异构算力的统筹有序和合理分配,极大提高异构算力资源的利用率和生产力。
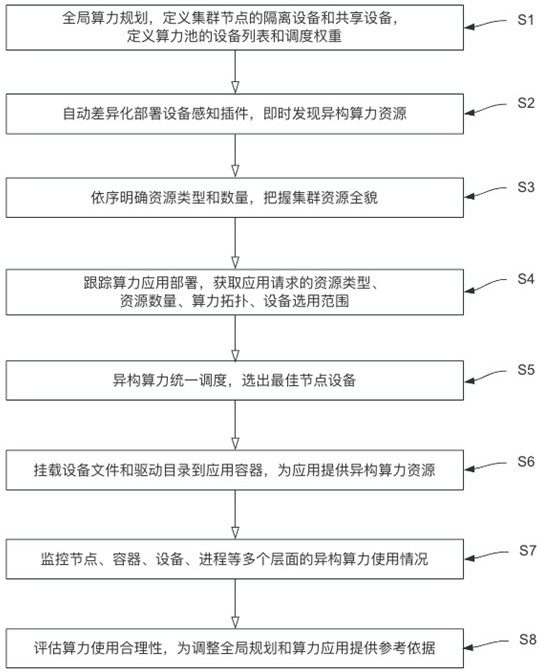
2、为实现上述目的,本发明提供一种基于全局规划的异构算力统一调度方法,包括:
3、步骤1:获取异构算力设备信息,所述设备信息包括设备类型、性能参数和当前状态;
4、步骤2:建立全局算力规划模型,利用优化算法对算力池进行规划,定义设备列表及其调度权重;
5、步骤3:动态监控和识别设备状态,通过机器学习算法对集群节点的硬件进行标签化处理,实现对异构算力资源的实时监控和发现;
6、步骤4:应用状态跟踪和资源调度,实时获取和分析应用请求的资源类型、数量、拓扑结构和设备选择范围;
7、步骤5:优化节点和设备选择,综合考虑节点的资源利用率、网络延迟和能效等因素,筛选出最优计算节点和设备;
8、步骤6:挂载设备文件和驱动目录,将选定设备的文件和驱动目录挂载到应用容器中;
9、步骤7:多维度算力使用监控,采用多维度监控工具实时获取节点、容器、算力设备和应用进程等多个层面的使用情况;
10、步骤8:算力使用合理性评估和异常处理,利用深度学习算法评估异构算力资源的使用合理性,并在出现异常时记录并分析异常数据,发送提示信息,制定修复方案。
11、进一步地,步骤1包括:
12、获取多个集群节点的隔离设备和共享设备信息,所述设备信息包括设备类型、性能参数和当前状态;
13、利用机器学习算法对节点硬件进行标签化处理,以识别不同类型的异构算力设备。
14、步骤2包括:
15、利用优化算法对算力池进行规划;
16、定义设备列表及其调度权重,确保资源的合理分配;
17、基于全局规划模型和实时采集的设备数据,应用资源序列补缺算法,生成详细的资源图谱,包括设备数量、类型和容量等信息。
18、进一步地,步骤3包括:
19、通过机器学习算法对集群节点的硬件进行标签化处理;
20、自动部署和更新设备感知插件,实现对异构算力资源的实时监控和发现;
21、利用状态循环控制机制,实时监控算力应用的部署状态。
22、步骤4包括:
23、获取并分析应用请求的资源类型、数量、拓扑结构和设备选择范围;
24、实时更新调度策略,确保资源需求和分配的精准匹配。
25、进一步地,步骤5包括:
26、基于多维优化策略,综合考虑节点的资源利用率、网络延迟和能效等因素;
27、筛选出最优计算节点和设备,确保设备满足应用的资源和拓扑需求,优化整体系统性能。
28、步骤6包括:
29、将选定设备的文件和驱动目录挂载到应用容器中;
30、确保应用能够高效访问和利用异构算力资源。
31、进一步地,步骤7包括:
32、采用多维度监控工具,实时获取和分析节点、容器、算力设备和应用进程等多个层面的使用情况;
33、动态调整监控策略,提高资源利用效率,防止资源浪费。
34、步骤8包括:
35、利用深度学习算法评估异构算力资源的使用合理性,提供数据支持;
36、在算力资源使用出现异常的情况下,记录并分析异常数据,发送提示信息;
37、采用决策树算法分析异常原因,制定修复方案;
38、实时计算和更新异常处理的移动平均值,确保修复方案的有效性。
39、一种基于全局规划的异构算力统一调度系统,适用于所述的一种基于全局规划的异构算力统一调度方法,包括全局算力规划模块、异构算力智能感知模块、异构算力统一调度模块、设备使用管理模块和异构算力多维监控模块;
