一种电网运行风险控制策略生成系统及方法与流程
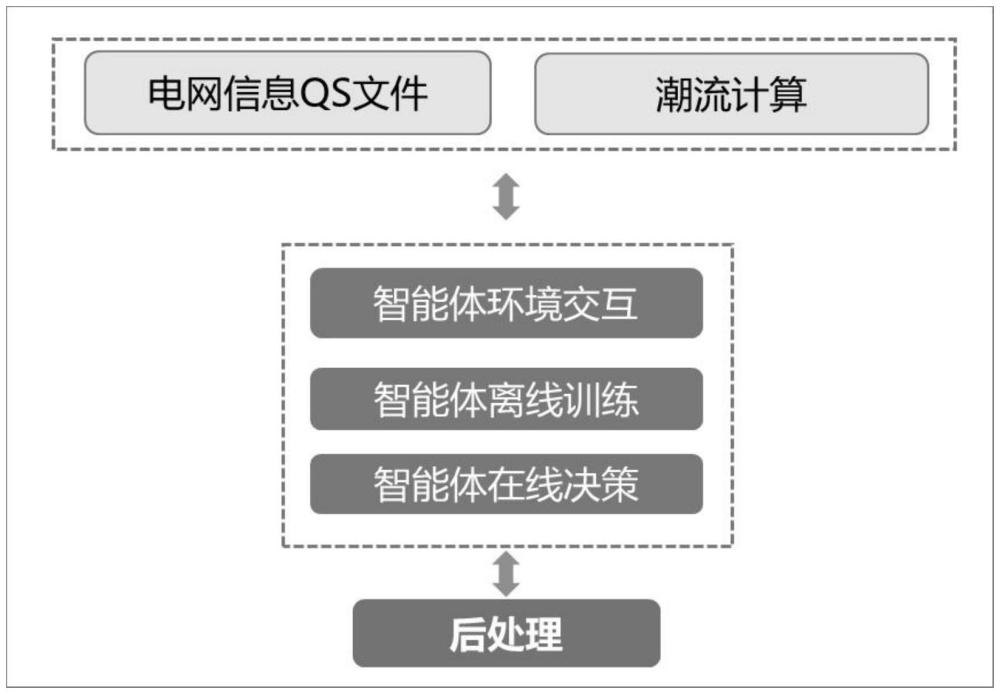
本发明属于电力系统,具体涉及一种电网运行风险控制策略生成系统及方法,还涉及一种基于深度强化学习与边界知识混合增强的电网运行风险控制策略生成系统及方法。
背景技术:
1、随着电力系统运行特性和控制模式的日益复杂,电网运行方式愈加多变,调度控制对象呈指数级增长,源荷双侧不确定性增强,使得调控人员对电网故障处置变得更加困难,需要更加自动化与智能化的方式对电网故障进行处置。
2、目前在如专利公开号为“cn110502604b”所提及的电网调控业务上,普遍还是基于人工的常规处置,而基于人工的常规处置方法存在误判、漏判和处置效率低下等缺点。
3、因此,为适应复杂不确定性强的电网环境,寻求最优化长期控制目标,实现电网运行的安全性与经济性,能够在电网故障发生后实时处置决策,就要提出一种基于强化学习的电网越限自适应决策方法,构建决策智能体,在离线电网仿真环境中学习最优决策,并于电网真实环境中应用学习到的策略,以此来解决基于人工的常规处置方法存在误判、漏判和处置效率低下等缺点。
技术实现思路
1、为解决现有技术中存在的缺陷,本发明提出一种电网运行风险控制策略生成系统及方法,基于越限奖励函数与负荷平衡后处理引导训练的电网潮流越限自适应调整智能体可学会保障电网安全稳定经济性运行的机组出力决策,改善传统依靠人工经验调节的低效与不足现象。通过实现对电网真实环境的高度仿真模拟,使得电网越限自适应调整智能体训练效果得到进一步提升,在后期通过不断迭代学习与训练,可逐步替代人工经验的调节处置,直接应用到电网实际生产环境中。
2、本发明运用如下的技术方案。
3、一种电网运行风险控制策略生成方法,包括:
4、步骤1:构造基于深度强化学习的电网潮流越限自适应调整模型;
5、步骤2:构建离线训练与在线应用一体化框架。
6、优选地,步骤1具体包括:
7、步骤1-1:构建潮流越限消除智能体的动作空间与状态空间;
8、步骤1-2:构造潮流越限奖励函数;
9、步骤1-3:出力与负荷平衡后执行处理;
10、步骤1-4:构建电网仿真运行强化学习环境。
11、优选地,在步骤1-1中,构建潮流越限消除智能体的动作空间,也就是确定智能体的动作空间如下公式(1)所示:
12、a={punits} (1)
13、其中,punits是基于当前时刻电网状态生成的下一时刻各机组有功出力。
14、优选地,在步骤1-1中,构建潮流越限消除智能体的状态空间,也就是为智能体构建如下公式(2)所示的状态空间:
15、s={punits,qunits,ulines,ilines,ploads} (2)
16、其中,punits是当前时刻电网中的各机组有功出力,qunits是当前时刻电网中的各机组无功出力,ulines是当前时刻电网中的各线路的电压值,ilines是当前时刻电网中的各线路的电流值,ploads是下一时刻电网中的负荷预测值。
17、优选地,在步骤1-2中,构建如下公式(3)所示的潮流越限奖励函数:
18、
19、其中,为第n条线路在当前时刻电网潮流中的载流量实际值,为第n条线路在电网潮流中的载流量上限值,为第n条线路在电网潮流中的载流量下限值,n为电网线路的总数量,max()为求取最大值函数,r为安全性目标的奖励值。
20、优选地,在步骤1-3中,智能体在经过深度神经网络生成决策之后,属于归一化之后范围在[-1,1]的数值,需要结合机组的可调范围,再将其映射为具体的机组出力值。
21、优选地,在后处理过程中,以下一时刻预测负荷值之和为调节目标,即作为各机组出力之和,并且根据每台机组在此时刻的可调节范围,按设定比例分配调节量,最终实现机组出力之和等于预测负荷值之和。
22、优选地,步骤1-4具体包括对电网运行仿真环境进行潮流计算,以确定电力系统中各个节点的电压和相角以及各条输电线路的潮流,而在进行潮流计算时,交互服务模块实现交互环境与潮流计算模块的集成,交互服务模块是一个基于java的软件程序,它负责与强化学习智能体进行数据通信和控制指令的传递。
23、优选地,交互服务模块的功能如下:
24、接收并解析智能体的动作请求,根据请求中的控制变量,更新电力系统模型中的机组、负荷数据;
25、调用潮流计算模块,根据电力系统模型中的结构参数和负荷情况,求解各个节点的电压和各条线路的潮流,并判断电力系统是否满足约束条件;
