历史遗留矿山与周边农用地土壤源汇关系的分析方法及装置与流程
本技术涉及重金属污染成因分析领域,更具体地说,涉及一种历史遗留矿山与周边农用地土壤源汇关系的分析方法及装置。
背景技术:
1、在土壤中,重金属的分布具有不均一性、隐蔽性、积累性、区域性和复杂性。近年来,为了更加准确的描述土壤重金属的来源以及和周边污染的源汇关系,分析方法有排放清单法、化学质量平衡模型(元素/同位素比值)、逐渐发展到多元统计模型(因子分析、聚类分析、正定矩阵因子分解(positive matrix factorization,pmf)、unmix模型等)、先进统计学算法(条件推断树、随机森林等)和空间分析法(地理探测器等)。
2、然而,传统的多元统计方法,如因子分析(factor analysis,fa)、主成分分析(principal component analysis,pca)和聚类分析(cluster analysis,ca),虽然在源识别方面有一定的效果,但它们通常只能提供定性的结果,难以进行定量的源解析。这意味着这些方法可以识别可能的污染源,但无法准确评估每个污染源对土壤重金属污染的具体贡献率。其次,化学质量平衡模型(chemical mass balance,cmb模型)和同位素比值法则需要经常监测研究区的源以及受体样本,列出排放清单,不断更新研究区的排放源成分谱。这种方法虽然可以定量评价各污染源的贡献率,但在处理过程中可能存在误差。
3、特别是矿山周边的农用地污染来源复杂,往往叠加地质高背景。并且由于矿山开采规模、开采方式、地质条件、气候条件等多种因素的影响,矿山周边农用地的污染程度往往存在较大的差异。因此,如何定量、准确的分析矿山与周边农用地土壤重金属的源汇关系是一项亟待解决的问题。
技术实现思路
1、有鉴于此,本技术实施例致力于提供一种历史遗留矿山与周边农用地土壤源汇关系的分析方法及装置,以解决矿山周围土壤重金属难以进行定量、准确的源解析的问题。
2、第一方面,本说明书提供一种历史遗留矿山与周边农用地土壤源汇关系的分析方法,包括:
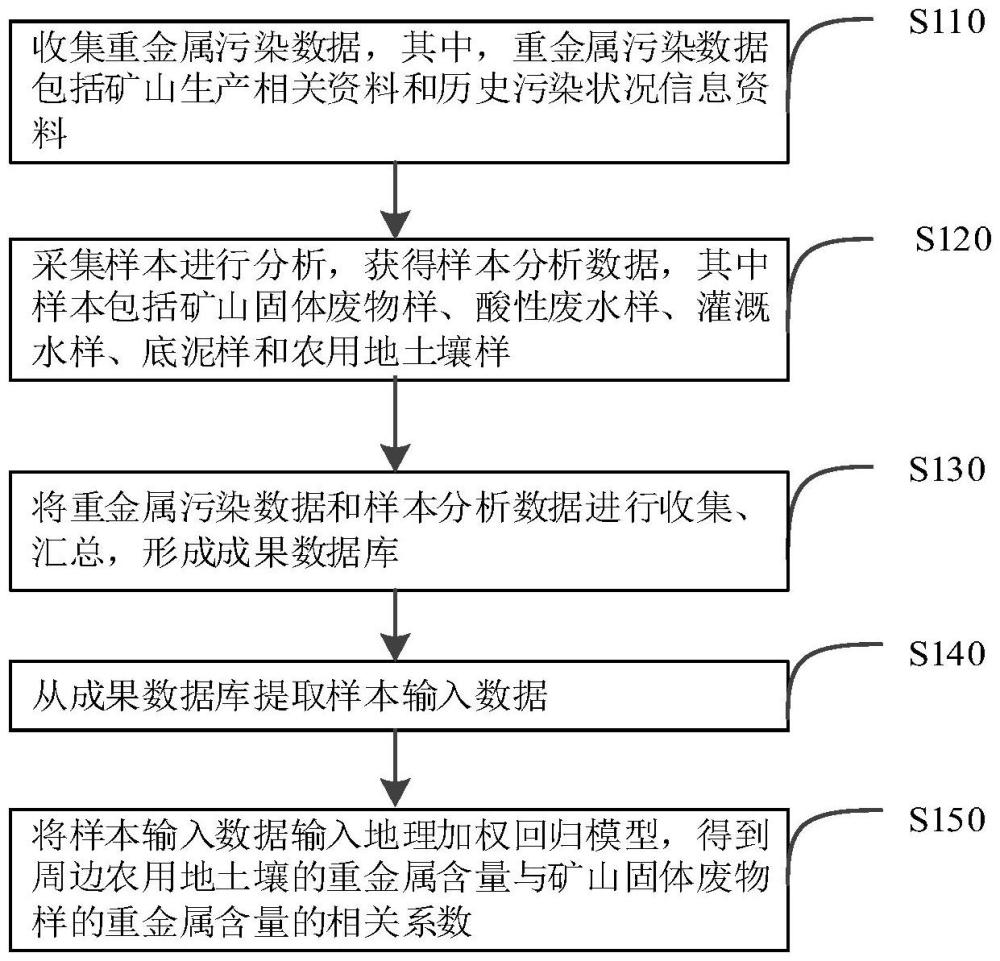
3、收集重金属污染数据,其中,重金属污染数据包括矿山生产相关资料和历史污染状况信息资料;
4、采集样本进行分析,获得样本分析数据,其中样本包括矿山固体废物样、酸性废水样、灌溉水样、底泥样和农用地土壤样;
5、将重金属污染数据和样本分析数据进行收集、汇总,形成成果数据库;
6、从成果数据库提取样本输入数据;
7、将样本输入数据输入地理加权回归模型,得到周边农用地土壤的重金属含量与矿山固体废物样的重金属含量的相关系数;
8、其中,地理加权回归模型是在局部回归分析模型的基础上加权地理位置构建的,局部回归分析模型的自变量为矿山固体废物样中的重金属含量,因变量为农用地土壤样中的重金属含量,地理位置表征农用地土壤样与矿山固体废物样的地理位置关系,根据酸性废水样、灌溉水样和底泥样中的重金属含量,判定相关系数的合理性和准确性。
