数据库的数据分桶方法及相关产品与流程
本发明涉及数据库,特别是涉及一种数据库的数据分桶方法及相关产品。
背景技术:
1、在某些数据库的数据进行异构迁移时,需要读取原有数据库中所有的表数据。由于数据量可能较大,影响数据的迁移时间,会对生产造成一定的影响。常见的解决方案是将大表进行数据分桶迁移,以达到提高迁移效率,降低迁移时间,缩小时间窗口,降低对生产的影响。
2、目前的数据分桶迁移方案中,在获取分桶查询数据的sql语句和分桶查询数据时,会使用主键或索引,但是这会消耗过多的性能,具体的性能问题如下:
3、1、读取主键或索引占用了磁盘、cpu、内存等资源消耗;
4、2、使用主键或索引排序会占用更多的内存和临时表空间,造成排序性能的不足;
5、3、读取使用主键或索引排序的数据时,可能出现随机读取,增加了查询的响应时间。
6、因此需要对上述性能问题进行优化。
技术实现思路
1、鉴于上述问题,本发明提出了一种克服上述问题或者至少部分地解决上述问题的数据库的数据分桶方法及相关产品。
2、本发明的一个目的是基于rowid进行数据分桶。
3、本发明一个进一步的目的是降低数据库在数据分桶时的性能消耗。
4、本发明一个进一步的目的是根据权限的不同选择不同方案进行数据分桶。
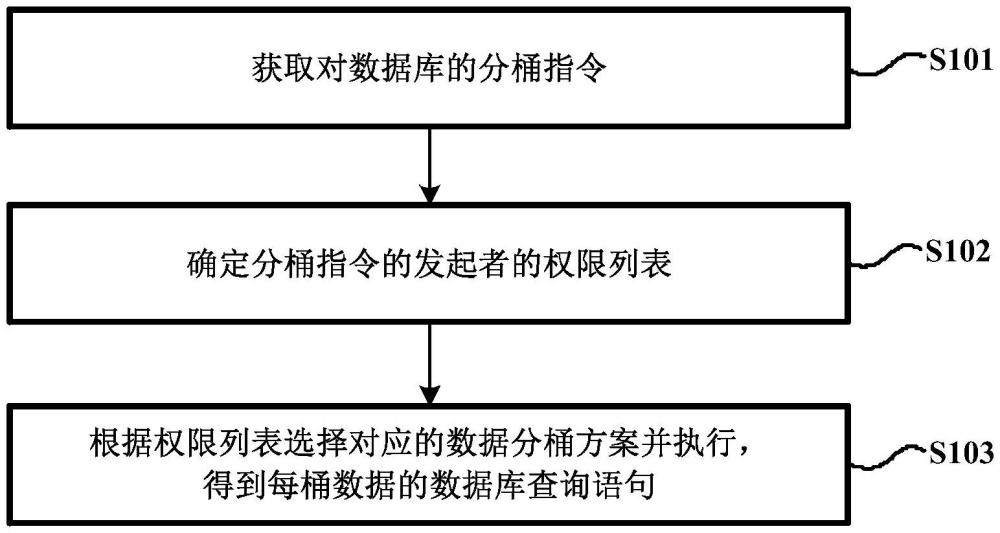
5、特别地,本发明提供了一种数据库的数据分桶方法,包括:
6、获取对数据库的分桶指令,分桶指令用于对数据库进行数据分桶;
7、确定分桶指令的发起者的权限列表,权限列表用于指示发起者在数据库中所拥有的权限;
8、根据权限列表选择对应的数据分桶方案并执行,得到每桶数据的数据库查询语句。
9、可选地,根据权限列表选择对应的数据分桶方案并执行的步骤包括:
10、在权限列表符合第一预设条件时,执行第一分桶方案,第一预设条件包括发起者拥有动态性能视图的读取权限、创建任务权限以及数据操作函数的执行权限,且本次数据分桶并未使用系统变更号;
11、在权限列表符合第二预设条件时,执行第二分桶方案,第二预设条件包括发起者拥有数据库中数据存储分配信息的读取权限以及数据库中对象信息的读取权限;
12、在第一分桶方案和第二分桶方案均无法执行或不采用时,执行第三分桶方案。
13、可选地,执行第一分桶方案的步骤包括:
14、根据分桶指令生成任务名称;
15、通过数据操作函数中的删除函数删除已经存在的无效任务;
16、通过数据操作函数中的创建函数根据任务名称创建对应的目标任务;
17、通过数据操作函数中的执行函数控制目标任务执行基于rowid的分桶任务;
18、根据任务名称在动态性能视图对应的系统表中获取分桶任务的执行结果,执行结果包括每桶中数据的起止对,起止对为起止对所在桶的起始rowid和结束rowid;
19、通过数据操作函数中的删除函数删除目标任务;
20、根据执行结果生成每桶数据的数据库查询语句。
21、可选地,分桶任务中预设参数包括:任务名称、待分桶数据表所在的模式名称、待分桶数据表名称、是否按数据行进行分桶、每桶行数;
22、执行基于rowid的分桶任务的步骤包括:
23、根据分桶指令填充预设参数;
24、根据待分桶数据表所在的模式名称以及待分桶数据表名称获取待分桶数据;
25、将待分桶数据按照自身rowid进行排序;
26、使用聚合函数根据排序结果确定待分桶数据的总行数;
27、在预设参数显示按数据行进行分桶的情况下,根据总行数以及预设参数中的每桶行数对排序结果进行划分得到实际分桶数量以及每桶中数据的起止对。
28、可选地,根据执行结果生成查询数据的数据库查询语句的步骤包括:
29、根据分桶指令确定预设分桶数量;
30、根据执行结果确定实际分桶数量;
31、判断实际分桶数量是否超过预设分桶数量;
32、若是,则对执行结果进行合并操作,使得实际分桶数量符合分桶指令的要求;
33、根据合并完成后的起止对生成数据库查询语句。
34、可选地,执行第二分桶方案的步骤包括:
35、在数据库中对象信息所在的系统表中根据分桶指令获取待分桶查询表对应的对象标识;
36、在存在对象标识的情况下,在数据存储分配信息所在的系统表中根据对象标识过滤待分桶查询表的表名以及模式名,并根据表名和模式名确定待分桶查询数据所在数据块的数据块总量;
37、根据分桶指令确定预设分桶数量,并根据数据块总量与预设分桶数量计算得到每桶对应的数据块数量;
38、在对象信息所在的系统表中根据表名和模式名获取待分桶查询数据的文件编号和块编号;
39、根据文件编号和块编号对待分桶查询数据进行排列,并按照顺序逐一生成rowid;
40、根据每桶对应的数据块数量计算生成每桶对应的起止对,起止对为起止对所在桶的起始rowid和结束rowid;
