基于模态同步的多模态情感检测方法
本发明涉及机器学习,具体涉及一种基于模态同步的多模态情感检测方法。
背景技术:
1、随着各种社交媒体应用和在线购物平台上多模态数据的不断增加,近年来多模态情感检测已成为研究的热点。与传统的文本情感检测和视觉情感检测相比,多模态情感检测不仅要建立文本实体和视觉对象之间的对应关系,而且通过底层和中间的视觉特征反映了不同模态在情感层面上的一致性。
2、然而,要实现准确的多模态情感检测,有两个新的挑战。
3、第一,标注多模态数据是一个耗时耗力的任务,需要专家评估和复杂的标注过程,这也导致大多数现有的多模态情感检测数据集都只有很少的标注数据。标注数据的有限不仅限制了多模态情感检测模型的训练,而且影响了模型对未见数据的泛化能力。但大多数现有的多模态情感检测方法都是在小型标注数据集上进行训练的,无法利用网络上丰富的未标注多模态数据来提升模型情感检测的能力。
4、第二,多模态情感检测面临模态对齐的挑战。用于融合的各种类型的数据,如文本、图像和声音,不仅在格式和结构上有所不同,而且在语义上也有所不同;而且从不同模态中提取的特征也有很大的差异。这种不对齐现象会导致模型在融合过程中信息的丢失信息或是误导训练,进而影响多模态情感检测的准确性。
5、因此,亟需提出一个更有效的多模态情感检测方法,既能利用网络上无标签的多模态图文数据,又可以实现多模态的同步融合。
技术实现思路
1、本发明是为了解决上述问题而进行的,目的在于提供一种基于模态同步的多模态情感检测方法。
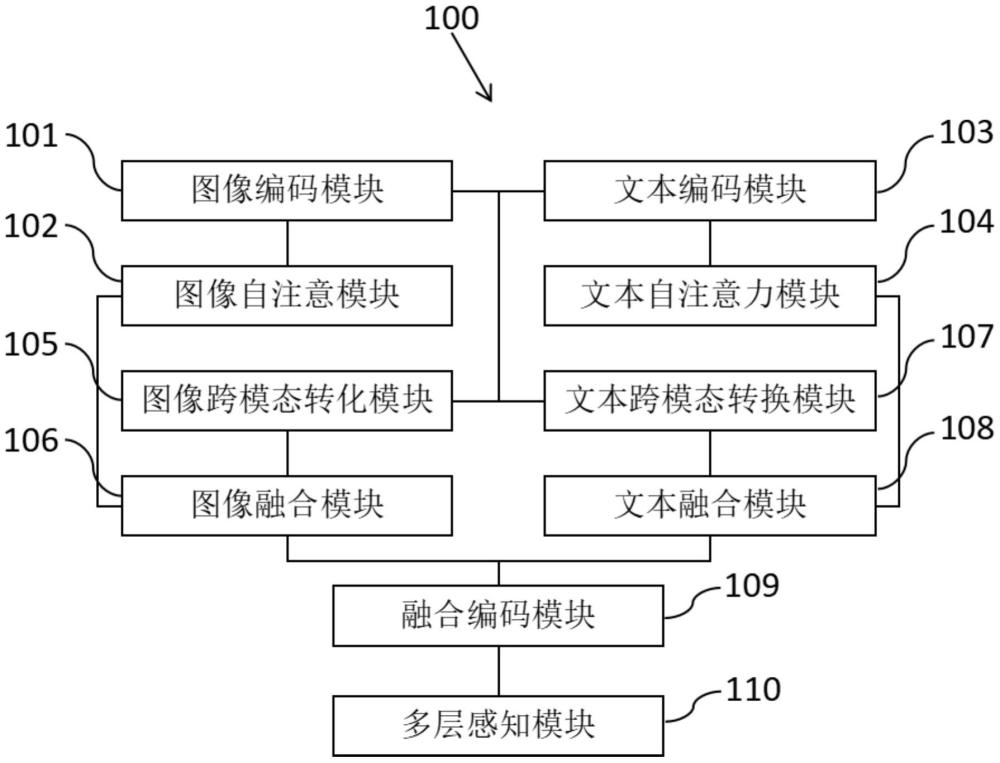
2、本发明提供了一种基于模态同步的多模态情感检测方法,用于根据指定图片和对应的指定文本,得到对应的情感检测结果,具有这样的特征,包括以下步骤:步骤s1,构建情感检测模型;步骤s2,根据现有图文数据构建训练数据集,并根据训练数据集对情感检测模型进行训练,得到训练好的情感检测模型;步骤s3,将指定图片和指定文本输入情感检测模型,得到情感检测结果,其中,情感检测模型包括:图像编码模块,用于对指定图片进行编码,得到图像向量;图像自注意模块,用于对图像向量进行自注意力处理,得到图像嵌入;文本编码模块,用于对指定文本进行编码,得到文本向量;文本自注意力模块,用于对文本向量进行自注意力处理,得到文本嵌入;图像跨模态转化模块,用于根据图像向量和文本向量,生成图像模态转换向量;图像融合模块,用于将图像模态转换向量和图像嵌入进行拼接,得到图像单模态嵌入;文本跨模态转换模块,用于根据图像向量和文本向量,生成文本模态转换向量;文本融合模块,用于将文本模态转换向量和文本嵌入进行拼接,得到文本单模态嵌入;融合编码模块,用于对图像单模态嵌入和文本单模态嵌入进行交叉模态注意力处理,得到融合向量;多层感知模块,包括多层感知机,用于对融合向量进行处理,得到情感检测结果。
3、在本发明提供的基于模态同步的多模态情感检测方法中,还可以具有这样的特征:其中,在图像自注意模块中,图像嵌入的计算表达式为:式中xv为图像嵌入,v为图像向量,为图像模态的查询的权重矩阵,为图像模态的键的权重矩阵,为图像模态的值的权重矩阵,dk为键向量的维度,在文本自注意力模块中,文本嵌入的计算表达式为:式中xt为文本嵌入,t为文本向量,为文本模态的查询的权重矩阵,为文本模态的键的权重矩阵,为文本模态的值的权重矩阵。
4、在本发明提供的基于模态同步的多模态情感检测方法中,还可以具有这样的特征:其中,在图像跨模态转化模块中,图像模态转换向量的计算表达式为:式中xv2t为图像模态转换向量,t为文本向量,v为图像向量,为图像模态的查询的权重矩阵,为图像模态的键的权重矩阵,为图像模态的值的权重矩阵,dk为键向量的维度,在文本跨模态转换模块中,文本模态转换向量的计算表达式为:式中xt2v为,为文本模态的查询的权重矩阵,为文本模态的键的权重矩阵,为文本模态的值的权重矩阵。
5、在本发明提供的基于模态同步的多模态情感检测方法中,还可以具有这样的特征:其中,在图像融合模块中,图像单模态嵌入的计算表达式为:式中为图像单模态嵌入,concat为拼接操作,xv为图像嵌入,xv2t为图像模态转换向量,在文本融合模块中,文本单模态嵌入的计算表达式为:式中为文本单模态嵌入,xt为文本嵌入,xt2v为文本模态转换向量。