9、根据第一方面,在一种可能的实施方式中,局部回归分析模型的参数是根据普通最小二乘法确定的,地理加权回归模型的带宽是根据赤池信息准则确定的。
10、根据第一方面,在一种可能的实施方式中,在收集重金属污染数据之后,该分析方法还包括:核验与补充重金属污染数据。
11、根据第一方面,在一种可能的实施方式中,在将样本输入数据输入地理加权回归模型,得到周边农用地土壤的重金属含量与矿山的相关系数之后,该分析方法还包括:
12、基于地理条件、气象条件和历史开采活动,检验相关系数;
13、基于矿山污染源汇关系评价体系,对矿山的污染进行分析和评价,其中,矿山污染源汇关系评价体系是基于地理条件、气象条件、矿种特性、开采技术和开采年限构建的,相关系数与矿种特性和开采年限显著相关。
14、根据第一方面,在一种可能的实施方式中,在收集重金属污染数据之前,该分析方法还包括:基于地理信息空间叠加分析和调研文献,确定矿山的优先级,其中,地理信息空间叠加分析包括空间分析和图层叠加,优先级表征学术界或者社会舆论对矿山的关注程度。
15、根据第一方面,在一种可能的实施方式中,在采集样本进行分析之前,该分析方法还包括:基于矿山污染扩散条件、污染关联关系及经验分析法确定样本的布设点位。
16、根据第一方面,在一种可能的实施方式中,采集样本进行分析,包括:
17、确定单要素分析指标和测试方法;
18、根据单要素分析指标和测试方法,对样本进行分析。
19、根据第一方面,在一种可能的实施方式中,矿山污染扩散条件包括气象条件、地形特征、污染物的物理和化学性质和工农业活动。
20、根据第一方面,在一种可能的实施方式中,将重金属污染数据和样本分析数据进行收集、汇总,包括:利用数据管理系统将重金属污染数据和样本分析数据进行收集、汇总。
21、第二方面,本说明书提供一种历史遗留矿山与周边农用地土壤源汇关系的分析装置,包括:
22、污染数据收集单元,用于收集重金属污染数据,其中,重金属污染数据包括矿山生产相关资料和历史污染状况信息资料;
23、成果数据库创建单元,用于获得样本分析数据,将重金属污染数据和样本分析数据进行收集、汇总,形成成果数据库;
24、样本提取单元,用于从成果数据库提取样本输入数据;
25、相关系数计算单元,用于将样本输入数据输入地理加权回归模型,得到周边农用地土壤的重金属含量与矿山固体废物样的重金属含量的相关系数;
26、其中,地理加权回归模型是在局部回归分析模型的基础上加权地理位置构建的,局部回归分析模型的自变量为矿山固体废物样中的重金属含量,因变量为农用地土壤样中的重金属含量,地理位置表征农用地土壤样与矿山固体废物样的地理位置关系,根据酸性废水样、灌溉水样和底泥样中的重金属含量,判定相关系数的合理性和准确性。
27、根据第二方面,在一种可能的实施方式中,局部回归分析模型的参数是根据普通最小二乘法确定的,地理加权回归模型的带宽是根据赤池信息准则确定的。
28、根据第二方面,在一种可能的实施方式中,污染数据收集单元还包括核验与补充模块,用于核验与补充重金属污染数据。