41、根据起止对生成每桶数据的数据库查询语句。
42、可选地,执行第二分桶方案的步骤还包括:
43、在数据库中对象信息所在的系统表中根据分桶指令获取待分桶查询表对应的对象标识;
44、在存在对象标识的情况下,在数据存储分配信息所在的系统表中根据对象标识过滤待分桶查询表的表名以及模式名,并根据表名和模式名确定待分桶查询数据所在数据块的数据块总量以及每个数据块的数据量;
45、根据分桶指令确定每桶对应的预设数据行数;
46、根据每桶对应的预设数据行数以及每个数据块的数据量进行数据块划分,从而确定每个桶与数据块的对应关系;
47、在对象信息所在的系统表中根据表名和模式名获取待分桶查询数据的文件编号和块编号;
48、根据文件编号和块编号对待分桶查询数据进行排列,并按照顺序逐一生成rowid;
49、根据每个桶与数据块的对应关系计算生成每桶对应的起止对,起止对为起止对所在桶的起始rowid和结束rowid;
50、根据起止对生成每桶数据的数据库查询语句。
51、可选地,根据表名和模式名确定待分桶查询数据所在数据块的数据块总量以及每个数据块的数据量的步骤之后还包括:根据待分桶查询表的表名确定待分桶查询表,并在待分桶查询表中查询最小rowid和最大rowid,rowid中记录有文件编号和块编号;
52、在对象信息所在的系统表中根据表名和模式名获取待分桶查询数据的文件编号和块编号的步骤之后还包括:判断获取的待分桶查询数据的文件编号和块编号是否包含最小rowid对应的最小文件编号和最小块编号以及最大rowid对应的最大文件编号和最大块编号;若否,则基于最小rowid和最大rowid进行数据补偿,从而获取最小rowid和最大rowid之间所有的待分桶查询数据的文件编号和块编号。
53、可选地,执行第三分桶方案的步骤包括:
54、根据分桶指令确定待分桶数据、分桶总数以及每桶数据量;
55、根据待分桶数据的rowid对待分桶数据进行分页查询;
56、通过预设数据库查询语句结合分桶总数和每桶数据量确定每桶数据的分界点数据在分页查询结果中对应的分界点rownum;
57、根据分界点rownum在分页查询结果中过滤得到每桶数据的分界点数据对应的分界点rowid;
58、根据分界点rowid计算生成每桶数据的起止对,起止对为起止对所在桶的起始rowid和结束rowid;
59、根据起止对生成每桶数据的数据库查询语句。
60、可选地,动态性能视图包括:sys.dba_parallel_execute_chunks视图;
61、创建任务对应的数据库函数包括:create job;
62、数据操作函数包括:dbms_parallel_execute;
63、数据库中数据存储分配信息对应的视图包括:sys.dba_extents视图;
64、数据库中对象信息对应的视图包括:sys.all_objects视图;
65、预设数据库查询语句为:
66、select(level-1)*{$rowsperchunk}+1from sys.dual connect by level<={splitnum};
67、其中{$rowsperchunk}为每桶数据量,{splitnum}为分桶总数。
68、可选地,根据权限列表选择对应的数据分桶方案并执行的步骤之后还包括:
69、创建设定数量的数据库连接分别使用数据库查询语句进行数据抽取。
70、根据本发明的另一个方面,还提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述任一种的数据库的数据分桶方法的步骤。
71、根据本发明的又一个方面,还提供了一种计算机程序产品,其包括计算机程序,该计算机程序被处理器执行时实现上述任一种的数据库的数据分桶方法的步骤。
72、根据本发明的再一个方面,还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并在处理器上运行的机器可执行程序,并且处理器执行机器可执行程序时实现上述任一种的数据库的数据分桶方法的步骤。
73、本发明的数据库的数据分桶方法,首先获取对数据库的分桶指令,分桶指令用于对数据库进行数据分桶;确定分桶指令的发起者的权限列表,权限列表用于指示发起者在数据库中所拥有的权限;根据权限列表选择对应的数据分桶方案并执行,得到每桶数据的数据库查询语句。通过此方法,可根据配置及已拥有的权限,选择适当的分桶方案,最终使用基于rowid过滤条件的分桶方式,提高了整体分桶数据抽取的效率,降低了数据库的性能消耗,提高了数据读取的性能,减少了对生产的影响。
74、根据下文结合附图对本发明具体实施例的详细描述,本领域技术人员将会更加明了本发明的上述以及其他目的、优点和特征。
- 还没有人留言评论。精彩留言会获得点赞!