结合旋转自监督和CLIP指导的长尾图像分类的联邦学习方法
本发明公开了一种结合旋转自监督和clip指导的长尾图像分类的联邦学习方法,属于长尾联邦学习领域。
背景技术:
1、联邦学习是一种分布式的机器学习方法,它允许多个客户端在不传输自己私有数据集的情况下,协同训练出一个性能强大的共享模型。但是在现实世界中,数据的分布通常呈现长尾分布,头部类拥有大量的数据,而尾部类仅拥有少量数据,这样的数据不利于模型的训练。联邦学习基于长尾分布的数据训练模型时,会导致模型偏向于头部类数据而忽略尾部类的数据,使模型对尾部类数据的分类能力较差。
2、目前针对联邦学习非独立同分布的问题已经有很多方法提出了解决方法。scaffold(scaffold:stochastic controlled averaging for federated learning[c],international conference on machine learning.pmlr,2020:5132–5143.)、fedprox(federated optimization in heterogeneous networks[j].proceedings of machinelearning and systems,2020,2:429–450.)等方法针对客户端的过程做出改进,使客户端模型优化方向与全局模型优化方向一致。ccvr(no fear of heterogeneity:classifiercalibration for federated learning with non-iid data[j].advances inneuralinformation processing systems,2021,34:5972–5984.)等方法通过在服务器做出改进来提高全局模型的性能。然而,以上方法并不适用于全局数据是长尾分布的情况,在全局数据是长尾分布的情况下,模型在训练过程中会忽略尾部类数据,此类方法会导致全局模型精度下降。在集中式的长尾学习方法中,对数据重新采样、解耦等方法已经被证明是有效的,但联邦学习是分布式的机器学习,集中式训练的方法并不适用于联邦学习的场景下。clip2fl(clip-guided federated learning on heterogeneity and long-tailed data[c],proceedings of the aaai conference on artificial intelligence.2024,38(13):14955–14963.)通过使用clip(contrastive language-image pre-training)指导联邦特征的生成以及指导客户端训练以获得高精度的全局模型,但是其仅仅注重模型分类器的重训练,没有对模型的特征提取器做平衡处理,导致模型的特征提取器依然受长尾数据的影响,同时,其没有充分发挥clip的指导作用。
3、综上,解决联邦学习中数据长尾分布导致模型偏移仍然是一个重要的问题。
技术实现思路
1、本发明要解决的技术问题是:提供一种面向全局图像数据呈长尾分布情况下的长尾联邦学习图像分类的方法,以缓解在长尾分布下训练的联邦学习模型对长尾数据中的多数类数据和少数类数据产生偏见的方法,最终提高全局模型的准确率。
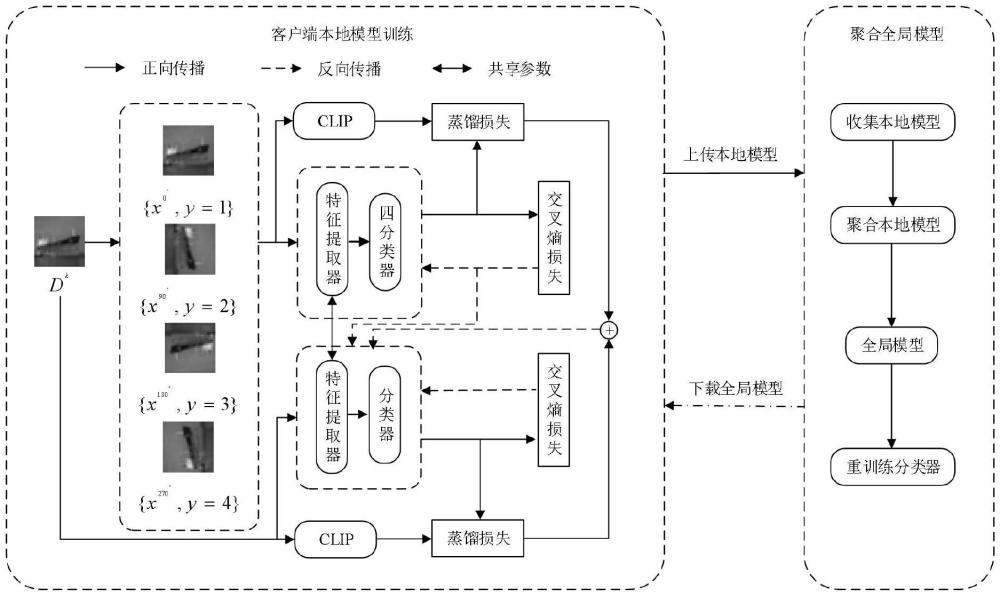
2、本发明的技术方案是:如图1所示,一种面向全局数据呈长尾分布情况下的长尾联邦学习方法。在客户端,使用旋转自监督和clip指导本地客户端模型地训练,并使用服务器下发的全局模型得出本地数据在全局模型下分类层的梯度,用于后续服务器生成联邦特征;在服务器端,服务器首先将客户端上传的模型平均聚合成全局模型,再通过从本地客户端额外收集的分类层梯度并使用clip指导服务器生成联邦特征,然后使用生成的联邦特征重新训练聚合后的全局模型的分类层。
3、具体步骤为:
4、step1:客户端使用服务器下发的全局模型在本地数据集上计算分类层的梯度,然后将当前收到的全局模型作为当前本地客户端模型,使用本地数据集对当前本地客户端模型进行训练,并使用旋转自监督和clip指导当前本地客户端模型地训练;
5、step2:服务器聚合step1训练完成后的客户端模型成为下一轮的全局模型,并利用从客户端收集的分类器梯度生成联邦特征,在生成联邦特征的过程中,使用clip指导联邦特征的生成;
6、step3:服务器复制一份step2得到的聚合后的全局模型,并使用联邦特征重新训练复制后的全局模型的分类层,最后将step2得到的聚合后的全局模型分发至客户端;
