本发明属于机械故障诊断,具体是一种小样本下基于时频域对比学习的轴承故障诊断方法,能够在小样本条件下进行有效的故障分类。
背景技术:
1、工程中恶劣的工作环境和复杂的设备结构导致旋转设备有较高的故障率。故障一旦发生,往往难以及时有效地排除,安全和经济效益受到很大影响。近年来,随着现代制造业向数字化、智能化的方向快速发展,机械设备的智能运维与健康管理技术也得到了显著提升。深度学习作为一种强大的智能诊断工具,能够自动从海量数据中提取复杂特征,并在复杂机械系统的故障诊断中表现出卓越的准确性和鲁棒性。与传统的人工特征提取方法相比,深度学习不仅能够处理高维和多样化的数据,还可以通过其多层网络结构捕捉数据中的非线性关系和潜在特征,使得故障诊断的智能化水平显著提高。
2、然而,在实际的工业应用中,获取足够的标签故障数据仍然面临巨大挑战。许多企业的机械设备在正常运行时,故障数据稀缺,且故障数据的收集和标注成本高昂。尤其是在面对复杂或新型设备时,故障发生频率低,导致数据匮乏严重限制了传统有监督学习方法的应用。此外,数据不足的情况使得模型训练难度增加,通常无法在小样本情况下达到理想的故障分类效果。
3、为应对现有技术中标记样本不足带来的挑战,本发明提出了一种适用于小样本场景的基于时频域对比学习的故障诊断方法。该方法利用对比学习技术在无标签数据上进行预训练,充分挖掘时间域和频率域特征之间的对比一致性,从而增强模型的泛化能力和鲁棒性。通过在预训练阶段提取深层次的时频特征,模型在后续的微调过程中大大减少了对大量标记数据的依赖,能够在标记样本有限的情况下依然保持高效的故障诊断性能。这一解决方案在轴承故障诊断等工业应用中表现出极大的潜力,具有重要的应用前景。
技术实现思路
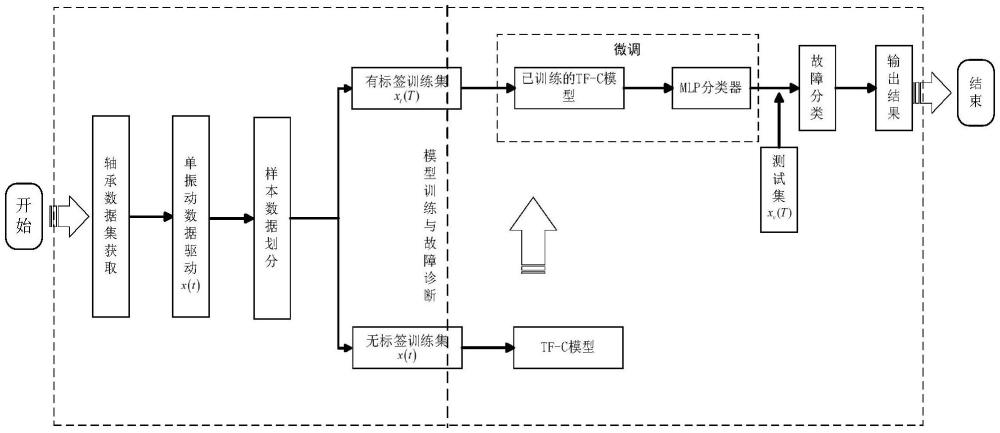
1、针对上述问题,本发明公开了一种小样本下基于时频域对比学习的轴承故障诊断方法。本发明的目的在于提供一种时频域对比学习模型构建方法,从而可以解决小样本数据条件下的轴承故障分类和诊断问题。
2、小样本下基于时频域对比学习的轴承故障诊断方法,所述方法包括如下步骤:
3、s1:采集滚动轴承振动加速度信号,并对采集到的信号进行预处理;
4、s2:构建时频域对比学习预训练故障诊断的网络模型;
5、s3:设计对比学习损失函数;
6、s4:模型微调与分类;
7、s5:性能评估。
8、进一步地,步骤s1具体为:
9、s1-1:对滚动轴承实际运行过程中的实测信号以及不同工况条件参数监测并获取实测振动数据x(t);
10、s1-2:对部分实测数据进行标记,形成有标签数据集x(t)。接着,将标记后的有标签数据集划分为微调训练集xt(t)和测试集xv(t),用于模型的微调训练和性能评估。
11、进一步地,步骤s2具体为:
12、s2-1:构建时间域编码器(gt)
13、时间域编码器(gt)首先将时间序列数据x(t)作为输入,通过多层卷积提取时间域特征ht,同时结合残差连接来提升深层网络的梯度传播能力。编码器还结合多种数据增强方法(如抖动、缩放等)生成不同的增强视图,使模型能够更好地适应多样化的输入,提升对噪声的抵抗能力和泛化能力。
14、s2-1-1:输入时间序列数据
15、输入为时间序列数据x(t),代表轴承振动信号在时间域中的原始数据。输入数据的维度为t×d,其中t是时间序列的长度,d是信号的通道数。输入数据可以是单通道或多通道,具体取决于信号的复杂性。
16、s2-1-2:构建卷积层与残差连接
17、时间域编码器使用多个卷积层提取时间序列的特征。每个卷积层通过卷积核w(l)和偏置项b(l)进行计算,捕捉局部时间序列模式。第l层的输出计算公式为:
18、
19、其中,当l=1时x(l)=x(t),×表示卷积操作,relu是激活函数。每个卷积层之后,使用池化层对特征图进行下采样,以减小特征图的尺寸,保留最显著的特征。假设使用最大池化,池化层的输出为:
20、
21、为了提高模型的特征提取能力,时间域编码器采用残差连接,允许跨层传递特征,以捕捉时间序列中的复杂变化。假设第l层卷积的输入为经过卷积和池化后的输出为pi(l),残差连接的输出为:
22、
23、残差连接允许在深层网络中更好地传播梯度,防止梯度消失,并且能够捕捉复杂的时间序列变化。编码器的输出是时间域特征向量ht,它是经过多层卷积和池化操作后的低维表示。经过l层卷积和池化后的输出为:
24、
25、s2-1-3:多视图数据增强机制
26、时间域编码器结合了多种数据增强方法,如抖动、缩放、时间偏移和邻域分段等。数据增强通过对时间序列数据x(t)进行随机扰动,生成多个不同的视图通过相同的卷积网络进行处理,生成增强的时间域特征向量:
27、
28、这种增强机制使得模型能够更好地适应多样化的输入数据,提高其对噪声的抵抗能力和泛化能力。
29、s2-2:构建频率域编码器(gf)
30、频率域编码器(gf)首先将时间序列数据x(t)转换为频率域表示x(f),利用频域分析的优势提取轴承振动信号的频率特征hf,即与时间域编码器类似,频率域编码器通过多层卷积提取特征,并结合残差连接和多种数据增强技术,以增强模型的特征提取能力、泛化能力以及对噪声的鲁棒性。
31、s2-2-1:输入频率域数据
32、使用时间序列数据x(t)进行快速傅里叶变换生成频谱数据x(f),并将x(f)作为频率域数据输入,输入数据的维度为n×d,其中n表示频率点的数量。不同于时间域的信号表示,频率域的数据能够反映出振动信号中的频率成分及其能量分布。
33、s2-2-2:构建卷积层与残差连接
34、频率域编码器(gf)与步骤s2-1-2中时间域编码器(gt)使用相同的卷积层和残差连接,其计算公式可以表示为:
35、fi(l)=relu(w(l)×fi(l-1)+b(l))
36、pi(l)=maxpool(fi(l))
37、ri(l)=pi(l)+fi(l-1)
38、
39、其中,当l=1时f(l)=x(f)。
40、s2-2-3:多视图数据增强机制
41、频率域编码器(gf)结合了多种频域数据增强方法,如频谱抖动、频率缩放、带通滤波和频段移位等。这些增强方法通过对频率域数据x(f)进行随机扰动,生成多个增强视图,然后通过相同的卷积网络处理,生成不同的增强频率域特征向量:
42、
43、这种多视图增强机制能够增强模型对不同频率特征的敏感性,使其适应频率域中不同噪声条件下的数据输入,提升对噪声的抵抗能力和泛化能力。
44、s2-3:构建域投影器(r)
45、域投影器(r)用于将时间域和频率域的特征映射到同一个空间z(假设存在一个潜在的时间-频率空间)中,以便在共享空间中进行对比特征学习。本发明设计了两个跨域投影器,分别为时间域投影器(rt)和频率域投影器(rf)。两个投影器均采用多层全连接网络,将高维的时间域和频率域特征分别映射到较低维度的嵌入空间,并通过批量归一化和非线性激活函数增强模型的表达能力。
46、s2-3-1:输入时间域与频率域特征
47、输入为从时间域编码器(gt)和频率域编码器(gf)提取的高维特征,分别为时间域特征ht、和频率域特征hf、。
48、s2-3-2:构建时域投影器和频域投影器
49、域投影器将时间域特征和频率域特征分别映射到共享空间z中。具体构建如下:
50、时域投影器(rt):采用全连接层对时间域编码器(gf)生成的特征向量ht和增强特征向量进行降维,生成嵌入向量zt、。投影后的共享域特征zt、表示为:
51、zt=relu(bn(linear(ht)))
52、
53、其中,linear表示全连接层,bn表示批量归一化操作。
54、频域投影器(rf):类似时域投影器(rt),频域特征hf、经过全连接层处理后,生成嵌入向量zf、:
55、zf=relu(bn(linear(hf)))
56、
57、进一步地,步骤s3具体为:
58、tf-c模型的核心是通过对比学习实现时频一致性。模型的目标是在自监督的框架下,通过最小化时间域和频率域表示之间的距离,来保证同一数据在两个域中的表示保持一致。在具体实现上,模型采用了对比损失函数来学习时频一致性。通过构造正样本对和负样本对,模型最大化正样本对的相似度,最小化负样本对的相似度。
59、s3-1:构建正样本对与负样本对
60、在tf-c模型中,为了实现时频一致性,正负样本对的构建是通过时间域和频率域的特征进行的,具体的样本对构造步骤如下:
61、s3-1-1:构建时间域样本对
62、(1)将同一条信号x(t)的时间域特征ht和时间域增强特征视为正样本对。该对旨在捕捉同一输入样本在不同时域增强下的相似特征。
63、
64、(2)从x(t)中提取不同样本的时间域特征ht,当i≠j时,被视为负样本对。该对旨在捕捉不同样本在时间域空间中的差异。
65、
66、s3-1-2:构建频率域样本对
67、(1)将同一条信号x(t)的频率域特征hf和频率域增强特征视为正样本对。该对旨在确保样本在频率域中与其频率域增强样本之间的特征一致性。
68、
69、(2)从x(t)中提取不同样本的频率域特征hf,当i≠j时,被视为负样本对。该对旨在捕捉不同样本在频率域空间中的特征差异。
70、
71、s3-1-3:构建时频一致性样本对
72、(1)为了确保时间域和频率域的嵌入具有一致性,使用域投影器(r)将时间和频率空间中的嵌入映射到一个联合时频空间z。对于每个输入样本xi(t),得到了四个嵌入:zit(时域嵌入)、(增强时域嵌入)、zif(频域嵌入)、和(增强频域嵌入)。
73、(2)将正样本对设置为和,这些对确保了在时频空间中原始样本和其增强样本的特征保持相似。
74、负样本对则为以及。这些对的样本来源于不同的输入样本或其增强视图,从而增加了模型对不同样本的辨识能力。
75、s3-2:构建对比损失函数
76、时间域对比损失lt用于确保时间域数据ht与其增强特征的一致性,公式为:
77、
78、频率域对比损失lf用于确保频率域数据hf与其增强特征的一致性,公式为:
79、
80、一致性损失lc用于确保同一数据的时间域表示zt和频率域表示zf在时频空间z中的距离最小化,公式为:
81、
82、其中,stf表示时间域表示zt和频率域表示zf之间的距离,spair表示其他增强样本对之间的距离,δ为常量,用于确保负样本对之间的距离较大。
83、s3-3:总损失函数的构建
84、模型通过联合优化时间域对比损失lt、频率域对比损失lf和时频一致性损失lc实现整体学习,公式为:
85、ltotal=λtlt+λflf+λclc
86、其中,λt、λf和λc为各损失项的权重系数。通过这样的设计和优化,tf-c模型能够从无标签数据中提取出时频一致的特征表示。这些特征在随后的微调阶段对小样本故障诊断任务具有极大的帮助。
87、进一步地,步骤s4具体为:
88、在预训练阶段完成后,模型已经学习到了时间域和频率域特征的一致性表示。接下来,将经过预训练的tf-c模型与多层感知器(mlp)分类器结合,利用小样本标记数据集x(t)对模型进行微调训练以便模型在特定任务上获得更好的性能,adam优化器将在微调过程中负责优化可训练参数。
