一种模型训练方法、装置、存储介质及处理器与流程
本技术涉及人工智能,特别是涉及一种模型训练方法、装置、存储介质及处理器。
背景技术:
1、随着人工智能技术的快速发展,人工智能技术被广泛应用在各个行业和领域中,例如,在医疗健康领域,通过人工智能技术将临床大数据转化为临床可用的知识,并构建智能预测模型,实现对疾病的风险提示。
2、然而,在构建智能预测模型的过程中,经常会遇到一些不平衡样本数据的处理,例如处理罕见病等不同类别的样本数量有量级上的差距的样本数据。由于此类数据中正常样本的数量远大于异常样本的数量,导致在智能预测模型的训练过程中,易分样本的数量较多,使模型过度关注易分样本而忽视了难分样本,导致模型对难分样本的分类性能下降。
技术实现思路
1、基于上述问题,本技术提供了一种模型训练方法、装置、存储介质及处理器,目的是在处理第一类样本的数量少于第二类样本的数量的训练样本集合时,通过动态调节易分样本和难分样本在模型总体损失中所占的比重,降低易分样本在模型总体损失中所占的比重,提高模型对难分样本的分类性能。
2、本技术实施例公开了如下技术方案:
3、本技术第一方面,提供了一种模型训练方法,该方法包括:
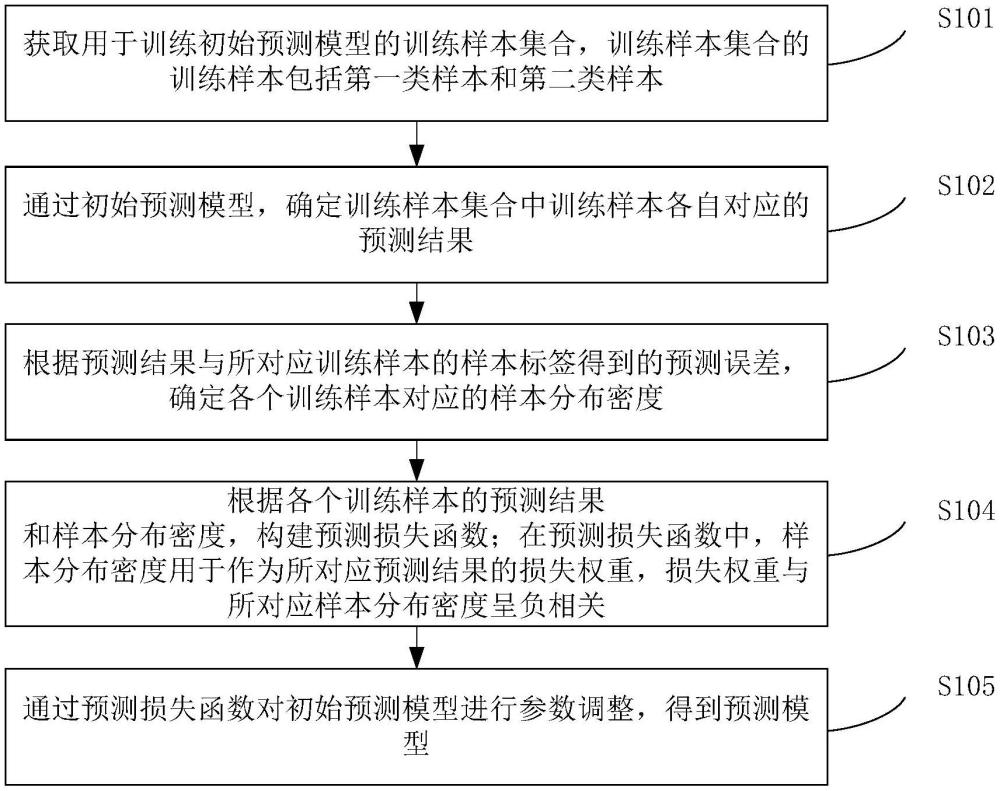
4、获取用于训练初始预测模型的训练样本集合,训练样本集合的训练样本包括第一类样本和第二类样本,第一类样本的样本标签为目标标签,第二类样本的样本标签为非目标标签,第一类样本的数量在训练样本集合中少于第二类样本的数量;
5、通过初始预测模型,确定训练样本集合中训练样本各自对应的预测结果;
6、根据预测结果与所对应训练样本的样本标签得到的预测误差,确定各个训练样本对应的样本分布密度;其中,针对训练样本集合中的第i个训练样本,确定以第i个训练样本的预测误差为中心点的误差值区间中的所有训练样本的预测误差的误差数量,并依据误差数量确定第i个训练样本对应的样本分布密度;
7、根据各个训练样本的预测结果和样本分布密度,构建预测损失函数;在预测损失函数中,样本分布密度用于作为所对应预测结果的损失权重,损失权重与所对应样本分布密度呈负相关;
8、通过预测损失函数对初始预测模型进行参数调整,得到预测模型;预测模型用于识别待处理数据属于目标标签对应的目标类别,或者属于非目标标签对应的其他类别。
9、在可选的实现方式中,针对训练样本集合中的第i个训练样本,确定以第i个训练样本的预测误差为中心点的误差值区间中的所有训练样本的预测误差的误差数量,并依据误差数量确定第i个训练样本对应的样本分布密度,包括:
10、基于训练样本集合的训练样本的数量确定目标长度;
11、将第i个训练样本的预测误差作为中心点,以目标长度为半径确定第i个训练样本对应的误差值区间;
12、统计第i个训练样本对应的误差值区间中的所有训练样本的预测误差的误差数量,并依据误差数量确定第i个训练样本对应的样本分布密度。
13、在可选的实现方式中,依据误差数量确定第i个训练样本对应的样本分布密度,包括:
14、确定第i个训练样本对应的误差值区间的区间长度;
15、基于误差数量和区间长度,确定第i个训练样本对应的样本分布密度。
16、在可选的实现方式中,在获取用于训练初始预测模型的训练样本集合之前,模型训练方法还包括:
17、获取目标数据集合;目标数据集合中包括多个样本数据,每个样本数据中包括多个子数据;
18、基于每个样本数据中的子数据的缺失情况确定该样本数据的数据缺失率,得到每个样本数据的数据缺失率;
19、依据每个样本数据的数据缺失率对该样本数据中缺失的子数据进行数据填充处理,得到训练样本。
20、在可选的实现方式中,依据每个样本数据的数据缺失率对该样本数据中缺失的子数据进行数据填充处理,得到训练样本,包括:
21、判断样本数据的数据缺失率是否小于预设阈值;
22、若样本数据的数据缺失率大于或等于预设阈值,则删除样本数据;
