一种基于坐席文本处理分析的客户服务方法与流程
本发明涉及大语言模型应用,尤其涉及一种基于坐席文本处理分析的客户服务方法。
背景技术:
1、为便捷高效开展客户服务,不少行业企业都开设了官方的电话热线,在客户知情的前提下,以坐席文本记录客户交互内容,积累大量的客户交互服务数据。随着大语言模型的技术发展,大语言模型具备分析坐席文本的能力,和,学习坐席文本内容,基于所学习的坐席文本内容与客户交互的能力。但是,一方面,受限于当前大语言模型的上下文理解能力,虽然大语言模型能够处理较长的文本,但在理解和生成极长文本方面仍存在挑战,即大语言模型可能会在处理长文本时丢失上下文信息,在客服交互方面的表现是。当针对客户需求的答复内容较长时,往往会出现一些明显的不完整答复;另一方面,为了满足大语言模型泛化能力的需求,不可避免的会产生一定的错误反馈,出现幻觉,如何确保大语言模型在能够准确答复的域内进行服务,保证大语言模型的服务质量成为一个问题。
技术实现思路
1、为了解决上述技术问题或者至少部分地解决上述技术问题,本发明提供一种基于坐席文本处理分析的客户服务方法。
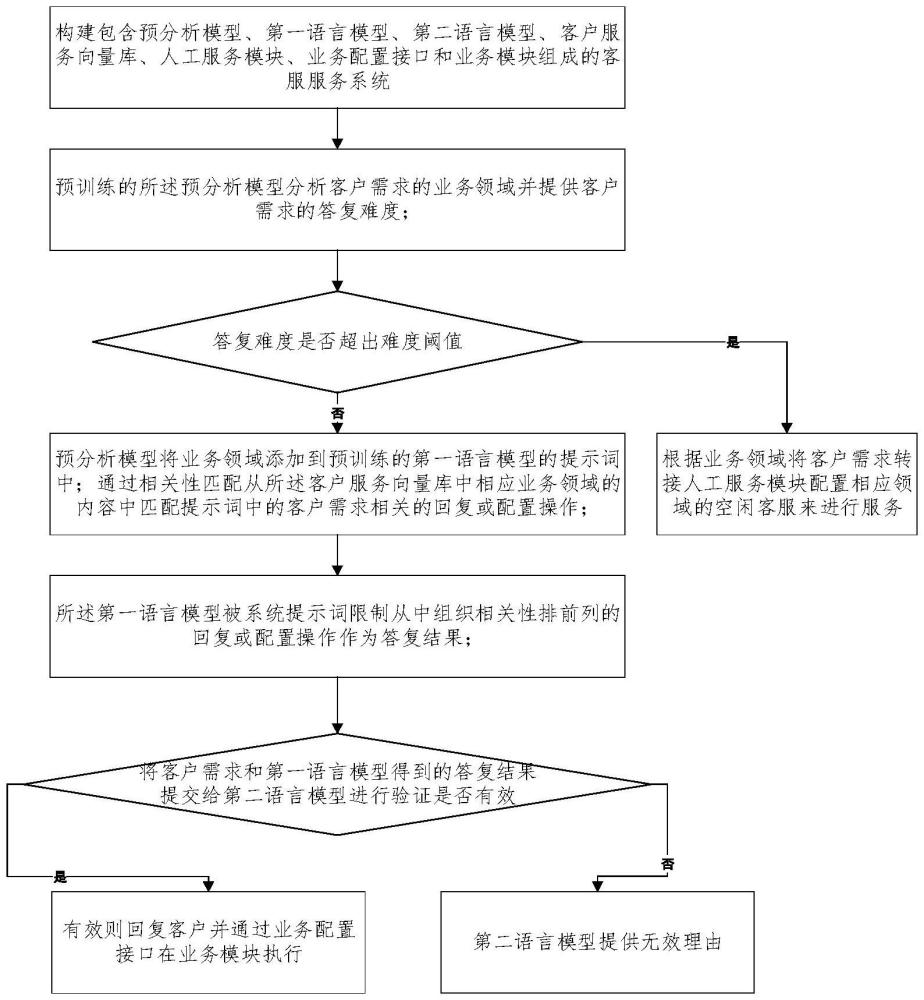
2、第一方面,本发明提供一种基于坐席文本处理分析的客户服务方法,包括:构建包含预分析模型、第一语言模型、第二语言模型、客户服务向量库、人工服务模块、业务配置接口和业务模块组成的客服服务系统;
3、客服向所述客服服务系统提供客户需求;
4、预训练的所述预分析模型分析客户需求的业务领域并提供客户需求的答复难度;
5、在难度不超出难度阈值时,预分析模型将业务领域添加到预训练的第一语言模型的提示词中;通过相关性匹配从所述客户服务向量库中相应业务领域的内容中匹配提示词中的客户需求相关的回复或配置操作,所述第一语言模型被系统提示词限制从中组织相关性排前列的回复或配置操作作为答复结果;
6、将客户需求和第一语言模型得到的答复结果提交给第二语言模型进行验证是否有效,有效则回复客户并通过业务配置接口在业务模块执行,否则第二语言模型提供无效理由;
7、在难度超出难度阈值时,根据业务领域将客户需求转接人工服务模块配置相应领域的空闲客服来进行服务。
8、更进一步的,客服服务系统包含鉴权模块,客户通过鉴权模块鉴定身份后,被允许应用所述客服服务系统;预先构建客户身份和与客户身份绑定的客户当前已办理的业务所属的业务领域之间的关联关系,在鉴权模块确定客户身份后,根据客户身份确定客户可能涉及到的业务领域,将客户可能涉及到的业务领域添加到第一语言模型的提示词中。
9、更进一步的,所述客户服务向量库包含客服参考文件的向量化片段,构建方式包括:
10、预分析坐席文本,针对坐席文本中客户的需求设置相应回复或业务配置操作,得到客服参考文件;
11、为所述客服参考文件中不同业务领域的需求及其相应的回复或配置操作添加业务领域标签;
12、将所述客服参考文件的内容进行格式化并分片,利用embedding模型将分片的客服参考文件的内容向量化,得到语言模型能够识别的向量化片段;并将向量化片段按顺序归属于相应的业务领域。
13、更进一步的,训练所述预分析模型分析客户需求的业务领域并提供答复客户需求难度的过程包括:基于boosting算法创建所述预分析模型;
14、基于影响客户需求的答复难度的因素为客服参考文件中的各个客户需求设定答复难度标签;
15、在配置完答复难度标签后,将包含答复难度标签和业务领域标签的客户需求作为预分析模型的训练数据;将客户需求的业务领域标签和预分析模型预测业务领域之间的第一交叉熵和客户需求的答复难度标签和预分析模型预测难度之间的第二交叉熵的和作为训练预分析模型的第一损失函数,以第一损失函数的值最小为目标,进行预分析模型的训练,直至第一损失函数小于设定的第一阈值,使得预分析模型能够输出客户需求的业务领域和答复难度。