6、在本发明提供的基于模态同步的多模态情感检测方法中,还可以具有这样的特征:其中,在融合编码模块中,融合向量的计算表达式为:式中xfusion为融合向量,为文本单模态嵌入,为图像单模态嵌入,为文本模态的查询的权重矩阵,为图像模态的键的权重矩阵,为图像模态的值的权重矩阵,dk为键向量的维度。
7、在本发明提供的基于模态同步的多模态情感检测方法中,还可以具有这样的特征:其中,多层感知机根据融合向量生成概率向量,概率向量的计算表达式为:p=softmax(wxfusion+b),式中xfusion为融合向量,w为权重矩阵,b为偏置向量。
8、在本发明提供的基于模态同步的多模态情感检测方法中,还可以具有这样的特征:其中,步骤s2包括以下子步骤:步骤s2-1,根据现有图文数据构建训练数据集;步骤s2-2,根据训练数据集对情感检测模型进行预训练,得到预训练的情感检测模型;步骤s2-3,根据训练数据集对预训练的情感检测模型进行微调,得到训练好的情感检测模型,训练数据集包括多个由训练图像、对应的训练文本和对应的真实标签组成的图像-文本对,在步骤s2-2中,根据训练数据集计算总体损失,并根据总体损失更新情感检测模型中图像编码模块、图像自注意模块、文本编码模块、文本自注意力模块、图像跨模态转化模块和文本跨模态转换模块的参数,在步骤s2-3中,根据训练数据集计算损失,并根据损失更新预训练的情感检测模型中多层感知模块的参数。
9、在本发明提供的基于模态同步的多模态情感检测方法中,还可以具有这样的特征:其中,图像编码模块包括图像编码器,文本编码模块包括文本编码器,总体损失的计算表达式为:loss=lossitc+lossitd+lossmlm+lossitm,lossitm=-(yitmlogpitm+(1-yitm)log(1-pitm)),式中loss为总体损失,|queuet|为动量文本编码器获得的文本向量队列的长度,|queuev|为动量图像编码器获得的图像向量队列的长度,为第i个图像-文本对中训练图像对应的图像模态转换向量,为第i个图像-文本对中训练文本对应的文本向量,为文本向量队列中第j个训练文本经由动量文本编码器处理后生成的向量,为第i个图像-文本对中训练文本对应的文本模态转换向量,为第i个图像-文本对中训练图像对应的图像向量,为图像向量队列中第j个训练图像经由动量图像编码器处理后生成的向量,τ为温度参数,p(xv)为图像编码器对图像-文本对中训练图像进行处理得到的输出,q(xv)为动量图像编码器对训练图像进行处理得到的输出,p(xt)为文本编码器对图像-文本对中训练文本进行处理得到的输出,q(xt)为动量文本编码器对训练文本进行处理得到的输出,v为词汇表的大小,为第i个词的独热编码,为情感检测模型预测掩码位置上的词是词汇表中第i个词的概率,yitm为输入情感检测模型的图像-文本对对应的真实标签,pitm为情感检测模型根据图像-文本对生成的预测概率输出,动量图像编码器与图像编码器具有相同的结构,动量图像编码器根据图像编码器的参数进行动量更新,动量文本编码器与文本编码器具有相同的结构,动量文本编码器根据文本编码器的参数进行动量更新。
10、在本发明提供的基于模态同步的多模态情感检测方法中,还可以具有这样的特征:其中,损失的计算表达式为:式中loss为损失,n为图像-文本对的总数,m为真实标签对应的情感类别的总数,pi,j为预训练的情感检测模型预测的输入的第i个图像-文本对属于第j个情感类别的概率。
11、发明的作用与效果
12、根据本发明所涉及的基于模态同步的多模态情感检测方法,因为,一方面,通过跨模态转换模块将一个模态的向量转换到另一个模态的语义空间,从而让模型可以在同一个语义空间中比较不同模态的向量;另一方面,通过单模态融合模块实现输入在维度上同步。所以,本发明的基于模态同步的多模态情感检测方法能够得到准确的多模态情感分类结果。
- 还没有人留言评论。精彩留言会获得点赞!