基于弹性自适应增量学习的大模型云计算动态更新方法
本发明涉及大模型,尤其涉及一种基于弹性自适应增量学习的大模型云计算动态更新方法。
背景技术:
1、现有技术中,随着大模型的广泛应用,大模型的动态更新和维护成为了云计算环境下的一个重要问题,大模型通常需要处理海量数据,并通过频繁的训练和更新来提升性能,然而,现有的大模型更新方法往往依赖于对整个大模型的重新训练,这在云计算环境中带来了严重的资源浪费问题,首先,重新训练整个大模型意味着需要大量的计算资源,当数据量持续增长时,传统的全局训练方式无法有效应对这种增长导致云计算资源的占用率和能耗持续攀升,此外,由于全大模型训练需要较长时间,更新过程中的时延也较为明显,无法满足某些实时性要求较高的应用场景。
2、针对大模型的增量学习技术虽然能够在一定程度上缓解重新训练的资源消耗问题,但现有的增量学习方法通常只对固定数据结构或特定场景有效,当数据分布发生明显变化时,大模型的更新策略难以自适应调整,导致大模型的预测精度和鲁棒性大幅降低。同时,现有技术中的云端资源调度往往依赖于静态的资源分配策略,未能结合实时的任务负载和系统资源使用情况进行动态调整,导致计算资源无法得到最优的利用,部分计算节点资源过载,而另一些节点资源闲置,造成资源分配不平衡的现象。
3、此外,现有的大模型更新方法缺乏灵活性,通常需要在大模型更新过程中保持各计算节点的同步,这不仅增加了系统的复杂性,还降低了更新效率,尤其在大规模的分布式云计算环境中,任务的并行调度和异步执行是提高系统性能的关键,然而现有技术的同步机制无法充分发挥云端多节点的协同计算优势,进而影响了整体系统的运作效率。
4、综上所述,现有技术在大模型更新方面存在以下问题:一是大模型全局重新训练带来的资源浪费和时延问题;二是增量学习机制在应对动态数据变化时的自适应性不足;三是云计算资源调度策略缺乏实时动态调整能力,无法充分利用云端资源;四是现有的同步更新方法降低了多节点并行执行的效率,限制了系统性能的提升。
技术实现思路
1、本发明的一个目的在于提出一种基于弹性自适应增量学习的大模型云计算动态更新方法,本发明在大规模云计算环境中能够充分利用闲置的计算资源,使得计算任务均衡分配,并确保任务负载的动态调整。
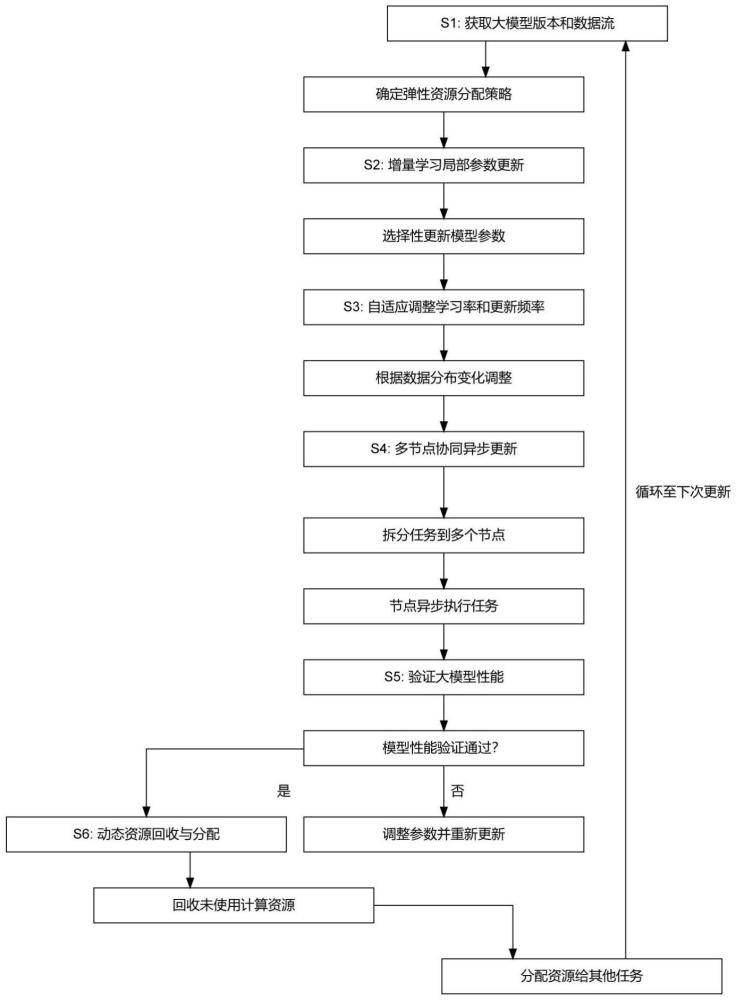
2、根据本发明实施例的一种基于弹性自适应增量学习的大模型云计算动态更新方法,包括如下步骤:
3、s1、在云计算平台中,获取大模型的当前版本和待处理的新数据流,根据大模型当前的任务负载和系统资源情况,确定弹性资源分配策略;
4、s2、采用增量学习机制,在不重新训练整个大模型的情况下,针对新数据对大模型进行局部参数更新,更新过程中根据数据的特征动态选择需要更新的参数或模型层;
5、s3、引入自适应学习策略,实时监测数据分布的变化情况,并根据数据变化自动调整模型的学习率、参数结构和更新频率;
6、s4、在大模型更新的过程中,通过云端的多节点协同调度机制,将大模型更新任务拆分至多个计算节点并行执行,各节点根据各自的任务进度进行异步更新;
7、s5、完成大模型更新后,系统对大模型的性能进行验证,若性能达到预设阈值,则保存并部署更新后的大模型版本,若性能未达到,则调整参数并重新进行更新迭代;
8、s6、在大模型更新部署过程中,系统动态回收不再使用的计算资源。
9、可选的,所述s1步骤包括:
10、s11、在云计算平台中,获取大模型的当前版本mt和待处理的新数据流dnew,基于云计算平台的资源调度机制对新数据流dnew进行预处理;
11、s12、根据大模型当前任务lt和系统可用资源rt确定弹性资源分配策略,大模型当前任务负载lt通过对当前大模型的处理速度vt、内存占用mt和任务队列长度qt参数进行综合评估,大模型当前任务负载计算如下:
12、
13、其中,vmax、mmax、qmax分别表示系统处理速度、内存占用和任务队列长度的最大值,α1、α2、α3为任务负载的权重系数,分别对应不同资源的权重;