16、更进一步的,影响客户需求的答复难度的因素包含:满足客户需求的回复或配置操作的长度和第一语言模型针对客户需求预测出正确的回复或配置操作的不确定性;则,所述答复难度标签通过如下方式计算:
17、
18、length()表示求满足任意客户需求的回复或配置操作的长度;i为客服参考文件中客户需求的总量,ai、aj为客服参考文件中任意客户需求ri、rj的回复或配置操作,α1为归一化长度对难度的贡献系数;
19、为满足客户需求rj的回复或配置操作aj的归一化长度;
20、p(aj|rj)为第一语言模型预测满足客户需求rj的回复或配置操作aj的概率;h()为求熵函数,h(p(aj|rj))=-p(aj|rj)logp(aj|rj),表示第一语言模型预测满足客户需求rj的回复或配置操作aj的概率的熵;α2为归一化熵对难度的贡献系数;
21、为第一语言模型预测满足客户需求rj的回复或配置操作aj的概率的归一化熵,其中,aw,w∈w是第一语言模型预测的与客户需求rj相关的回复或配置操作,w是由相关性确定的回复或配置操作的索引集合,索引集合的总索引数为n。
22、更进一步的,利用客户服务向量库配合第一语言模型构建检索增强架构,包括:利用系统提示词,约束第一语言模型,使得第一语言模型基于所述客户服务向量库中相应业务领域的内容针对客户需求进行回复或配置操作的匹配;
23、获取客户需求作为提示词,或,获取客户需求和客户需求业务领域作为提示词,将客户需求通过embedding模型向量化得到查询向量;
24、利用相关性匹配,从客户服务向量库中搜索与查询向量相关的内容作为响应向量,或,从客户服务向量库中相应业务领域的参考域中搜索与查询向量相关的内容作为响应向量;
25、将查询向量和响应向量组成反馈提示词,在反馈提示词限定的域内,第一语言模型组织相关性排前列的回复或配置操作作为答复结果。
26、更进一步的,随机生成客户需求,输入到所述检索增强架构中,得到检索增强架构的输出的服务方案;人为对检索增强架构的输出进行有效性评估,并在不可行时给出无效理由;将客户需求、检索增强架构的输出的服务方案及相应的评估内容组成训练数据来微调第二语言模型;微调过程中,利用第二语言模型输出评估结果和无效理由与实际评估结果和无效理由的交叉熵作为第二损失函数,基于第二损失函数值微调第二语言模型的参数,直至第二损失函数的值小于第二阈值,使得所述第二语言模型具备评估服务方案的能力。
27、更进一步的,在答复结果中涉及到业务的配置操作时,根据答复结果中业务的配置操作内容调用相应的业务配置接口形成服务预案,所述第二语言模型验证服务预案是否有效;有效后,将服务预案向客户反馈,用户授权同意服务预案后,通过业务模块执行服务预案。
28、第二方面,本发明提供一种基于坐席文本处理分析的客户服务装置,包括:至少一处理单元,所述处理单元通过总线单元连接存储单元,所述存储单元存储计算机程序,所述计算机程序被所述处理单元执行时,实现所述的基于坐席文本处理分析的客户服务方法。
29、第三方面,本发明提供一种计算机可读存储介质,所述计算机可读存储介质存储计算机程序,所述计算机程序被处理器执行时,实现如所述的基于坐席文本处理分析的客户服务方法。
30、本发明实施例提供的上述技术方案与现有技术相比具有如下优点:
31、本技术通过预分析模型,分析客户需求的所属业务领域和答复难度。在了解客户需求所属业务领域的情况下,将业务领域加入第一语言模型的提示词,基于业务领域检索增强架构能够匹配相应的参考域,检索增强架构从参考域选取内容对客户需求进行答复,大大减少检索增强架构的搜索范围,并减少第一语言模型分析的token量。且针对目前语言模型对高难度的需求的答复效果往往欠佳,本技术设计客户需求的答复难度,根据难度进行客户需求的分配,将第一语言模型能准确处理的客户需求分配给第一语言模型,将第一语言模型处理准确性低的客户需求转给人工客服处理。保证整体的客户服务效果的同时尽量减少人工的工作量。
- 还没有人留言评论。精彩留言会获得点赞!