7、step4:重复step1至step3,直至达到最大通信次数,完成训练。
8、具体地,所述步骤step1具体为:
9、s1.1、对于每个客户端k和每个类别c,基于其本地数据集使用当前下发的全局模型wt计算第c个类别的分类器梯度
10、
11、其中,为第t个通信轮次客户端,lce为交叉熵损失函数,为第k个客户端的第c个类产生的d维真实特征,yi为样本标签;
12、s1.2、对于客户端k,将当前收到的全局模型wt作为本地模型其本地数据集中的每一个样本x,将样本x分别旋转{0°,90°,180°,270°},旋转后的标签为{1,2,3,4};客户端额外创建一个四分类的分类器v,然后将旋转后的样本以及标签送入客户端的特征提取器fk中,然后将特征提取器fk的输出输入到四分类分类器v中,以此构造旋转自监督学习,至此,模型训练中的有监督学习和旋转自监督的损失表示为:
13、lsup+self=lce sup(x,y)+ε·lce self(xr,yr);
14、其中,lce sup(x,y)为客户端正常训练的有监督训练的损失,y为样本x的标签,lce self为旋转自监督学习的损失,ε为控制旋转自监督学习影响的超参数,xr为旋转后的样本,yr为旋转后的样本所对应的标签;
15、s1.3、对于训练中的每个客户端k,将其本地数据集中的每一个样本x以及旋转后的xr样本输入到clip中,分别得到clip输出的logit向量,表示为和使用知识蒸馏对本地客户端模型进行指导,损失表示为:
16、
17、其中,和为本地客户端模型输出的样本x和旋转后的xr数据集输出的logit向量,kl为kl散度,β和δ为控制clip指导的程度的超参数;
18、s1.4、本地客户端模型训练的总损失为:
19、llocal=lsup+self+lkl total。
20、具体地,所述步骤step2具体为;
21、s2.1、服务器端接收到客户端训练完成后的本地模型,进一步通过以下公式聚合客户端模型,形成下一轮的全局模型:
22、
23、其中,dk表示第k个客户端的本地数据集,wt+1为聚合后的全局模型,φt为上一轮被服务器选中参与训练的客户端集合,为客户端上传训练完成后的本地模型;
24、s2.2、服务器平均从客户端收集到的真实梯度并通过以下公式计算真实梯度平均值:
25、
26、其中,为第t轮选中的客户端中第c类的梯度;
27、s2.3、服务器先随机生成m个符合真实特征维度的联邦特征然后使用分类器为随机生成的联邦特征生成相应的类别梯度并使用梯度匹配损失函数和clip指导优化随机生成的联邦特征使生成的联邦特征更符合真实数据产生的特征,公式如下:
28、
29、
30、
31、lall=lg+η·lp;
32、其中,为第t轮第c类中第i个随机生成的联邦特征,lg为梯度匹配损失函数,为联邦特征相应的类别梯度第j行的值,为真实梯度平均值相应的类别梯度第j行的值,lp为对比损失函数,zc,i为第c类中第i个随机生成的联邦特征,zj为类别不为i的联邦特征,c为类别总数,pc为随机生成的联邦特征与clip中语义信息相乘之后的类内原型,τ为温度,η为clip指导随机生成的联邦特征生成的超参数,lall为总的损失,yi为样本标签。
33、具体地,所述步骤step3具体为;
34、s3.1、将聚合后的全局模型复制一份后,对复制后的全局模型重新训练模型的分类器,首先冻结复制后的全局模型特征提取器的参数,重新训练复制后的全局模型的分类器γt,然后将聚合后的全局模型发送至客户端;
35、
36、其中,γt+1为训练后的复制后的全局模型分类器,为第t轮优化完成的联邦特征,为重新训练模型分类层的学习率,为γt的梯度,lce为交叉熵损失函数,yi为样本标签。
37、本发明的有益效果是:
38、1、由于现有的长尾联邦学习没有针对模型的特征提取器进行平衡处理,导致在长尾数据分布的情况下训练出来的模型偏向头部类,而对于尾部类的分类性能较差,模型难以对尾类数据进行分类。本发明提出了结合旋转自监督和clip指导的长尾图像分类的联邦学习方法。通过旋转自监督以及clip指导模型的训练,缓解模型在训练过程中特征提取器的不平衡。
39、2、针对全局数据呈长尾分布的情况,本发明在客户端训练过程中使用旋转自监督学习促使模型学习高质量的图像特征,以此缓解长尾分布造成的影响;同时,利用clip丰富的知识对正常训练的图像以及旋转后的图像进行指导,将clip丰富的知识转移到本地客户端的模型中,进一步增强本地客户端模型的性能。此方法缓解了长尾分布的数据对模型造成的影响,从而提高了全局模型分类的准确率。
- 还没有人留言评论。精彩留言会获得点赞!