一种基于大数据的机器人日志数据分析方法及存储介质与流程
本技术涉及机器人,具体涉及一种基于大数据的机器人日志数据分析方法及存储介质。
背景技术:
1、随着人工智能和机器人技术的快速发展,机器人在工业、医疗、服务等领域应用日益广泛,机器人的数量与日俱增,而机器人系统在运行过程中,会产生大量的日志数据,这些数据记录着机器人的运行状态、传感器采集的数据、下发的控制指令等信息,如何分析这些数据,为机器人的优化方向做出指导作用是机器人企业关注的。
2、目前广泛运用的数据分析架构主要是通过传统结构化数据库进行存储分析的方式,但是这难以处理结构复杂的机器人日志数据。
3、另一种方式是通过非结构化的数据库mongodb的方式进行分析,编写脚本将日志文件导入mongodb,通过mongodb的聚合框架进行分析,但是这种分析方式对于分布式且大批量的数据的性能有限,处理速度受机器性能限制较大。
技术实现思路
1、鉴于上述问题,本技术提供了一种基于大数据的机器人日志数据分析方法及存储介质,解决现有通过结构化数据库进行存储分析机器人日志数据难以处理复杂的机器人日志数据。
2、为实现上述目的,发明人提供了一种基于大数据的机器人日志数据分析方法,包括以下步骤:
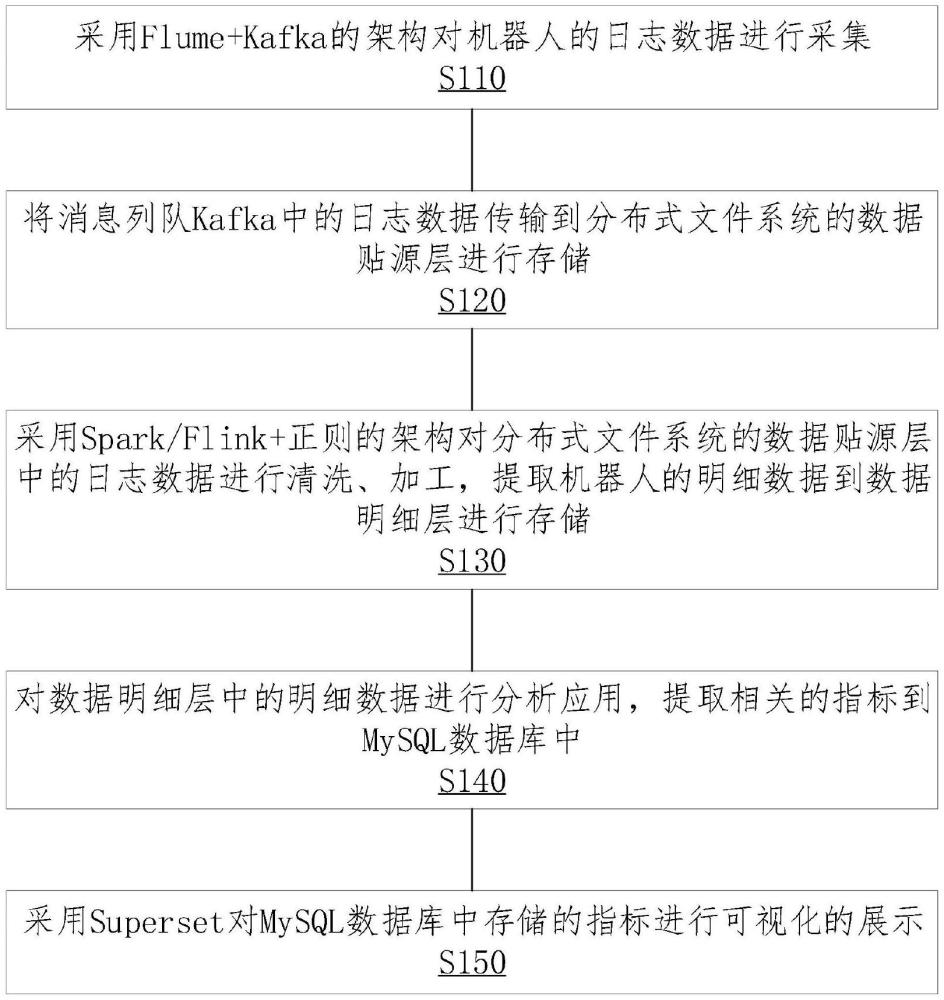
3、采用flume+kafka的架构对机器人的日志数据进行采集;
4、将消息列队kafka中的日志数据传输到分布式文件系统的数据贴源层进行存储;
5、采用spark/flink+正则的架构对分布式文件系统的数据贴源层中的日志数据进行清洗、加工,提取机器人的明细数据到数据明细层进行存储;
6、对数据明细层中的明细数据进行分析应用,提取相关的指标到mysql数据库中;
7、采用superset对mysql数据库中存储的指标进行可视化的展示。
8、在一些实施例中,所述采用flume+kafka的架构对机器人的日志数据进行采集具体包括以下步骤:
9、根据自定义flume_config在日志服务器中配置日志收集系统的相关环境;
10、根据自定义flume_config在kafka server中创建topic;
11、根据自定义flume_config加载模板生成数据采集conf文件;
12、根据自定义flume_config创建数据采集执行脚本;
13、根据自定义flume_config将数据采集conf文件及数据采集执行脚本发送到需要采集的服务器;
14、配置敏感策略,过滤敏感信息;
15、启动机器人日志采集任务,进行机器人日志数据采集。
16、在一些实施例中,所述将消息列队kafka中的日志数据传输到分布式文件系统的数据贴源层进行存储具体包括以下步骤:
17、通过自定义flume_config加载模板生成数据存储conf文件;
18、通过自定义flume_config加载模板生成数据存储执行脚本;
19、将生成的数据存储conf文件及数据存储执行脚本发送至需要采集的服务器;
20、启动机器人日志数据存储任务;
21、调用质量检查任务,对日志采集的源文件和存储文件进行比较,当日志生成异常时,进行告警。
22、在一些实施例中,所述采用spark/flink+正则的架构对分布式文件系统的数据贴源层中的日志数据进行清洗、加工,提取机器人的明细数据到数据明细层进行存储具体包括以下步骤:
23、将机器人的维度数据以缓慢变化维的形式进行存储,所述维度数据包括设备信息及空间信息;
24、通过spark sql+正则的方式,对日志数据进行清洗,提取网关协议数据;
25、对机器人网关协议数据,进行解析,提取相关数据,所述相关数据包括日期、设备及传感器;
26、将提取的相关数据与存储的维度数据进行碰撞,产生网关数据明细表;
27、将清洗完成的数据保存到hdfs上。
28、在一些实施例中,所述对数据明细层中的明细数据进行分析应用,提取相关的指标到mysql数据库中具体包括以下步骤:
29、基于业务,构建需求总线矩阵,设计指标类型和模型;
30、基于需求总线矩阵,对清洗后的数据进行分析,得到相关维度统计指标信息;
31、使用spark结合相关维度统计指标信息进行模型建设;
