大语言模型、模型训练方法、装置、介质、设备及产品与流程
本发明涉及人工智能,具体涉及大语言模型、模型训练方法、装置、介质、设备及产品。
背景技术:
1、神经网络为人工智能中最主流、使用最广泛的一种机器学习技术,神经网络的节点数对应该层向量的维度,维度足够大时,才能保证模型的性能,但维度过大时,又会导致模型计算效率低下(除此以外也会有难以训练、过拟合等问题),因此,为模型设计合适的维度就尤为重要。
2、随着生成式大语言模型的不断突破,尺度定律逐渐得到认可,模型参数量越做越大。然而,大语言模型向量维度难以确定、难以系统性优化,阻碍了模型的训练和推理效率。
技术实现思路
1、有鉴于此,本发明提供了大语言模型、模型训练方法、装置、介质、设备及产品,以解决大语言模型向量维度难以确定、难以系统性优化,阻碍了模型的训练和推理效率的问题。
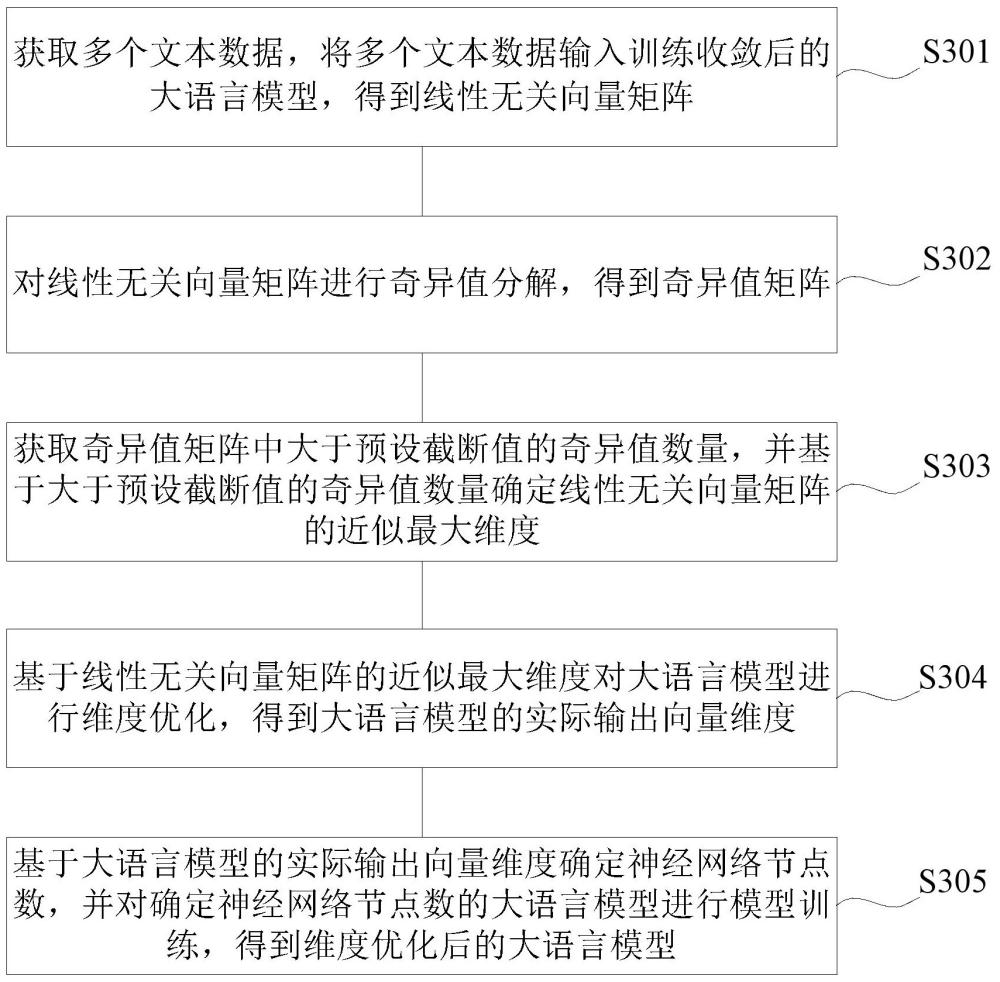
2、第一方面,本发明提供了一种大语言模型训练方法,该方法包括:
3、获取多个文本数据,将多个文本数据输入训练收敛后的大语言模型,得到线性无关向量矩阵;
4、对线性无关向量矩阵进行奇异值分解,得到奇异值矩阵;
5、获取奇异值矩阵中大于预设截断值的奇异值数量,并基于大于预设截断值的奇异值数量确定线性无关向量矩阵的近似最大维度;
6、基于线性无关向量矩阵的近似最大维度对大语言模型进行维度优化,得到大语言模型的实际输出向量维度;
7、基于大语言模型的实际输出向量维度确定神经网络节点数,并对确定神经网络节点数的大语言模型进行模型训练,得到维度优化后的大语言模型。
8、本实施例提供的一种大语言模型训练方法,通过对线性无关向量矩阵进行奇异值分解,实现了对线性无关向量矩阵中向量维度的重要性判断,确定了模型输出向量维度的冗余程度,进而获取奇异值矩阵中大于预设截断值的奇异值数量,基于大于预设截断值的奇异值数量确定线性无关向量矩阵的近似最大维度,利用基于线性无关向量矩阵的近似最大维度对大语言模型进行维度优化,实现了对大语言模型的输出向量维度的获取,以及对大语言模型向量维度的有效优化,提升了大语言模型的训练和推理效率,为大语言模型的尺寸设计提供更多的理论基础。
9、在一种可选的实施方式中,获取奇异值矩阵中大于预设截断值的奇异值数量,并基于大于预设截断值的奇异值数量确定线性无关向量矩阵的近似最大维度,包括:
10、将奇异值矩阵中的对角元与预设截断值进行比较;
11、获取大于预设截断值的对角元数量,将大于预设截断值的对角元数量作为线性无关向量矩阵的近似最大维度;
12、或者,若奇异值矩阵中的对角元均大于预设截断值,则对大语言模型进行模型维度扩增,确定线性无关向量矩阵的近似最大维度。
13、本实施例提供的一种大语言模型训练方法,通过将奇异值矩阵中的对角元与预设截断值进行比较,进而根据比较结果,利用截断值实现了奇异值截断,确定了对角元数量确定线性无关向量矩阵的近似最大维度,利用一种近似查找大语言模型合理维度的方法实现了对大语言模型向量维度的快速确定,为大语言模型的维度优化奠定了基础。