23、若样本数据的数据缺失率小于预设阈值,且样本数据中缺失的子数据为数值数据,则获取目标数据集合中的所有目标子数据,并基于所有目标子数据的平均值对样本数据中缺失的子数据进行填充,得到训练样本;目标子数据的数据类别与缺失的子数据的数据类别相同,且目标子数据对应的样本数据的样本标签与缺失的子数据对应的样本数据的样本标签相同。
24、在可选的实现方式中,根据各个训练样本的预测结果和样本分布密度,构建预测损失函数,包括:
25、基于第一类样本的数量和第二类样本的数量确定目标调节参数;
26、根据目标调节参数、各个训练样本的预测结果和样本分布密度,构建预测损失函数。
27、本技术第二方面,提供了一种模型训练装置,该装置包括:
28、获取模块,用于获取用于训练初始预测模型的训练样本集合,训练样本集合的训练样本包括第一类样本和第二类样本,第一类样本的样本标签为目标标签,第二类样本的样本标签为非目标标签,第一类样本的数量在训练样本集合中少于第二类样本的数量;
29、预测模块,用于通过初始预测模型,确定训练样本集合中训练样本各自对应的预测结果;
30、样本分布密度确定模块,用于根据预测结果与所对应训练样本的样本标签得到的预测误差,确定各个训练样本对应的样本分布密度;其中,针对训练样本集合中的第i个训练样本,确定以第i个训练样本的预测误差为中心点的误差值区间中的所有训练样本的预测误差的误差数量,并依据误差数量确定第i个训练样本对应的样本分布密度;
31、损失函数构建模块,用于根据各个训练样本的预测结果和样本分布密度,构建预测损失函数;在预测损失函数中,样本分布密度用于作为所对应预测结果的损失权重,损失权重与所对应样本分布密度呈负相关;
32、模型训练模块,用于通过预测损失函数对初始预测模型进行参数调整,得到预测模型;预测模型用于识别待处理数据属于目标标签对应的目标类别,或者属于非目标标签对应的其他类别。
33、可选地,样本分布密度确定模块包括:
34、长度确定单元,用于基于训练样本集合的训练样本的数量确定目标长度;
35、误差值区间确定单元,用于针对训练样本集合中的第i个训练样本,将第i个训练样本的预测误差作为中心点,以目标长度为半径确定第i个训练样本对应的误差值区间;
36、样本分布密度确定单元,用于统计第i个训练样本对应的误差值区间中的所有训练样本的预测误差的误差数量,并依据误差数量确定第i个训练样本对应的样本分布密度。
37、本技术第三方面,提供了一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,当计算机程序被处理器运行时,实现上述第一方面介绍的模型训练方法。
38、本技术第四方面,提供了一种处理器,用于运行计算机程序,计算机程序运行时执行上述第一方面介绍的模型训练方法。
39、相较于现有技术,本技术具有以下有益效果:
40、本技术技术方案中,在处理第一类样本的数量少于第二类样本的数量的训练样本集合时,以每个训练样本的预测误差为中心点确定的误差值区间,能够更精确地确定每个训练样本的真实误差水平,避免了通过固定区间内的训练样本的预测误差之间的相似性进行误差近似估计,导致确定的训练样本的误差水平的精确度较低的问题,从而针对训练样本集合中的第i个训练样本,通过确定以第i个训练样本的预测误差为中心点的误差值区间中的所有训练样本的预测误差的误差数量,并依据误差数量确定第i个训练样本对应的样本分布密度,能够准确的确定各个训练样本对应的样本分布密度,根据样本分布密度能够准确的确定该训练样本是易分样本还是难分样本;根据各个训练样本的预测结果和样本分布密度构建预测损失函数,将样本分布密度作为所对应预测结果的损失权重,使损失权重与所对应样本分布密度呈负相关,从而通过预测损失函数对初始预测模型进行参数调整得到预测模型,能够动态调节易分样本和难分样本在模型总体损失中所占的比重,降低易分样本在模型总体损失中所占的比重,避免了因模型过度关注易分样本而忽视了难分样本,导致模型对难分样本的分类性能下降问题,提高了模型对难分样本的分类性能。
- 还没有人留言评论。精彩留言会获得点赞!