一种考虑长时间尺度下的储能日-周协调自调度决策方法及设备与流程
本发明涉及储能调度决策技术,尤其涉及一种考虑长时间尺度下的储能日-周协调自调度决策方法及设备。
背景技术:
1、随着新能源大规模接入电力系统,新能源机组出力的间歇性和不确定性可能会导致市场电价在一段时间内维持高位或者低位。在新能源出力不确定的前提下,合理规划长时间储能以满足负荷需求是十分有必要的。因此做好储能在短时间尺度与长时间尺度的协调,是非常重要的。
2、由于储能的运行约束复杂,现有的研究大多基于解析法或智能算法,且时间尺度集中在一天之内。自调度模式不需要经过电力市场出清,申报电量即为中标电量,因此在储能装机渗透率不高的场景下,自调度模式在当前欧美主流电力批发市场中是一种常用的方式。从求解算法角度来看,强化学习中的智能体通过与市场出清过程的反复互动,逐渐学会如何改进策略,更加符合实际场景的需求。然而强化学习用以求解多决策变量的问题时存在训练困难的问题,更难以解决两阶段连续决策问题。
技术实现思路
1、针对现有技术存在的问题,本发明的目的是提供一种可以解决训练困难问题的考虑长时间尺度下的储能日-周协调自调度决策方法及设备。
2、为了实现上述发明目的,本发明提供如下技术方案:
3、一种考虑长时间尺度下的储能日-周协调自调度决策方法,包括如下步骤:
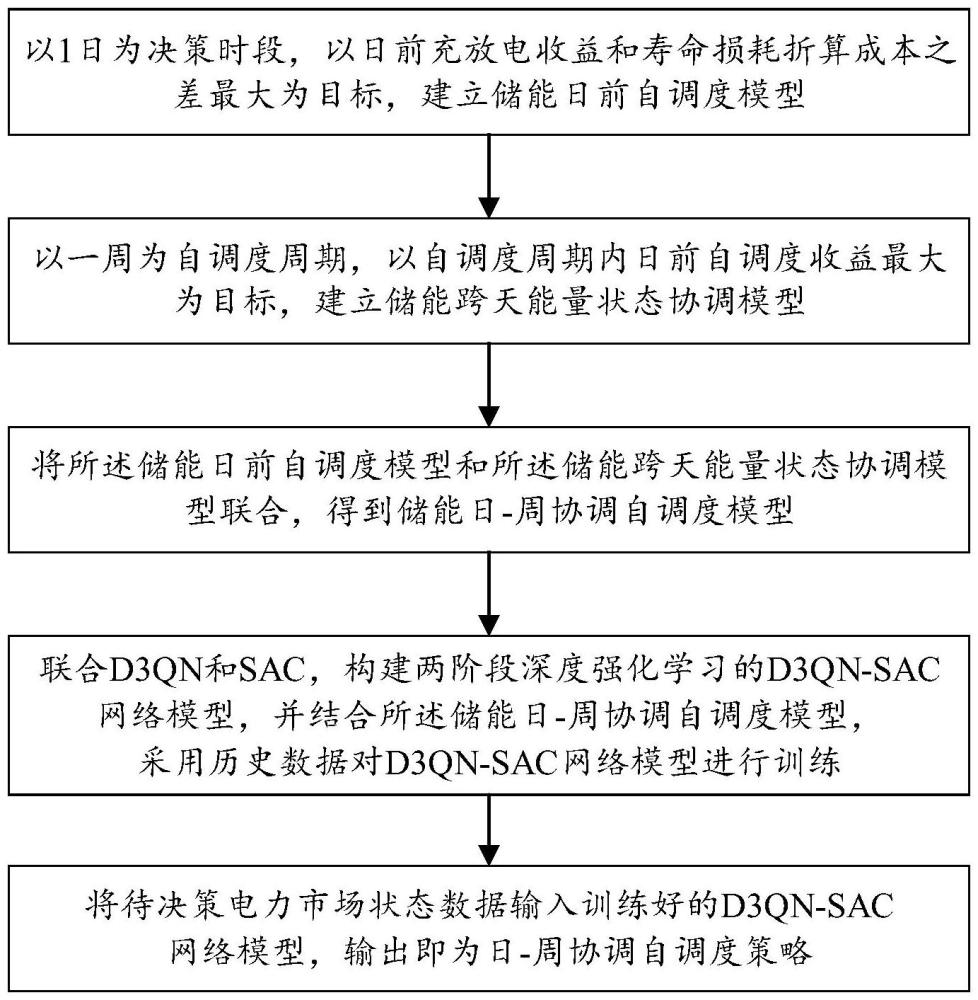
4、(1)以1日为决策时段,以日前充放电收益和寿命损耗折算成本之差最大为目标,建立储能日前自调度模型,其中,所述储能日前自调度模型用于根据日前电价走势对储能日前能量状态变化趋势进行决策;
5、(2)以一周为自调度周期,以自调度周期内日前自调度收益最大为目标,建立储能跨天能量状态协调模型,其中,所述储能跨天能量状态协调模型用于根据未来的电价走势对储能单日能量状态变化趋势进行决策;
6、(3)将所述储能日前自调度模型和所述储能跨天能量状态协调模型联合,得到储能日-周协调自调度模型;
7、(4)联合d3qn和sac,构建两阶段深度强化学习的d3qn-sac网络模型,并结合所述储能日-周协调自调度模型,采用智能体与市场出清模块交互的历史数据对d3qn-sac网络模型进行训练;
8、(5)将待决策电力市场状态数据输入训练好的d3qn-sac网络模型,输出即为日-周协调自调度策略。
9、进一步的,所述储能日前自调度模型具体包括:
10、
11、
12、
13、
14、
15、
16、
17、
18、
19、
20、
21、式中,profitk,d,t、ck,d,t分别为储能k在第d天t时段的充放电收益、寿命损耗折算成本;t为储能自调度的总时段,在日前自调度中为24小时,λk,d,t为储能k所在节点在在第d天t时段的节点电价;和分别为储能k在第d天t时段的放电、充电功率,cp为储能的寿命损耗折算系数;soct为储能在t时段的荷电状态;为储能k在t时段的能量状态;和分别为储能的最大、最小能量状态;为放电充电最大功率,分别表示储能k在第d天t时段是否处于放电模式、是否处于充电模式,具体为0-1变量,若处于放电模式,则表示储能k在第d天t+1、t时段的能量状态,ηd和ηc分别为储能的充电、放电效率;δt单个时段长度,在日前自调度中为1h,和分别为储能的最大、最小能量状态;为储能k在第24时段结束时的能量状态,为储能k在第1时段开始时的能量状态,即日前自调度的初始能量状态。
