基于WGAN-GP与SuperLearner集成学习的碳纳米管膜性能预测方法
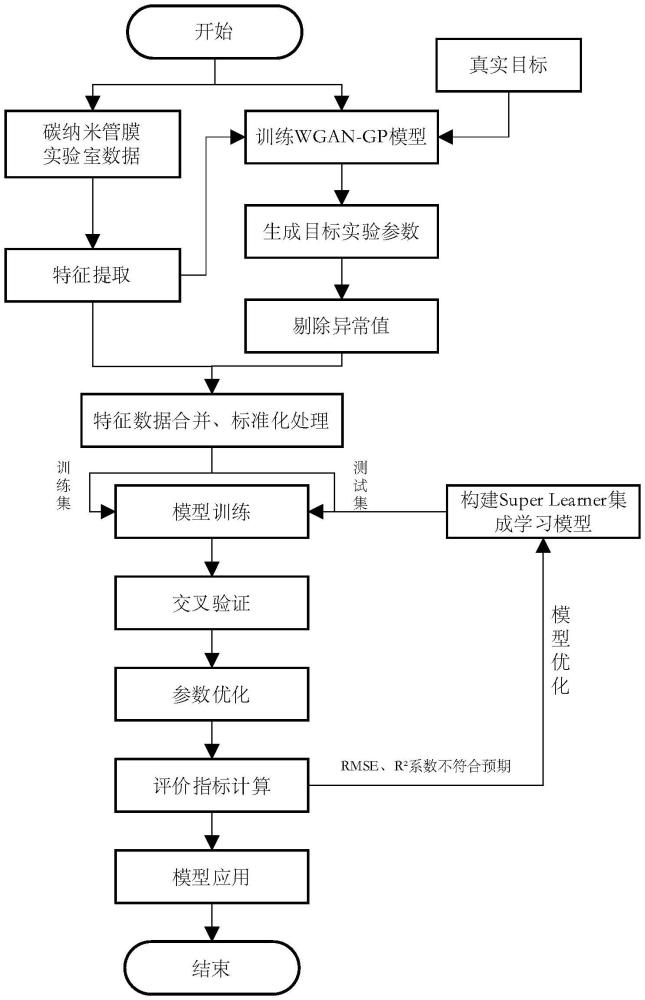
本发明涉及碳纳米管膜性能预测领域,尤其是一种基于生成对抗网络(wgan-gp)与super learner集成学习的碳纳米管膜水渗透性能预测方法。该方法通过对碳纳米管膜水渗透实验数据进行扩展和优化,结合多种机器学习算法,能够有效预测碳纳米管膜在不同条件下的水渗透性能,属于材料科学、纳米技术和机器学习的交叉领域。
背景技术:
1、碳纳米管膜在水处理、过滤和膜分离技术中的应用前景广阔,尤其是在水渗透性能方面,碳纳米管膜凭借其优异的纳米级通道结构和高通量特性,逐渐成为研究和应用的热点。然而,由于碳纳米管膜在不同的制备条件、操作环境和使用工况下表现出不同的渗透性能,如何准确预测其水渗透性能成为关键问题。目前,水渗透性能的预测主要依赖于实验数据和物理模型,但由于实验数据采集成本高、实验周期长,且在实验中往往只能获得小规模样本,现有方法在面对复杂的工况和小样本数据时存在精度不足、适用性差等问题。
技术实现思路
1、本发明为解决背景技术中存在的问题,通过结合有限实验数据,并结合多种机器学习算法进行性能预测,以期提高模型的预测准确性。该方法通过对数据的挖掘和建模,有效提高了小样本数据下的预测能力。本发明的技术方案是这样实现的:
2、本发明提供了一种基于wgan-gp与super learner集成学习的碳纳米管膜水渗透性能预测方法,旨在解决现有技术中由于样本量不足导致的性能预测不准确问题。通过生成对抗网络(wgan-gp)对原始实验数据进行扩展,并结合super learner模型对碳纳米管膜的水渗透性能进行高精度预测。本发明在碳纳米管膜的水渗透性能预测领域具有显著的提升,特别是在小样本数据集条件下,通过数据扩展与集成学习模型的结合,显著提高了预测的精度与稳定性。
3、为了达到上述目的,本发明的技术方案是这样实现的:
4、一种基于wgan-gp与super learner集成学习的碳纳米管膜性能预测方法,包括如下步骤:
5、步骤一:基于碳纳米管膜实验数据构建数据集并进行特征提取;构建wgan-gp生成对抗网络模型,通过梯度惩罚优化生成器和判别器的网络结构,确保模型的有效性。
6、步骤二:使用训练好的wgan-gp模型生成新的数据集,并且对新生成数据集进行预处理,并将处理后的数据与原数据集合并,再进行训练集与测试集的划分。
7、步骤三:利用super learner集成学习模型,分别构建包含多个基学习器和元学习器的两层回归架构,针对扩展数据集进行模型训练和参数优化。
8、步骤四:根据模型评估指标,对super learner模型进行性能评估,并利用训练好的模型对待检测的碳纳米管膜性能数据进行预测,输出预测结果。
9、优选的,基于碳纳米管膜的实验数据,构建生成对抗网络模型wgan-gp,其中生成器用于生成新的合成数据,判别器用于区分生成数据与真实数据,通过引入梯度惩罚优化wasserstein距离,以确保判别器满足lipschitz连续性,避免梯度消失或爆炸现象;使用wgan-gp生成额外的合成数据用于扩充数据集,将生成的数据与原始实验数据结合,形成一组新的数据集。
10、优选的,所述wgan-gp生成对抗网络的生成器为多层全连接神经网络,输入为从标准正态分布中采样的噪声向量,网络中的每一隐藏层使用relu激活函数,表达式为hi=max(0,wihi-1+bi),其中wi为权重矩阵,bi为偏置向量,hi为每层的输出;输出层使用softplus激活函数softplus(x)=ln(1+ex),x为是生成器网络输出的中间结果,以确保生成数据为正值,符合碳纳米管膜的物理特性;生成器通过最小化损失函数其中为生成数据,为判别器对生成数据的评估值,e为对于噪声分布z取期望值,更新网络参数,使生成数据逐渐逼近真实数据分布。
11、优选的,所述生成对抗网络的训练过程中,使用了梯度惩罚项以确保判别器的lipschitz连续性。判别器结构为多层神经网络,每层采用leakyrelu激活函数leakyrelu(x)=max(0.01x,x),该激活函数有效防止梯度消失问题。此外,判别器在每次权重更新时通过最小化损失函数:其中,λ为梯度惩罚项的权重超参数,为真实数据与生成数据之间的插值点,α~u(0,1),且为判别器对插值点的梯度,通过该方式确保lipschitz约束,提升生成器的生成质量。