89、s4-1:微调数据准备
90、在模型微调阶段,使用少量标记的轴承数据集x(t),该数据集包含不同故障类型的样本,每个样本附有故障标签。为了确保微调过程中模型的泛化能力和评估效果,将数据集x(t)划分为训练集xt(t)和测试集xv(t)。其中,训练集xt(t)用于模型的微调训练,测试集xv(t)用于验证模型的性能表现,防止模型过拟合并确保其在特定任务上的鲁棒性与准确性。
91、s4-2:使用标注训练集xt(t)
92、在微调过程中,模型通过标注数据集xt(t)中的标签信息,计算预测结果与实际标签之间的差异,得到损失值。对于本模型中的分类任务,使用交叉熵损失(cross-entropyloss):
93、
94、其中,是模型的预测概率,yi是真实标签的one-hot编码。
95、s4-3:冻结部分参数
96、在微调初期,为了保持模型的稳定性,通常会冻结时间域编码器gt和频率域编码器gf的部分参数,以保持预训练阶段学到的时频一致性特征不受影响。
97、s4-4:可调参数设置
98、在每次迭代中,adam优化器会根据计算出的损失函数值和梯度,对域投影器(r)和mlp分类器的参数进行更新。具体来说,优化器会使用梯度信息来调整权重w和偏置b,使得下一次迭代中的预测结果更接近真实标签。
99、adam的参数更新公式如下:
100、
101、其中,θt是当前参数,α是学习率,和分别为一阶和二阶矩估计的偏差修正值。
102、s4-5:设计mlp分类器
103、mlp分类器接收tf-c模型从训练数据集xt(t)提取的联合特征表示其中[;]表示向量的拼接操作。输入层接收联合特征zi,通过线性变换和非线性激活函数得到第1层的输出z1=relu(w1h+b1)。其中:w1是第1层的权重矩阵,b1是第1层的偏置向量。对于中间的每一层,第l层的输入为上一层的输出zl-1,经过线性变换和激活函数得到第l层的输出:zl=relu(wlzl-1+bl)。最后,在输出层进行分类预测,输出层通常使用softmax激活函数,以便输出类别的概率分布:y=softmax(wlzl-1+bl)。整个mlp分类器的过程可以表示为一系列线性变换和非线性激活函数的组合,最后通过softmax层将预测结果映射为概率分布,用于分类任务。
104、进一步地,步骤s5具体为:
105、在测试集xv(t)中对训练好的模型进行测试,评估其在不同工况、噪声环境下的故障诊断性能。
106、与现有技术相比,本发明具有以下效果:
107、分别设计时间域特征编码器和频率域特征编码器,以提取信号中的时间序列特征和频谱特征。在预训练阶段,通过对比学习,模型能够从大量无标签数据中自主学习时间域和频率域的深层特征表示,并利用域投影器将这些特征映射到一个共享的时频特征空间中,确保时间域与频率域特征的一致性。这一过程有效增强了特征的鲁棒性,使模型能够捕捉到数据中更深层的特征结构。预训练完成后,模型在小样本标记数据集上进行微调。此时,基于时频对比学习的预训练模型与多层感知机分类器结合,利用标记数据对模型进行端到端的优化训练。在微调过程中,模型通过梯度更新进一步调整其已学到的特征表示,使其更加适应具体的故障分类任务。最后,使用测试集对模型进行评估,以验证其在小样本场景下的故障分类性能。本发明通过时频对比学习预训练,使得模型能够在无监督条件下自主学习并提取数据中的深层特征。这一过程为模型提供了丰富的特征表示,使其在后续使用少量标记数据进行微调时,能够更有效地适应分类任务,从而显著提升了在小样本场景下的泛化能力和故障诊断精度。