14、实时监控云计算平台中可用资源rt,包括可用cpu核心数cput、gpu可用性能gput和内存可用容量ramt:
15、
16、其中,cput、gput和ramt分别为系统当前的cpu核心数、gpu性能和内存容量,cpumax、gpumax和rammax为这些资源的最大可用量,β1、β2、β3为对应的资源权重,反映各资源在系统可用资源中的相对贡献;
17、s13、基于大模型当前任务负载lt与系统可用资源rt的关系,采用自适应分配策略f(lt,rt)动态调整资源的分配比例:
18、
19、其中,ralloc为分配给大模型更新过程的计算资源,lthr表示任务负载的阈值,β为自适应系数,控制资源分配对任务负载变化的敏感度,γ为平滑因子,rt-1为上一时间步的分配资源量,rmax为系统最大资源量;
20、s14、根据弹性资源分配策略将所分配的计算资源ralloc用于大模型更新过程中的数据预处理、参数调整和大模型结构优化。
21、可选的,所述s2步骤包括:
22、s21、基于增量学习机制获取新数据流dnew的特征向量xnew,将特征向量与大模型当前参数矩阵wt进行比较,根据相似度函数s(xnew,wt)计算特征与大模型参数的相似度:
23、
24、其中,xnew为新数据的特征向量,wt为大模型当前的参数矩阵,∥·∥表示向量的范数运算;
25、s22、根据相似度计算结果确定需要更新的大模型部分参数wupdate,当相似度s(xnew,wt)小于设定的阈值δ时,选择与新数据特征关联的参数层或大模型结构进行局部更新;
26、s23、对选中的大模型参数wupdate进行增量学习更新,采用自适应学习率ηt通过梯度下降法更新大模型参数:
27、
28、其中,为当前大模型的损失函数相对于大模型参数wt的梯度,学习率ηt根据数据流变化和大模型收敛速度动态调整;
29、s24、完成增量学习更新后,系统对更新后的大模型参数wt+1进行验证,使更新部分在不重新训练整个大模型的前提下进行大模型性能的提升。
30、可选的,所述s3步骤包括:
31、s31、实时监测新数据流dnew的分布情况,获取新数据的均值μnew和标准差σnew,并将其与大模型当前数据分布的均值μt和标准差σt进行比较,监测数据分布的变化情况;
32、s32、基于数据分布的变化率δμ和δσ动态调整大模型的学习率ηt和更新频率ft;
33、s33、根据数据分布变化率δμ和δσ,采用自适应学习策略调整学习率ηt,学习率的调整规则为:
34、
35、其中,α为自适应系数,控制学习率对数据分布变化的敏感度;
36、s34、调整大模型的更新频率ft,根据数据变化的幅度设置更新的周期,若δμ和δσ超过预设阈值∈,则提高更新频率:
37、
38、其中,β为更新频率的自适应调整系数;
39、s35、基于调整后的学习率ηt+1和更新频率ft+1,对大模型进行动态更新。
40、可选的,所述s4步骤包括:
41、s41、在大模型更新过程中,获取云端可用的计算节点数量n及其对应的计算能力ci,计算能力ci由节点的cpu核心数cpui、gpu性能gpui和可用内存rami综合计算:
42、
43、其中,α、β、γ分别为cpu、gpu和内存的权重系数,反映各资源对计算能力的贡献,用平方根形式表示内存资源对计算的非线性贡献,i表示第i个计算节点;
44、s42、将大模型的更新任务拆分为tj个子任务,每个子任务对应的计算复杂度lj由参数矩阵的维度wj和需要执行的梯度运算计算得出,节点任务分配策略基于节点的计算能力ci和任务复杂度lj,其负载均衡在考虑时间约束和剩余资源的情况下,动态分配任务:
45、
46、其中,ti为节点当前已经消耗的时间,tmax为允许的最大处理时间,ri表示节点i当前剩余资源,rtotal为所有节点的总剩余资源;
47、s43、各个节点根据分配的任务tj和大模型参数wj进行异步更新,每个节点独立计算子任务梯度更新:
