一种多模态大语言模型的大小模型协同训练方法及装置
本发明涉及人工智能 ,尤其涉及一种多模态大语言模型的大小模型协同训练方法及装置。
背景技术:
1、近年来,多模态大规模预训练模型在人工智能领域取得了重大突破。这些模型通过整合视觉和语言信息,在图像描述、视觉问答等复杂任务中表现出色。然而,现有的多模态大语言模型(multimodal-large-language-models,mllm)通常有两条独立的研究路径:一种是通过扩展模型规模来提高性能,另一种是通过剪枝等方法减少参数,以适应计算资源有限的环境。这两种路径的独立性导致了训练策略的效率低下,且模型间的互联性较差,未能充分利用大模型和小模型各自的优势。
技术实现思路
1、本发明提供一种多模态大语言模型的大小模型协同训练方法及装置,用以解决现有技术中多模态大语言模型训练策略的效率低下,且模型间的互联性较差,未能充分利用大模型和小模型各自的优势的缺陷,实现大型多模态大语言模型和小型多模态大语言模型的协同训练。 本发明提出的技术方案如下:
2、第一方面,本发明提供一种多模态大语言模型的大小模型协同训练方法,包括:
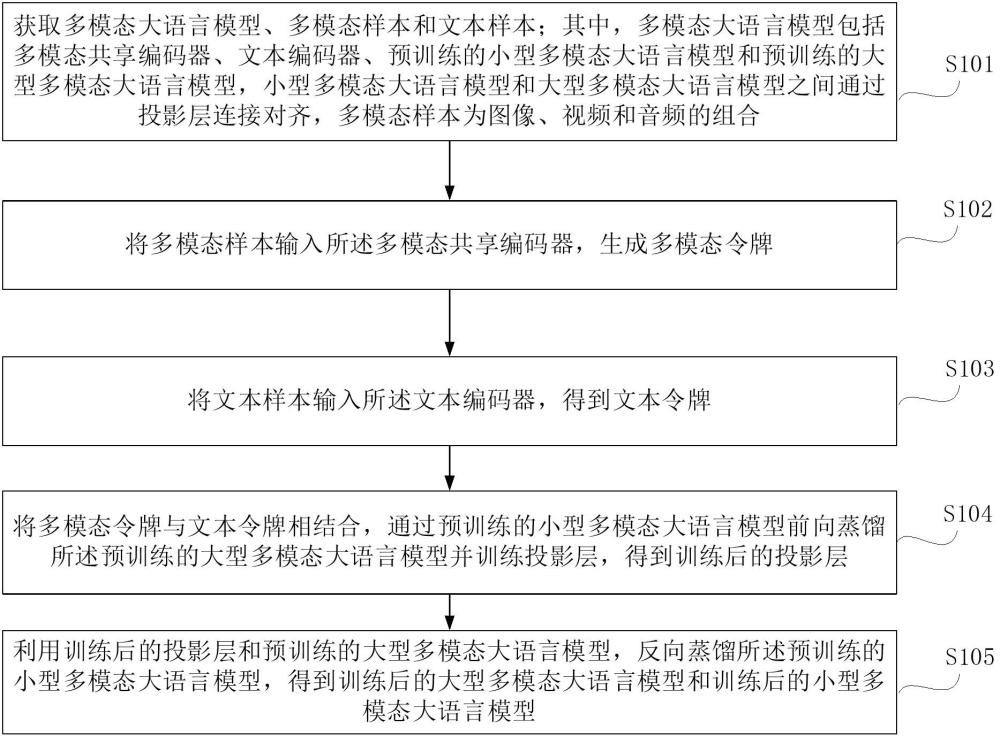
3、获取多模态大语言模型、多模态样本和文本样本;其中,多模态大语言模型包括多模态共享编码器、文本编码器、预训练的小型多模态大语言模型和预训练的大型多模态大语言模型,小型多模态大语言模型和大型多模态大语言模型之间通过投影层连接对齐,多模态样本为图像、视频和音频的组合;
4、将多模态样本输入所述多模态共享编码器,生成多模态令牌;
5、将文本样本输入所述文本编码器,得到文本令牌;
6、将多模态令牌与文本令牌相结合,通过预训练的小型多模态大语言模型前向蒸馏所述预训练的大型多模态大语言模型并训练投影层,得到训练后的投影层;
7、利用训练后的投影层和预训练的大型多模态大语言模型,反向蒸馏所述预训练的小型多模态大语言模型,得到训练后的大型多模态大语言模型和训练后的小型多模态大语言模型。
8、可选地,所述将多模态令牌与文本令牌相结合,通过预训练的小型多模态大语言模型前向蒸馏所述预训练的大型多模态大语言模型并训练投影层,得到训练后的投影层,包括:
9、小型多模态大语言模型基于多模态令牌和文本令牌生成相应的文本描述;
10、投影层将多模态令牌与文本令牌进行空间对齐,生成对齐后的多模态特征;
11、大型多模态大语言模型基于对齐后的多模态特征生成相应的文本描述;
12、基于预先构建的第一损失函数和生成的文本描述,计算第一总损失;
13、使用优化算法更新投影层的参数以最小化第一总损失,得到训练后的投影层。
14、可选地,所述基于预先构建的第一损失函数和生成的文本描述,计算第一总损失,包括:
15、计算小型多模态大语言模型生成的文本描述与文本样本的真实标签之间的差异,得到第一字幕损失;
16、计算小型多模态大语言模型生成的文本描述的概率分布与大型多模态大语言模型生成的文本描述的概率分布之间的kl散度,得到前向kld损失;
17、将所述第一字幕损失和所述前向kld损失输入预先构建的第一损失函数,得到所述第一总损失。
18、可选地,所述利用训练后的投影层和预训练的大型多模态大语言模型,反向蒸馏所述预训练的小型多模态大语言模型,得到训练后的大型多模态大语言模型和训练后的小型多模态大语言模型,包括:
19、小型多模态大语言模型基于多模态令牌和文本令牌生成相应的文本描述;
20、使用训练后的投影层将多模态令牌与文本令牌进行空间对齐,生成对齐后的多模态特征;
21、大型多模态大语言模型基于对齐后的多模态特征生成相应的文本描述;
22、基于预先构建的第二损失函数和生成的文本描述,计算第二总损失;
23、使用优化算法更新所述预训练的小型多模态大语言模型的参数和所述预训练的大型多模态大语言模型的参数以最小化第二总损失,得到训练后的大型多模态大语言模型和训练后的小型多模态大语言模型。
24、可选地,所述基于预先构建的第二损失函数和生成的文本描述,计算第二总损失,包括:
25、计算大型多模态大语言模型生成的文本描述与文本样本的真实标签之间的差异,得到第二字幕损失;
26、计算大型多模态大语言模型生成的文本描述的概率分布与小型多模态大语言模型生成的文本描述的概率分布之间的kl散度,得到反向kld损失;
27、将所述第二字幕损失和所述反向kld损失输入预先构建的第二损失函数,得到所述第二总损失。
28、可选地,所述多模态令牌包括第一视觉令牌、第二视觉令牌和第三视觉令牌,所述多模态共享编码器包括图像分词器、视频分词器、音频分词器和视觉编码器;
29、所述将多模态样本输入所述多模态共享编码器,生成多模态令牌,包括:
30、图像分词器将图像分割成多个区域得到第一图像序列,视觉编码器对第一图像序列进行编码得到第一视觉令牌;
31、视频分词器从视频中抽取出多个视频帧,并将每一视频帧分割成多个区域得到第二图像序列,视觉编码器对第二图像序列进行编码得到对应的嵌入表示,把多个视频帧的嵌入表示进行拼接得到第二视觉令牌;
32、音频分词器将音频转换为多张梅尔频谱图,并将每一梅尔频谱图分割成多个区域得到第三图像序列,视觉编码器对第三图像序列进行编码得到嵌入表示,把多张梅尔频谱图的嵌入表示进行拼接得到第三视觉令牌。
33、第二方面,本发明还提供一种多模态大语言模型的大小模型协同训练装置,包括:
34、获取模块,用于获取多模态大语言模型、多模态样本和文本样本;其中,多模态大语言模型包括多模态共享编码器、文本编码器、预训练的小型多模态大语言模型和预训练的大型多模态大语言模型,小型多模态大语言模型和大型多模态大语言模型之间通过投影层连接对齐,多模态样本为图像、视频和音频的组合;
35、多模态编码模块,用于将多模态样本输入所述多模态共享编码器,生成多模态令牌;
36、文本编码模块,用于将文本样本输入所述文本编码器,得到文本令牌;
37、前向蒸馏模块,用于将多模态令牌与文本令牌相结合,通过预训练的小型多模态大语言模型前向蒸馏所述预训练的大型多模态大语言模型并训练投影层,得到训练后的投影层;
38、反向蒸馏模块,用于利用训练后的投影层和预训练的大型多模态大语言模型,反向蒸馏所述预训练的小型多模态大语言模型,得到训练后的大型多模态大语言模型和训练后的小型多模态大语言模型。
39、第三方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述第一方面所述多模态大语言模型的大小模型协同训练方法。
40、第四方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述第一方面所述多模态大语言模型的大小模型协同训练方法。
41、第五方面,本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述第一方面所述多模态大语言模型的大小模型协同训练方法。
42、基于上述技术方案,本发明较现有技术而言的有益效果为:
43、本发明提供的一种多模态大语言模型的大小模型协同训练方法及装置,通过协同训练框架,将大型多模态大语言模型和小型多模态大语言模型通过投影层连接起来。利用小型多模态大语言模型的轻量级特性能够快速对齐多模态信息,从而提升整体训练效率。然后通过知识蒸馏帮助大型多模态大语言模型更好地对齐跨模态信息,同时利用大型多模态大语言模型的丰富知识库增强小型多模态大语言模型的性能。大型多模态大语言模型和小型多模态大语言模型的协同训练不仅提升了大型多模态大语言模型的跨模态对齐能力,还通过知识蒸馏增强了小型多模态大语言模型的性能,实现了大型多模态大语言模型和小型多模态大语言模型的紧密结合,能力相互增强,允许直接适应各种计算资源场景。
44、本发明的其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
45、为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!