26、生成新的qs文件,将潮流计算结果保存在qs文件中;
27、从qs文件中提取机组、线路、母线设备的相关数据,作为电网状态返回给智能体,供智能体进行学习和决策。
28、优选地,步骤2具体包括:
29、步骤2-1:仿真环境在读取此时的网架信息后将智能体状态空间与动作空间进行初始化,以适应网架结构,同时构造基于深度神经网络的actor与critic网络;
30、步骤2-2:确定好训练数据的时间段、训练总步数、训练回合数、回合包含步数智能体训练条件参数;
31、步骤2-3:在前1000步训练中,属于探索阶段,每个回合开始时智能体向交互环境服务程序请求随机时刻的状态信息;
32、步骤2-4:交互环境服务程序读取当前时刻的qs文件,以及下一时刻的qs文件,解析其中的数据并返回智能体需要的观测状态数据;
33、步骤2-5:智能体收到观测状态数据后,将其作为输入,使用actor网络得到[-1,1]区间的机组调节输出值;
34、步骤2-6:对步骤2-5中获得的输出值进行后处理,在训练过程中,直接使用下一时刻的实际负荷值作为下一时刻的负荷预测值,实现机组出力与预测负荷值的平衡调节,得到机组的实际出力值;
35、步骤2-7:智能体将机组的实际出力值返回交互环境服务程序,交互环境服务程序收到机组的实际出力值后,将其直接替换下一时刻qs文件中对应机组的出力值,并进行潮流计算,再将潮流计算后生成的qs文件,以及再下一时刻的qs文件中提取的数据作为下一时刻的观测状态返回智能体,同时返回潮流计算后的越限信息;
36、步骤2-8:智能体收到数据后,首先根据越限信息,计算此次动作的奖励值,并将其与此次动作的当前时刻观测状态、当前动作、下一时刻观测状态作为一条数据一起存入训练数据缓存中,以供后续学习使用;
37、步骤2-9:此时智能体次回合的训练步数加1,总训练步数加1,回到步骤2-5的操作;当回合步数达到12时则结束此回合,总回合数加1,并开始新回合的训练。当总训练数达到步骤2-2中设定的参数时,智能体训练完成,保存训练参数,退出程序结束训练;
38、步骤2-10:当1000步训练完成后,属于应用阶段,除了每回合开始时按步骤2-3到步骤2-9的流程执行外,初始时刻的选择尽量挑选历史越限数据的时刻,并且此时在每个训练步交互后,还需要从训练数据缓存中随机读取n条数据,利用梯度下降的方式,更新critic网络参数与actor网络参数,以优化智能体的参数,生成最佳策略。
39、在模型完成基于实际历史电网数据的离线训练后,智能体此时已掌握生成安全不越限、供电与预测负荷平衡的机组出力调节策略。
40、优选地,电网运行风险控制策略生成方法,还包括:将训练好的智能体置于在线应用,其在线决策流程如下:
41、智能体读取训练完保存好的参数,用其对自身初始化,处于准备决策的状态;
42、如果操作人员发现此时电网存在越限情况,采取相应操作后,生产环境将生成新的qs文件,此时部署在应用环境中的交互环境服务程序将前一时刻的越限qs文件以及最新的qs文件数据提取出来返回智能体作为观测状态;
43、智能体收到观测状态数据后,将其作为输入,使用actor网络得到[-1,1]区间的机组调节输出值,经过后处理得到机组实际调节值并返回交互环境服务程序,此为针对越限情况生成的调节策略;
44、交互环境服务程序收到机组的实际出力值后,将其直接替换下一时刻qs文件中对应机组的出力值,并进行潮流计算,即可得到采用智能体决策后的电网状态qs文件,与生产环境中人为操作后形成的qs文件进行比较,在效果上可以看出智能体调节后的电网处于安全不越限状态。
45、一种电网运行风险控制策略生成系统,包括:
46、构造模块,其用于构造基于深度强化学习的电网潮流越限自适应调整模型;
47、构建模块,其用于构建离线训练与在线应用一体化框架。
48、本发明的有益效果在于,和现有技术相比,本发明的技术效果包括:
49、基于越限奖励函数与负荷平衡后处理引导训练的电网潮流越限自适应调整智能体可学会保障电网安全稳定经济性运行的机组出力决策,改善传统依靠人工经验调节的低效与不足现象。通过实现对电网真实环境的高度仿真模拟,使得电网越限自适应调整智能体训练效果得到进一步提升,在后期通过不断迭代学习与训练,可逐步替代人工经验的调节处置,直接应用到电网实际生产环境中。
- 还没有人留言评论。精彩留言会获得点赞!