22、进一步的,所述储能跨天能量状态协调模型具体为:
23、
24、
25、式中,d为自调度周期;profitk,d为储能日前自调度模型求解得到的储能k在第d天的日前自调度收益;为储能k在第d天的单日能量状态变化趋势,即第d天终止能量与初始能量间的差;为储能在第d天的初始能量状态;为储能在第d天的终止能量状态;为储能k在一周自调度结束时的终止能量状态;为储能k在一周自调度开始时的初始能量状态。
26、进一步的,所述d3qn-sac网络模型具体包括第一阶段的d3qn算法网络和第二阶段的sac网络,所述d3qn算法网络为current q network-target q network所构成的深度q网络,所述sac网络为actor-critic网络。
27、进一步的,所述对d3qn-sac网络模型进行训练,具体包括:
28、构建第一经验回放库,所述第一经验回放库用于存储智能体与市场出清模块交互的历史数据,每条历史数据包括当前电力市场状态数据、决策动作、动作奖励和下一个电力市场状态数据;
29、以所述储能日-周协调自调度模型中储能日前自调度模型为优化目标,将历史电力市场状态数据输入d3qn算法网络进行训练,训练过程中选择决策动作,即充放电功率,最后将离散的决策动作转换为表征储能能量状态变化趋势的目标向量;
30、构建第二经验回放库,所述第而经验回放库用于存储智能体与市场出清模块交互的历史数据,每条历史数据包括当前电力市场状态数据、决策动作、动作奖励、下一个电力市场状态数据和目标向量;
31、以所述储能日-周协调自调度模型中储能跨天能量状态协调模型为优化目标,将所述目标向量输入sac网络进行训练,训练过程中选择决策动作,最终输出最优决策动作。
32、进一步的,对d3qn算法网络训练时,current q network根据从经验回放库中抽取的历史数据,对current q network的网络参数进行训练,损失函数如下:
33、l(θ)=(ri+γq'(si+1,ai+1|θ')-q(si,ai|θ))2
34、式中:l(θ)为损失函数,θ为current q network的网络参数,ri为收益;γ为折扣值;q(si,ai|θ)为current q network输出,q’(si+1,ai+1|θ’)为target q network输出,si+1,ai+1分别为第i+1个时段的电力市场状态和决策动作,si,ai分别为为第i个时段的电力市场状态和决策动作;
35、target q network根据current q network的训练程度通过软更新的方式对target q network的网络参数进行更新,具体更新方式如下:
36、θ'=πθ+(1-π)θ'
37、式中,π为软更新率,θ'为target q network的网络参数;
38、进一步的,对d3qn算法网络训练时,在训练的初期,智能体随机选取决策动作,探索可行的决策动作空间,当训练次数增加到一定值时,设置阈值,该阈值随着训练次数的增加而减少,在之后每一次训练过程中,智能体产生一个随机数,如果随机数大于该阈值,则采用greedy方法选择决策动作,否则随机选择决策动作。
39、进一步的,所述sac网络训练时,选择连续的决策动作,具体的选择方法为:最开始采用随机选择决策动作,但当训练次数增加到预设阈值后,开始选择greedy动作,在选择决策动作时将动作空间进行放大,并将超出边界的动作视为边界动作,以提升sac算法对边界值的探索效率,具体形式如下:
40、
41、
42、式中,ad,t为sac网络最终输出的在第d天t时段的决策动作,即充放电功率动作;ad,t为actor网络给出的原始动作,为放电充电最大功率,pess,k,t为采用改进动作方法后储能k的功率。
43、进一步的,所述sac网络训练时,奖励函数具体为:
44、rd,t=profitk,d,t-ck,d,t-cw,d,t-ce,d,t
45、
46、
47、式中,rd,t为结合her机制后的第d天t时段的奖励函数;ck,d,t分别为储能k在第d天t时段寿命损耗折算成本,ce,d,t为t时段的充放电动作执行后的单时段能量状态超越上限和下限约束的等效惩罚项;如果发生越线,则将此时刻的充放电功率设为0,且给予惩罚c0;cw,d,t为单日能量状态变化趋势约束或始末能量状态约束是否完成的等效惩罚项;kd为能量状态等效惩罚项的系数;g'd为储能在第d天实际能量状态变化目标;g为储能单日能量状态总体充放目标集合;g'd=gd表示第d天能量水平的总体充放量符合目标要求,为储能在第d天的终止能量状态,为储能在第d天的目标终止能量状态,为储能在未达到目标终止能量状态下的但在目标能量允许范围内的第d天的目标能量终止状态。
48、一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序以实现上述方法。
49、本发明与现有技术相比,其有益效果是:本发明考虑将第一阶段离散化,并建立储能日-周协调的自调度模型。首先对储能的两阶段自调度模型进行建模,其次采用竞争深度双q网络(dueling double deep q network,d3qn)和柔性决策-评论家(soft actor-critic,sac)相结合的算法两阶段协调优化算法对模型中的离散、连续混合决策量进行求解。为了解决长序列决策中惩罚项叠加在最后一个决策量中所带来的稀疏奖励的问题,本发明引入了事后经验回放方法(hindsight experience replay,her)。通过上述方法的结合进而确定能量型储能在日-周协调自调度中的决策策略。
- 还没有人留言评论。精彩留言会获得点赞!