一种基于语义实例生成的零样本开放词汇场景理解方法与流程
本发明涉及计算机视觉,尤其是涉及一种基于语义实例生成的零样本开放词汇场景理解方法。
背景技术:
1、零样本开放词汇3d场景理解任务(training-free open-vocabulary 3d sceneunderstanding)旨在对场景中存在物体的语义和空间关系进行建模,进而赋能物体检索、目标导航等下游任务。一些方法通过在特定场景上进行训练实现了固定词汇的场景理解,缺乏对新场景和丰富语义的泛化能力。
2、近年来,多种视觉基础模型和多模态大模型的发展促进了零样本开放词汇3d场景理解的进步,然而,现有技术主要存在如下缺点:
3、(1)3d实例分割不准确。当前的视觉语言模型(vlms)在处理复杂场景时,常常会出现物体的过度分割或不足分割,同时,扫描序列中存在大量只有部分被观测的物体,这些问题最终影响3d实例的准确建模。
4、(2)特征聚合不准确。现有方法通常对每个实例的一组2d语义特征进行聚合,其忽略了不同实例之间的特征关系,从而无法对细粒度语义进行区分。
5、(3)空间表示效率低。现有方法通常使用点云来表征3d空间,但点云在大规模场景中占用大量存储空间,并且需要额外计算才能支持空间占用查询和路径规划。一些方法使用网格或体素简化空间表示,但无法精确描述场景。
6、综上,当前缺少一种零样本开放词汇场景理解方法,以解决或部分解决前述问题。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于语义实例生成的零样本开放词汇场景理解方法,以解决或部分解决3d实例的建模不准确、空间表示效率低的问题。
2、本发明的目的可以通过以下技术方案来实现:
3、本发明的一个方面,提供了一种基于语义实例生成的零样本开放词汇场景理解方法,包括如下步骤:
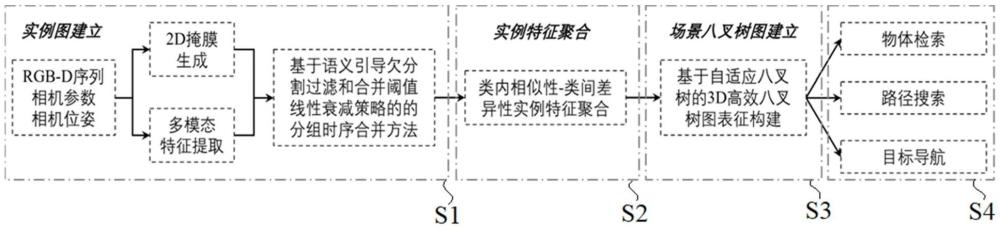
4、步骤s1,获取包括深度信息的多帧图像数据,针对每一帧图像数据,通过分割得到2d掩模信息,通过对2d掩模进行语义特征提取并投影到3d空间,得到3d点云片段,采用语义引导的欠分割过滤和合并阈值线性衰减策略,通过时序分组合并将3d点云片段合并为3d实例,得到3d实例集合;
5、步骤s2,针对所述3d实例集合中每个实例的语义特征,在考虑类内相似度和类间差异性的前提下,进行特征聚合处理;
6、步骤s3,基于特征聚合后的3d实例集合,将每个3d实例作为图节点,将步骤s2中聚合后的特征作为3d实例的语义信息,利用目标形状和尺寸自适应的混合八叉树表征3d实例的空间占据信息,利用节点间的边表征不同3d实例间的空间关系,构建混合八叉树-图结构,实现零样本开放词汇场景理解。
7、作为优选的技术方案,所述的步骤s1中,针对每一帧图像数据,通过分割得到2d掩模信息,通过对2d掩模进行语义特征提取并投影到3d空间,得到3d点云片段的过程包括如下步骤:
8、步骤s101,针对每一帧图像数据,利用预训练的分割模型得到多个2d掩模;
9、步骤s102,利用预训练的视觉语言模型生成每个2d掩模对应的语义特征;
10、步骤s103,基于相机参数和相机位姿,将2d掩模投影至3d空间,得到3d点云片段。
11、作为优选的技术方案,所述的步骤s1中,采用语义引导的欠分割过滤和合并阈值线性衰减策略,通过时序分组合并将3d点云片段合并为3d实例集合的过程包括如下步骤:
12、步骤s104,时序分组:将待合并的3d点云片段根据所处时间帧划分为n组,将第一组3d点云片段作为当前轮次的待合并点云片段集合;
13、步骤s105,针对当前轮次的待合并点云片段集合,计算任两个点云片段间的空间相似度和语义相似度;
