优质词条的推荐方法、装置、存储介质以及电子设备与流程
本技术涉及多媒体智能处理,尤其涉及一种优质词条的推荐方法、装置、存储介质以及电子设备。
背景技术:
1、在现在的视频网站中,用户通过搜索查询入口输入少量的关键词(token)来查找想要观看的视频内容。当用户输入关键词后,系统会从召回源(corpus)中检索出与之相关的推荐词(query)列表。例如,当用户输入“天才”时,系统可能会推荐“天才枪手”、“天才眼镜狗”、“天才基本法”等相关内容。为了应对海量用户的搜索需求,视频网站需要构建一个庞大的词库(corpus),其中的词条数量通常达到百万级别。当前的词库主要由两部分组成:第一部分是站内资源的优质词条,例如ppc((professional produced content,长视频)、明星、角色等高质量词条;第二部分是用户主动搜索输入的词条。第一部分为优质词条,质量较高,能够准确反映用户需求。然而,用户主动输入的词条质量参差不齐,往往包含一些语法错误或拼写错误的低质量词条。例如“a电视剧2季”或“天才基本法则”之类的词条,可能是由于用户的输入法问题引起的。这些低质量词条由于高频次的搜索,被点击率预估模型错误地推荐给用户,从而浪费了宝贵的曝光机会。目前,针对词库中词条质量的判断方式主要有两种:一种是基于搜索频率阈值的方法,即如果一个query在特定时间段(如半年内)的搜索次数低于阈值,则会被过滤掉;另一种是通过正则化匹配的方式,利用大量的正则化模版或规则来过滤低质query。然而,这两种方法都有局限性。搜索频率阈值的方式可能会误过滤掉一些低频但优质的词条,而正则化模版和规则的覆盖面有限,容易将一些优质词条错误地处理为低质词条。此外,正则化方法对千变万化的低质词条处理效果不佳。总体而言,现有的方法难以有效过滤低质量的query,导致用户体验受到影响。
技术实现思路
1、本技术提供了一种优质词条的推荐方法、装置、存储介质以及电子设备,以解决难以有效过滤低质量推荐词条的技术问题。
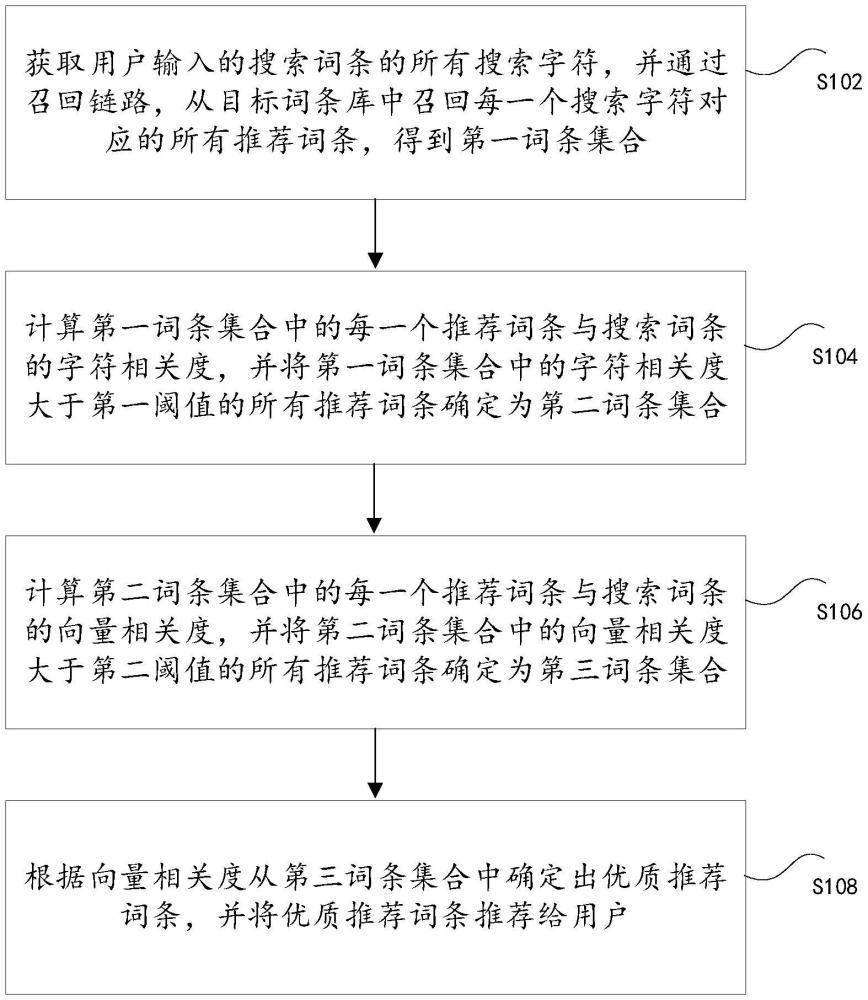
2、第一方面,本技术提供了一种优质词条的推荐方法,包括:获取用户输入的搜索词条的所有搜索字符,并通过召回链路,从目标词条库中召回每一个上述搜索字符对应的所有推荐词条,得到第一词条集合;计算上述第一词条集合中的每一个推荐词条与上述搜索词条的字符相关度,并将上述第一词条集合中的上述字符相关度大于第一阈值的所有推荐词条确定为第二词条集合;计算上述第二词条集合中的每一个推荐词条与上述搜索词条的向量相关度,并将上述第二词条集合中的上述向量相关度大于第二阈值的所有推荐词条确定为第三词条集合;根据上述向量相关度从上述第三词条集合中确定出优质推荐词条,并将上述优质推荐词条推荐给上述用户。
3、第二方面,本技术提供了一种优质词条的推荐装置,包括:获取模块,用于获取用户输入的搜索词条的所有搜索字符,并通过召回链路,从目标词条库中召回每一个上述搜索字符对应的所有推荐词条,得到第一词条集合;第一计算模块,用于计算上述第一词条集合中的每一个推荐词条与上述搜索词条的字符相关度,并将上述第一词条集合中的上述字符相关度大于第一阈值的所有推荐词条确定为第二词条集合;第二计算模块,用于计算上述第二词条集合中的每一个推荐词条与上述搜索词条的向量相关度,并将上述第二词条集合中的上述向量相关度大于第二阈值的所有推荐词条确定为第三词条集合;确定模块,用于根据上述向量相关度从上述第三词条集合中确定出优质推荐词条,并将上述优质推荐词条推荐给上述用户。
4、作为一种可选的示例,上述装置还包括:处理模块,用于在获取用户输入的搜索词条的所有搜索字符,并通过召回链路,从目标词条库中召回每一个上述搜索字符对应的所有推荐词条,得到第一词条集合之前,将上述目标词条库中的每一个推荐词条作为当前推荐词条,对上述当前推荐词条执行如下操作:获取上述当前推荐词条的所有推荐字符;构建每一个上述推荐字符到上述当前推荐词条的召回链路。
