多模态特征嵌入的室内三维场景理解方法及终端
本发明涉及室内三维场景理解,尤其涉及的是多模态特征嵌入的室内三维场景理解方法及终端。
背景技术:
1、目前,多模态特征嵌入在室内三维场景理解研究领域引起了广泛关注,为实现更全面和深刻的场景理解提供了关键技术支持,也反映了多模态特征融合的巨大潜力。首先,研究人员关注如何融合来自多个传感器的信息,包括 rgb 摄像头、深度传感器和激光雷达等。这些传感器提供了丰富的场景特征信息,如颜色、深度、距离和纹理,多模态融合有助于系统更全面地感知和理解室内环境。其次,语义分割和对象检测是该领域的关键任务,用于将场景分成不同的对象和区域,并检测其中的物体。
2、室内三维场景理解技术不仅在学术界引起广泛兴趣,还在众多实际应用领域发挥着重要作用。它被应用于室内导航、智能家居、安全监控等领域。例如,它可以用于构建智能家居系统,监测室内环境中的异常情况,或者协助机器人在室内环境中导航。
3、总的来说,多模态特征嵌入的室内三维场景理解研究领域正在不断演进,将在未来继续取得突破性进展。多模态数据融合使得计算机能够更充分的利用场景信息,进而更全面、准确地理解室内环境,为智能化应用和服务提供了强有力的支持。
4、随着室内空间结构的日益复杂化以及人类活动的室内化的现象加剧,对于室内空间的研究需求越来越大。相应的,随着激光扫描、深度传感器等数据采集设备的快速发展,室内三维点云数据的获取愈发的便捷准确,不同模态的高精度室内场景数据也愈发的丰富。而传统方法依赖于单一传感器或有限的数据模态,无法充分利用场景信息,限制了场景理解的全面性和准确性。
5、因此,现有技术还有待改进。
技术实现思路
1、本发明要解决的技术问题在于,针对现有技术缺陷,本发明提供一种多模态特征嵌入的室内三维场景理解方法及终端,以解决传统的室内三维场景理解技术对场景信息利用率低的技术问题。
2、本发明解决技术问题所采用的技术方案如下:
3、第一方面,本发明提供一种多模态特征嵌入的室内三维场景理解方法,包括:
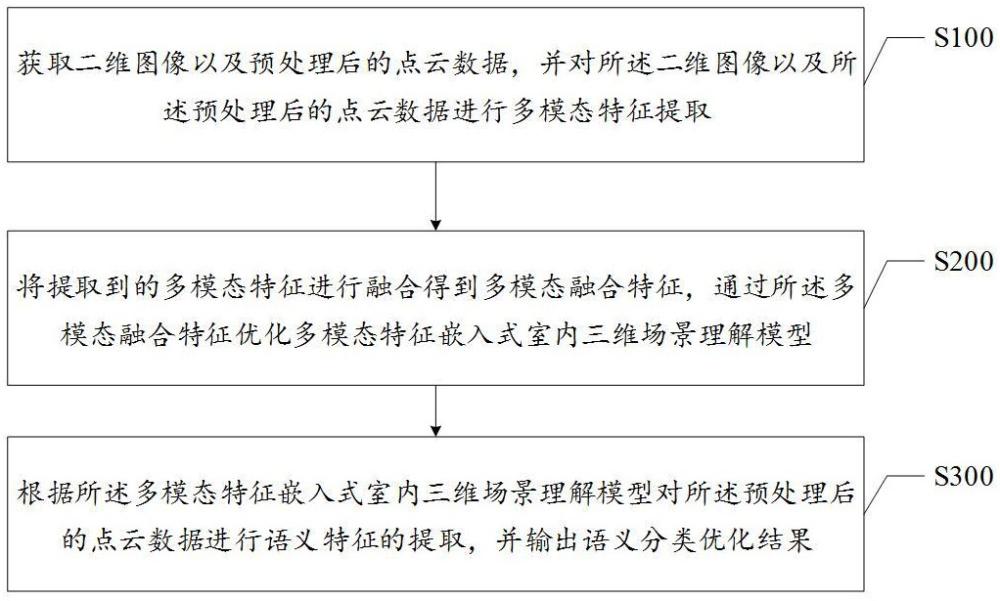
4、获取二维图像以及预处理后的点云数据,并对所述二维图像以及所述预处理后的点云数据进行多模态特征提取;
5、将提取到的多模态特征进行融合得到多模态融合特征,通过所述多模态融合特征优化多模态特征嵌入式室内三维场景理解模型;
6、根据所述多模态特征嵌入式室内三维场景理解模型对所述预处理后的点云数据进行语义特征的提取,并输出优化后的实例掩码以及优化后的语义信息。
7、在一种实现方式中,所述获取二维图像以及预处理后的点云数据,并对所述二维图像以及所述预处理后的点云数据进行多模态特征提取,包括:
8、获取所述二维图像,通过目标识别与提取得到对应单个目标的掩码,并通过语言-图像对比预训练模型进行视觉特征提取,得到二维单个目标全局特征;
9、获取所述预处理后的点云数据,对所述预处理后的点云数据进行多模态特征提取,并通过基于深度学习的3d语义实例分割模型进行实例分割,得到基于语义全局特征、单个实例全局特征和基于多视图融合全局特征。
10、在一种实现方式中,所述获取所述预处理后的点云数据,之前包括:
11、获取点云数据,对所述点云数据进行量化、稠密化、平滑、压缩和超体素化操作,得到所述预处理后的点云数据。
12、在一种实现方式中,所述对所述预处理后的点云数据进行多模态特征提取,并通过基于深度学习的3d语义实例分割模型进行实例分割,得到基于语义全局特征、单个实例全局特征和基于多视图融合全局特征,包括:
13、对所述预处理后的点云数据进行语义分割并生成对应的样本标签,根据所述样本标签提取出对应的类型语义,对所述类型语义进行语义特征编码得到所述基于语义全局特征;
14、通过所述基于深度学习的3d语义实例分割模型对所述预处理后的点云数据进行实例分割,提取单个实例,并通过实例特征编码得到所述单个实例全局特征;