40、全局算力规划模块:用于规划整个集群的全局算力,包括默认资源使用方式、默认最大共享次数、节点隔离设备列表、节点共享设备列表、算力池的设备列表、算力池的设备权重,支持规划的创建和更新;
41、异构算力智能感知模块:用于及时感知发现异构算力设备,并将算力资源即时同步给集群管理控制器,能够感知的异构算力设备包括英伟达全系列gpu、华为昇腾系列npu、天数智芯系列gpu等;
42、异构算力统一调度模块:用于发现和调度算力应用,包括根据设备选用范围筛选节点设备、根据算力类型和数量筛选可用节点设备、根据优选策略选出最佳节点设备;
43、设备使用管理模块:用于挂载设备文件和驱动目录到应用容器,为应用提供异构算力资源;
44、异构算力多维监控模块:用于监控节点、容器、算力设备、应用进程等多个层面的异构算力使用情况,分析异构算力使用是否合理,为及时调整全局规划和算力应用提供参考依据。
45、进一步地,所述全局算力规划模块包括:
46、规划默认资源使用方式和默认最大共享次数;
47、创建和更新节点隔离设备列表和节点共享设备列表;
48、定义算力池的设备列表及设备权重;
49、异构算力智能感知模块包括:
50、感知并发现异构算力设备,将算力资源即时同步至集群管理控制器。
51、进一步地,所述异构算力统一调度模块包括:
52、根据设备选用范围筛选节点设备;
53、根据算力类型和数量筛选可用节点设备;
54、根据优选策略选出最佳节点设备。
55、进一步地,所述设备使用管理模块包括:
56、挂载设备文件和驱动目录到应用容器;
57、为应用提供异构算力资源。
58、进一步地,所述异构算力多维监控模块包括:
59、监控节点、容器、算力设备和应用进程等多个层面的异构算力使用情况;
60、分析异构算力使用的合理性;
61、提供调整全局规划和算力应用的参考依据。
62、与现有技术相比,本发明的有益效果是:
63、1、本发明提供了一种基于全局规划的异构算力统一调度方法和系统,采用的全局算力规划模型,完美兼容各种异构算力的资源差异,能够以很小的代价来定义资源类别和资源池,极大降低了异构算力的管理难度和管理成本。
64、2、本发明提供了一种基于全局规划的异构算力统一调度方法和系统,采用的资源序列补缺算法,能够快速把握集群资源全貌,有利于及时调整规划配置和调度策略优化算力分配,进而保证系统的整体稳定性和资源的整体利用率。
65、3、本发明提供了一种基于全局规划的异构算力统一调度方法和系统,采用的应用状态循环控制机制,能够准确获取应用的异构算力需求和约束要求,实时跟踪应用部署状态,确保应用的当前状态与期望状态保持一致,保障算力应用的平稳正常运行。
66、4、本发明提供了一种基于全局规划的异构算力统一调度方法和系统,采用的异构算力统一调度过程,综合考虑指定约束条件、资源负载均衡、动态调整策略、任务特性和节点能力匹配等多种因素,保证异构算力的选用合理性。
67、5、本发明提供了一种基于全局规划的异构算力统一调度方法和系统,采用的算力使用合理性评估方法,通过监控节点、容器、算力设备、应用进程等多个维度的异构算力使用情况,能够准确分析得到异构算力的资源使用率、算力峰谷、算力性能等重要指标,评估算力使用的合理性,为算力资源优化、算力应用调优、设备成本控制提供有力的参考依据。
- 还没有人留言评论。精彩留言会获得点赞!