29、根据第二方面,在一种可能的实施方式中,相关系数计算单元还包括:
30、检验模块,用于基于地理条件、气象条件和历史开采活动,检验相关系数;
31、分析和评价模块,用于基于矿山污染源汇关系评价体系,对矿山的污染进行分析和评价,其中,矿山污染源汇关系评价体系是基于地理条件、气象条件、矿种特性、开采技术和开采年限构建的,相关系数与矿种特性和开采年限显著相关。
32、根据第二方面,在一种可能的实施方式中,污染数据收集单元还包括优先级确定模块,用于基于地理信息空间叠加分析和调研文献,确定矿山的优先级,其中,地理信息空间叠加分析包括空间分析和图层叠加,优先级表征学术界或者社会舆论对矿山的关注程度。
33、根据第二方面,在一种可能的实施方式中,成果数据库创建单元还包括点位布设模块,用于基于矿山污染扩散条件、污染关联关系及经验分析法确定样本的布设点位。
34、根据第二方面,在一种可能的实施方式中,矿山污染扩散条件包括气象条件、地形特征、污染物的物理和化学性质和工农业活动。
35、根据第二方面,在一种可能的实施方式中,成果数据库创建单元利用数据管理系统获得样本分析数据,并将重金属污染数据和样本分析数据进行收集、汇总。
36、第三方面,本说明书提供一种电子设备,包括:至少一个处理器;以及与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够执行如上所述的分析方法中的各步骤。
37、第四方面,本说明书提供一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被执行如上所述的分析方法中的各步骤。
38、与现有技术相比较,本发明的有益效果在于:
39、区别于现有技术,本发明提供的历史遗留矿山与周边农用地土壤源汇关系的分析方法,通过收集重金属污染数据,其中,重金属污染数据包括矿山生产相关资料和历史污染状况信息资料;采集样本进行分析,获得样本分析数据,其中样本包括矿山固体废物样、酸性废水样、灌溉水样、底泥样和农用地土壤样;将重金属污染数据和样本分析数据进行收集、汇总,形成成果数据库;从成果数据库提取样本输入数据;将样本输入数据输入地理加权回归模型,得到周边农用地土壤的重金属含量与矿山固体废物样的重金属含量的相关系数;其中,地理加权回归模型是在局部回归分析模型的基础上加权地理位置构建的,局部回归分析模型的自变量为矿山固体废物样中的重金属含量,因变量为农用地土壤样中的重金属含量,地理位置表征农用地土壤样与矿山固体废物样的地理位置关系,根据酸性废水样、灌溉水样和底泥样中的重金属含量,判定相关系数的合理性和准确性。该方案采用在局部回归分析模型的基础上加权地理位置得到的地理加权回归模型进行相关系数计算,由于该模型能够体现出样本的空间异质性特征,因而在定量分析的基础上解决了由空间异质性等带来的数据不连续、准确率低的问题,实现了对矿山周边土壤重金属定量、准确的源解析。
- 还没有人留言评论。精彩留言会获得点赞!