14、步骤s106,语义引导的欠分割过滤:针对当前轮次的待合并点云片段集合中的每一个包含子3d点云片段的父3d点云片段,若该父3d点云片段与其包含的子3d点云片段的语义相似度之间的方差大于预设值,则删除该父3d点云片段;
15、步骤s107,合并阈值线性衰减策略:针对语义引导的欠分割过滤后的待合并点云片段集合,选取空间相似度和/或语义相似度高于阈值的3d点云片段进行迭代合并,得到当前轮次合并后的中继实例集合,其中,随迭代轮次的增加,所述阈值减小;
16、步骤s108,将当前的中继实例集合中的实例和下一组3d点云片段的并集作为新的待合并点云片段集合,执行步骤s105,在n次迭代后得到最终的3d实例集合。
17、作为优选的技术方案,所述的空间相似度包括两个3d点云片段的交并比,所述的语义相似度为两个3d点云片段对应地语义特征的余弦相似度。
18、作为优选的技术方案,所述的步骤s2中,在考虑类内相似度和类间差异性的前提下,通过特征聚合得到合并后的3d实例集合的过程包括如下步骤:
19、步骤s201,针对3d实例集合中的每一个实例,通过反投影得到实例关联的2d掩模集合,重新计算语义特征;
20、步骤s202,针对每个实例关联的2d掩模集合进行主特征簇抽取,计算主特征簇对应的中心特征,并根据中心特征计算出每个实例的邻居实例;
21、步骤s203,针对每个实例关联的每个2d掩模,计算2d掩模对应的语义特征与所属实例中心特征相似度减去其与所有邻居实例中心特征相似度的差值作为动态权重,通过聚合得到聚合后的3d实例集合。
22、作为优选的技术方案,所述的步骤s3中,图结构包括节点和边,其中,所述的节点包括物体的语义信息、目标形状和尺寸自适应的八叉树和物体的中心坐标,所述的边包括节点之间空间关系的语义、节点之间的欧氏距离和节点之间的三维方向向量。
23、作为优选的技术方案,所述的目标形状和尺寸自适应的八叉树中,树结构的体素的形状与物体的形状匹配。
24、本发明的另一个方面,提供了一种目标查询方法,包括如下步骤:
25、步骤s1,获取采用前述基于语义实例生成的零样本开放词汇场景理解方法得到的图结构;
26、步骤s2,获取用户指令信息,利用大语言模型提取语义信息和方位信息,利用所述图结构查询得到目标,并返回目标的信息。
27、本发明的另一个方面,提供了一种路径搜索方法,包括如下步骤:
28、步骤s1,获取采用前述基于语义实例生成的零样本开放词汇场景理解方法得到的图结构;
29、步骤s2,获取目标查询点的信息,在所述图结构的节点中进行粗粒度查询,得到包括所述查询点的节点;
30、步骤s3,在所述节点包括的八叉树中递归查询所述目标查询点的位置是否有障碍物,并返回查询结果,实现路径搜索。
31、本发明的另一个方面,提供了一种电子设备,包括:一个或多个处理器以及存储器,所述存储器内储存有一个或多个程序,所述一个或多个程序包括用于执行前述基于语义实例生成的零样本开放词汇场景理解方法的指令。
32、与现有技术相比,本发明至少具有以下有益效果之一:
33、(1)有效缓解物体分割不准的问题:本发明通过采用语义引导的欠分割过滤和合并阈值线性衰减策略,通过时序分组合并将3d点云片段合并为3d实例集合,相对于现有技术缓解了实例的分割不准的问题。
34、(2)下游任务表现好:本发明在考虑类内相似度和类间差异性的前提下,通过特征聚合得到聚合后的3d实例集合,同时考虑实例特征的类内相似性和类间差异性,本发明为每个实例聚合出更具有区分性的语义特征,提升下游任务的性能。
35、(3)空间表示效率高:本发明基于聚合后的3d实例集合,构建包括目标形状和尺寸自适应的八叉树的图结构,实现零样本开放词汇场景理解,通过构建了一个存储高效的八叉树-图结构来对3d场景中实例的语义和空间占用进行表征,有效提高了空间表示效率。
- 还没有人留言评论。精彩留言会获得点赞!