15、根据所述基于深度学习的3d语义实例分割模型分割得到的实例结果,提取对应的实例掩码和对应的语义信息,根据所述实例掩码和对应的语义信息进行多视深度图投影,得到多视深度图;
16、通过语言-图像对比预训练模型进行多视图特征提取,并将所述多视图特征进行聚合,通过融合特征编码得到所述基于多视图融合全局特征。
17、在一种实现方式中,所述将提取到的多模态特征进行融合得到多模态融合特征,通过所述多模态融合特征优化多模态特征嵌入式室内三维场景理解模型,包括:
18、将所述二维单个目标全局特征、所述基于语义全局特征、所述单个实例全局特征和所述基于多视图融合全局特征进行融合,得到所述多模态融合特征;
19、通过所述多模态融合特征对所述多模态特征嵌入式室内三维场景理解模型进行再训练调参,优化模型参数配置。
20、在一种实现方式中,所述将所述二维单个目标全局特征、所述基于语义全局特征、所述单个实例全局特征和所述基于多视图融合全局特征进行融合,得到所述多模态融合特征,包括:
21、对所述二维单个目标全局特征、所述基于语义全局特征、所述单个实例全局特征和所述基于多视图融合全局特征进行文本生成和文本对齐的操作,得到对齐后的多模态特征;
22、将所述对齐后的多模态特征进行融合,得到所述多模态融合特征。
23、在一种实现方式中,所述对所述二维单个目标全局特征、所述基于语义全局特征、所述单个实例全局特征和所述基于多视图融合全局特征进行文本生成和文本对齐的操作,得到对齐后的多模态特征,包括:
24、通过文本生成模型,将所述二维单个目标全局特征、所述基于语义全局特征、所述单个实例全局特征和所述基于多视图融合全局特征映射到自然语言描述的空间,得到对应的文本描述序列;
25、对所述文本描述序列进行文本对齐操作,并对文本对齐的结果进行分析和验证,得到所述对齐后的多模态特征。
26、在一种实现方式中,所述根据所述多模态特征嵌入式室内三维场景理解模型对所述预处理后的点云数据进行语义特征的提取,并输出所述优化后的实例掩码以及所述优化后的语义信息,包括:
27、根据所述多模态特征嵌入式室内三维场景理解模型对所述预处理后的点云数据进行语义特征的提取,得到所述预处理后的点云数据对应的所述优化后的实例掩码以及所述优化后的语义信息;
28、输出所述优化后的实例掩码以及所述优化后的语义信息。
29、第二方面,本发明还提供一种终端,包括:处理器以及存储器,所述存储器存储有多模态特征嵌入的室内三维场景理解程序,所述多模态特征嵌入的室内三维场景理解程序被所述处理器执行时用于实现如第一方面所述的多模态特征嵌入的室内三维场景理解方法的操作。
30、第三方面,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有多模态特征嵌入的室内三维场景理解程序,所述多模态特征嵌入的室内三维场景理解程序被处理器执行时用于实现如第一方面所述的多模态特征嵌入的室内三维场景理解方法的操作。
31、本发明采用上述技术方案具有以下效果:
32、本发明通过获取二维图像以及预处理后的点云数据,并提取二维图像、预处理后的点云数据特征、投影图像融合特征以及文本语义特征的多模态特征;将提取到的多模态特征进行融合可以得到多模态融合特征,并通过多模态融合特征对多模态特征嵌入式室内三维场景理解模型进行训练,模型参数优化;根据训练优化后的多模态特征嵌入式室内三维场景理解模型对预处理后的点云数据进行语义特征的提取,并输出更准确的语义分类信息和实例掩码,从而实现特征层次的多模态化。采用深度学习技术将这些多模态特征数据进行融合,训练优化模型参数,以实现室内三维场景的精细化理解,使得模型对室内三维场景的理解更加精准和全面,解决了传统技术场景信数据使用模态单一,场景息利用率低的问题。为室内场景的智能化应用和管理提供更多可能性。
- 还没有人留言评论。精彩留言会获得点赞!