14、在一种可选的实施方式中,若奇异值矩阵中的对角元均大于预设截断值,则对大语言模型进行模型维度扩增,确定线性无关向量矩阵的近似最大维度,包括:
15、若奇异值矩阵中的对角元均大于预设截断值,则基于对角元和预设截断值计算模型新增维度;
16、基于奇异值矩阵的总维度和模型新增维度确定线性无关向量矩阵的近似最大维度。
17、本实施例提供的一种大语言模型训练方法,在奇异值矩阵中的对角元均大于预设截断值的情况下,对大语言模型进行模型维度扩增,使得大语言模型的总维度符合线性无关向量矩阵的近似最大维度,一定程度上优化了模型维度。
18、在一种可选的实施方式中,基于奇异值矩阵的总维度和模型新增维度确定线性无关向量矩阵的近似最大维度,线性无关向量矩阵的近似最大维度的计算公式如下所示:
19、
20、
21、其中,r表示余数,表示奇异值矩阵中的对角元,表示预设截断值,表示线性无关向量矩阵的近似最大维度,表示奇异值矩阵的总维度,表示模型新增维度。
22、在一种可选的实施方式中,基于线性无关向量矩阵的近似最大维度对大语言模型进行维度优化,得到大语言模型的实际输出向量维度,包括:
23、获取计算硬件内存容量,将计算硬件内存容量与当前大语言模型的内存进行比较;其中,当前大语言模型满足线性无关向量矩阵的近似最大维度;
24、若当前大语言模型的内存大于计算硬件内存容量,则基于计算硬件内存容量的上限确定大语言模型的实际输出向量维度;
25、或者,若当前大语言模型的内存小于计算硬件内存容量,则将线性无关向量矩阵的近似最大维度作为大语言模型的实际输出向量维度。
26、本实施例提供的一种大语言模型训练方法,通过计算硬件内存容量与当前大语言模型的内存的比较结果,选取计算硬件内存容量的上限或线性无关向量矩阵的近似最大维度作为大语言模型的实际输出向量维度,考虑了大语言模型的当前输出向量维度以及计算硬件设备的限制条件,使得大语言模型的实际输出向量维度更加符合实际应用需求,实现了对大语言模型向量维度的有效优化。
27、在一种可选的实施方式中,对线性无关向量矩阵进行奇异值分解,得到奇异值矩阵,包括:
28、将线性无关向量矩阵进行转置处理,得到转置矩阵;
29、将线性无关向量矩阵与转置矩阵的乘积进行特征分解,得到特征值和特征向量;
30、基于特征值和特征向量确定第一正交矩阵和第二正交矩阵;
31、基于线性无关向量矩阵、第一正交矩阵和第二正交矩阵构建奇异值矩阵。
32、本实施例提供的一种大语言模型训练方法,通过对线性无关向量矩阵进行奇异值分解,实现了对线性无关向量矩阵的向量维度的重要性判断,从数学层面上确定维度的冗余程度,为后续大语言模型的维度优化奠定了基础。
33、在一种可选的实施方式中,在获取多个文本数据,将多个文本数据输入训练收敛后的大语言模型,得到线性无关向量矩阵之前,还包括:
34、从预先设置的文本数据库中随机筛选多个样本数据,并将多个样本数据输入初始化后的大语言模型,得到输出向量矩阵;
35、对输出向量矩阵进行分解,并利用分解后的矩阵构建损失函数;
36、利用损失函数对大语言模型进行迭代训练,直至大语言模型达到收敛条件,停止迭代,得到训练收敛后的大语言模型。
37、本实施例提供的一种大语言模型训练方法,通过对初始化后的大语言模型对应的输出向量矩阵进行分解,利用分解后的矩阵构建损失函数,进而利用损失函数对大语言模型进行迭代训练,在训练模型时引入分解后的矩阵构建的损失函数,在此损失函数下训练模型,提升了输出向量矩阵的秩,实现了对大语言模型的初始训练,为后续大语言模型维度的优化奠定了基础。
38、在一种可选的实施方式中,对输出向量矩阵进行分解,并利用分解后的矩阵构建损失函数,包括:
39、基于输出向量矩阵,利用奇异值分解算法得到对角矩阵;
40、基于对角矩阵和预设截断值构建损失函数。
41、在一种可选的实施方式中,基于对角矩阵和预设截断值构建损失函数,损失函数的表达式如下所示:
42、
43、其中,表示损失函数。
44、在一种可选的实施方式中,对输出向量矩阵进行分解,并利用分解后的矩阵构建损失函数,包括:
45、对输出向量矩阵进行施密特正交化处理,得到矩阵特征值;
46、基于矩阵特征值和预设截断值构建损失函数。
47、第二方面,本发明提供了一种大语言模型,大语言模型为根据述第一方面或其对应的任一实施方式的大语言模型训练方法得到。
48、第三方面,本发明提供了一种大语言模型训练装置,该装置包括:
49、获取模块,用于获取多个文本数据,将多个文本数据输入训练收敛后的大语言模型,得到线性无关向量矩阵;
50、奇异值分解模块,用于对线性无关向量矩阵进行奇异值分解,得到奇异值矩阵;
51、确定模块,用于获取奇异值矩阵中大于预设截断值的奇异值数量,并基于大于预设截断值的奇异值数量确定线性无关向量矩阵的近似最大维度;
52、维度优化模块,用于基于线性无关向量矩阵的近似最大维度对大语言模型进行维度优化,得到大语言模型的实际输出向量维度;
53、模型训练模块,用于基于大语言模型的实际输出向量维度确定神经网络节点数,并对确定神经网络节点数的大语言模型进行模型训练,得到维度优化后的大语言模型。
54、第四方面,本发明提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的大语言模型训练方法。
55、第五方面,本发明提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的大语言模型训练方法。
56、第六方面,本发明提供了一种计算机程序产品,包括计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的大语言模型训练方法。
- 还没有人留言评论。精彩留言会获得点赞!