48、
49、其中,ηj为学习率,为对应的梯度计算,更新过程中通过控制学习率的自适应调整;
50、s44、实时监控各节点的任务进度pi,当某个节点完成任务后,重新评估剩余任务的计算复杂度lremain和节点剩余计算能力cremain;
51、s45、所有子任务完成后,系统将各节点更新的参数wj合并,生成更新后的大模型参数矩阵wt+1:
52、
53、可选的,所述s5步骤包括:
54、s51、在大模型更新完成后,获取更新后的大模型版本mt+1,通过预设的性能指标ptarget对大模型的性能进行验证,性能指标包括模型的精度at+1、计算效率et+1和资源占用率rt+1:
55、
56、其中,α、β、γ为不同性能指标的权重,at+1为模型的精度,et+1为计算效率,rt+1为资源占用率,rmax为最大允许的资源使用量;
57、s52、将验证结果pt+1与预设阈值ptarget进行比较,若pt+1≥ptarget,则保存并部署更新后的大模型版本mt+1,将其替换为当前运行的大模型版本;
58、s53、若pt+1<ptarget,则调整大模型的相关参数,重新设置模型的学习率η、更新频率f和参数矩阵w;
59、s54、在参数调整完成后,系统重新执行更新流程直到模型性能指标pt+1达到或超过预设阈值ptarget,并最终部署更新后的大模型版本。
60、可选的,所述s6步骤包括:
61、s61、在大模型更新部署完成后,系统监控云计算平台上各计算节点的资源利用率ui;
62、s62、对所有计算节点进行资源回收评估,若某节点的资源利用率ui低于预设阈值umin,则系统启动动态资源回收机制,将未充分使用的计算资源释放回云平台供其他任务使用:
63、
64、其中,为第i个节点在更新过程中使用的计算资源,为节点的总计算资源;
65、s63、动态调整各计算节点的资源分配策略,根据回收的空闲资源对其他高负载节点进行资源调配;
66、s64、在资源回收过程中,系统实时监控云平台的整体资源利用率utotal,当utotal达到预设的高效利用率阈值uopt时,停止资源回收,根据资源回收后的利用情况,系统重新评估大模型的计算资源需求,调整未来模型更新过程中资源分配的优先级和调度策略。
67、本发明的有益效果是:
68、(1)本发明采用弹性自适应增量学习机制,在不重新训练整个大模型的情况下,针对新数据对大模型的部分参数或大模型层进行局部更新,相比于传统的全局更新方法,本发明通过实时监测数据分布的变化,并根据自适应调整大模型的学习率和更新频率,使得大模型能够快速响应数据变化,提高了大模型的适应性和更新效率,通过增量学习策略,系统能够选择性地更新大模型参数,从而大幅降低计算资源的占用量,实验结果显示,相比传统全局更新方式在云计算环境下的资源占用率降低了31.2%,大模型训练时间缩短了50%以上。
69、(2)本发明结合云计算平台的多节点协同调度机制,将大模型更新任务拆分为多个子任务,并行地分配至多个计算节点执行,且各节点根据任务进度异步更新大模型参数,与传统同步更新方法相比,本发明通过异步调度机制避免了节点间的通信延迟和同步瓶颈问题,显著提升了并行计算的效率,在大规模云计算环境中能够充分利用闲置的计算资源,使得计算任务均衡分配,并确保任务负载的动态调整。
70、(3)本发明通过引入动态资源监控与回收机制实时监控云端计算资源的利用率,并在大模型更新完成后,动态回收不再使用的计算资源,确保云计算平台的高效运行,与现有技术中静态资源分配策略相比,本发明的动态资源管理机制能够根据任务的实际需求灵活调整资源的分配和回收,防止资源的过度占用和浪费,通过这种优化策略,系统在任务高峰期资源利用率提升了20%,且在任务完成后能够快速回收闲置资源,整体资源利用效率提高了15%,为大规模数据处理和大模型训练提供了更为可靠和高效的计算支持。
- 还没有人留言评论。精彩留言会获得点赞!