5、作为一种可选的示例,上述第一计算模块包括:第一处理单元,用于将上述第一词条集合中的每一个推荐词条作为当前推荐词条,对上述当前推荐词条执行如下操作:获取上述当前推荐词条与上述搜索词条共有的字符的第一数量;获取上述当前推荐词条与上述搜索词条中的所有独特字符的第二数量;计算上述第一数量与上述第二数量的商,得到上述当前推荐词条与上述搜索词条的字符相关度。
6、作为一种可选的示例,上述第二计算模块包括:第二处理单元,用于将上述第二词条集合中的每一个推荐词条作为当前推荐词条,对上述当前推荐词条执行如下操作:获取上述当前推荐词条的第一向量;获取上述搜索词条的第二向量;计算上述第一向量和上述第二向量的余弦相似度,得到上述当前推荐词条与上述搜索词条的向量相关度。
7、作为一种可选的示例,上述确定模块包括:排序单元,用于将上述第三词条集合中的所有推荐词条根据与上述搜索词条的向量相关度从大到小进行排序,得到排序后的第四词条集合;确定单元,用于将上述第四词条集合中的前目标数量的推荐词条确定为上述优质推荐词条。
8、作为一种可选的示例,上述装置还包括:第一构建模块,用于在获取用户输入的搜索词条的所有搜索字符,并通过召回链路,从目标词条库中召回每一个上述搜索字符对应的所有推荐词条,得到第一词条集合之前,构建初始词条库,其中,上述初始词条库中包括多个用户输入的多个搜索词条;识别模块,用于将上述初始词条库中的每一个词条输入至目标大语言模型,识别上述初始词条库中的每一个词条的语法问题,得到上述初始词条库中的每一个词条的识别结果;删除模块,用于将上述初始词条库中的目标词条删除,得到上述目标词条库,其中,上述目标词条的识别结果为存在语法问题。
9、作为一种可选的示例,上述装置还包括:第二构建模块,用于在将上述初始词条库中的每一个词条输入至目标大语言模型之前,根据上述初始词条库,构建训练数据和验证数据;输入模块,用于将上述训练数据输入至初始大语言模型,得到上述训练数据的结果数据;第三计算模块,用于使用损失函数计算上述结果数据与上述验证数据之间的差异,得到损失值;第四计算模块,用于根据上述损失值调整上述初始大语言模型的模型参数,并重新计算上述损失值,直到重新计算的上述损失值小于目标阈值,得到上述目标大语言模型。
10、第三方面,本技术提供了一种存储介质,该存储介质中存储有计算机程序,其中,该计算机程序被处理器运行时执行上述优质词条的推荐方法。
11、第四方面,本技术还提供了一种电子设备,包括存储器和处理器,上述存储器中存储有计算机程序,上述处理器被设置为通过所述计算机程序执行上述的优质词条的推荐方法。
12、在本技术实施例中,采用了获取用户输入的搜索词条的所有搜索字符,并通过召回链路,从目标词条库中召回每一个上述搜索字符对应的所有推荐词条,得到第一词条集合;计算上述第一词条集合中的每一个推荐词条与上述搜索词条的字符相关度,并将上述第一词条集合中的上述字符相关度大于第一阈值的所有推荐词条确定为第二词条集合;计算上述第二词条集合中的每一个推荐词条与上述搜索词条的向量相关度,并将上述第二词条集合中的上述向量相关度大于第二阈值的所有推荐词条确定为第三词条集合;根据上述向量相关度从上述第三词条集合中确定出优质推荐词条,并将上述优质推荐词条推荐给上述用户的方法,由于在上述方法中,将用户输入的搜索词条被拆分为字符,并从词条库中检索出与这些字符匹配的所有推荐词条,形成第一词条集合。然后计算每个词条与搜索词条的字符相关度,筛选出相关度高于第一阈值的词条,形成第二词条集合。再计算第二词条集合中每个词条与搜索词条的向量相关度,筛选出相关度高于第二阈值的词条,形成第三词条集合。最后,根据向量相关度对第三词条集合中的推荐词条进行排序,推荐最相关的优质词条给用户。从而实现了多层次筛选提高推荐词条的精度和质量,优化用户搜索体验的目的,进而解决了难以有效过滤低质量推荐词条的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!