12、优选的,生成的数据和原始实验数据首先经过标准化处理,使其具备相同的尺度,接着应用分位数截断法去除异常值。具体操作为,通过计算数据的上下边界分位数(如1%和99%),去除位于该范围之外的极端数据点,从而确保数据分布的合理性。清理后的数据集将用于后续的模型训练和性能预测,以提高模型的泛化能力和预测精度。
13、优选的,使用基于super learner的集成学习模型对碳纳米管膜的性能进行预测,所述super learner模型包含多个基学习器和元学习器。第一层基学习器包括;随机森林回归模型,其通过构建多棵决策树并集成预测结果,最终预测值为所有树的平均值公式为其中n为决策树的数量,hi(x)为第i棵树的预测结果;xgboost回归模型,通过迭代更新残差,最小化目标函数该目标函数包含两部分:损失函数和正则化项。第一部分是计算模型的预测误差,n表示训练数据集中的样本数量,yi是第i个样本的真实值;是模型对第i个样本的预测值;为第t轮的损失函数。第二部分是对模型复杂度的惩罚,其中t表示当前迭代的轮数,ω(fk)为第k棵树的正则化项;lightgbm回归模型,通过基于直方图的梯度提升树算法优化数据分布和训练效率;
14、第二层基学习器包括;高斯过程回归模型,采用核函数计算数据协方差,用于建模碳纳米管膜性能的非线性关系,其中l为长度尺度超参数,x和x′为特征变量m支持向量回归模型svr,其优化目标为其中w是权重向量,代表支持向量回归模型中用于定义模型的参数向量,c为惩罚系数,控制模型对误差的容忍度与正则化之间的平衡,n是训练样本的数量,yi是第i个样本的真实值,f(xi)为模型的预测函数,表示支持向量回归模型对输入xi的预测值,∈是精度阈值,其定义了一个不需要惩罚的误差范围,max(0,|yi-f(xi)|-∈)表示为计算每个样本i的损失,损失是当预测误差|yi-f(xi)|超过∈时才会被计算,如果预测值f(xi)离真实值yi的误差小于∈,则该项为零,不进行惩罚,如果误差大于∈,则超出∈的部分会被加到总损失中;元学习器采用岭回归模型,通过加权整合第一层和第二层基学习器的输出,生成最终的预测结果。
15、优选的,所述super learner集成学习模型通过交叉验证(cross-validation)进行训练,以避免过拟合。模型的性能通过均方误差(mse)和决定系数(r2)进行评估,均方误差的公式为其中为预测值,yi为真实值。决定系数r2的计算公式为其中为真实值的均值。通过这两种评估指标,确保模型的预测精度和拟合效果。
16、优选的,对碳纳米管膜性能的目标变量进行功率变换即yeo-johnson变换,以将目标变量转化为接近正态分布的数据,具体公式为:其中y为目标变量原始数据,y′为变换后的数据,λ为变换参数,通过最大似然估计自动确定。该方法能够有效减少碳纳米管膜性能数据中的偏差,改善其分布的对称性,确保模型输入的连续性和稳定性,从而提高回归模型在预测碳纳米管膜物理水渗透性能时的准确性。结合功率变换后的数据,使用super learner集成学习模型对结合后的数据进行训练,最终得出碳纳米管膜性能的精确预测结果。
17、本发明的有益效果
18、与现有技术相比,本发明的有益效果在于:
19、(1)发明通过wgan-gp生成对抗网络生成高质量的合成数据,解决了传统方法因数据稀缺导致的训练不足问题,显著提升了模型的数据量和预测精度。
20、(2)利用super learner集成学习模型,结合随机森林、xgboost、lightgbm等多种基学习器,通过两层回归架构提高了碳纳米管膜水渗透性能预测的精度,尤其在处理复杂的多变量关系时表现出更强的泛化能力。
21、(3)通过交叉验证避免模型过拟合,确保预测结果的稳定性。功率变换的使用进一步减少了数据偏差,使模型对不同类型的碳纳米管膜数据更加鲁棒。
22、(4)本发明集成了数据扩展、预处理、模型训练与评估等步骤,简化了预测流程,减少了人工干预。相比于传统的手动分析或经验推测,本发明提供了自动化的预测方法,适用于大规模碳纳米管膜性能预测。
- 还没有人留言评论。精彩留言会获得点赞!