32、输出模型结果到mysql数据库中。
33、还提供了另一实施例中,一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器运行时执行以下步骤:
34、采用flume+kafka的架构对机器人的日志数据进行采集;
35、将消息列队kafka中的日志数据传输到分布式文件系统的数据贴源层进行存储;
36、采用spark/flink+正则的架构对分布式文件系统的数据贴源层中的日志数据进行清洗、加工,提取机器人的明细数据到数据明细层进行存储;
37、对数据明细层中的明细数据进行分析应用,提取相关的指标到mysql数据库中;
38、采用superset对mysql数据库中存储的指标进行可视化的展示。
39、在一些实施例中,所述采用flume+kafka的架构对机器人的日志数据进行采集具体包括以下步骤:
40、根据自定义flume_config在日志服务器中配置日志收集系统的相关环境;
41、根据自定义flume_config在kafka server中创建topic;
42、根据自定义flume_config加载模板生成数据采集conf文件;
43、根据自定义flume_config创建数据采集执行脚本;
44、根据自定义flume_config将数据采集conf文件及数据采集执行脚本发送到需要采集的服务器;
45、配置敏感策略,过滤敏感信息;
46、启动机器人日志采集任务,进行机器人日志数据采集。
47、在一些实施例中,所述将消息列队kafka中的日志数据传输到分布式文件系统的数据贴源层进行存储具体包括以下步骤:
48、通过自定义flume_config加载模板生成数据存储conf文件;
49、通过自定义flume_config加载模板生成数据存储执行脚本;
50、将生成的数据存储conf文件及数据存储执行脚本发送至需要采集的服务器;
51、启动机器人日志数据存储任务;
52、调用质量检查任务,对日志采集的源文件和存储文件进行比较,当日志生成异常时,进行告警。
53、在一些实施例中,所述采用spark/flink+正则的架构对分布式文件系统的数据贴源层中的日志数据进行清洗、加工,提取机器人的明细数据到数据明细层进行存储具体包括以下步骤:
54、将机器人的维度数据以缓慢变化维的形式进行存储,所述维度数据包括设备信息及空间信息;
55、通过spark sql+正则的方式,对日志数据进行清洗,提取网关协议数据;
56、对机器人网关协议数据,进行解析,提取相关数据,所述相关数据包括日期、设备及传感器;
57、将提取的相关数据与存储的维度数据进行碰撞,产生网关数据明细表;
58、将清洗完成的数据保存到hdfs上。
59、在一些实施例中,所述对数据明细层中的明细数据进行分析应用,提取相关的指标到mysql数据库中具体包括以下步骤:
60、基于业务,构建需求总线矩阵,设计指标类型和模型;
61、基于需求总线矩阵,对清洗后的数据进行分析,得到相关维度统计指标信息;
62、使用spark结合相关维度统计指标信息进行模型建设;
63、输出模型结果到mysql数据库中。
64、区别于现有技术,上述技术方案,通过基于flume+kafka的架构对机器人的日志数据进行采集,然后将消息列队kafka中的日志数据传输到分布式文件系统的数据贴源层,然后采用spark/flink+正则的架构对分布式文件系统的数据贴源层中的日志数据进行清洗、加工,提取机器人的明细数据到数据明细层进行存储,在对数据明细层中的明细数据进行分析应用,提取相关的指标到mysql数据库中,再采用superset对mysql数据库中存储的指标进行可视化的展示。该方案方便操作者能够快速地对机器人的日志数据进行汇聚、存储和数据分析,能够处理大规模、非结构化的机器人日志数据,以及能够快速分析并转化为指标进行展示。
65、上述
技术实现要素:
相关记载仅是本技术技术方案的概述,为了让本领域普通技术人员能够更清楚地了解本技术的技术方案,进而可以依据说明书的文字及附图记载的内容予以实施,并且为了让本技术的上述目的及其它目的、特征和优点能够更易于理解,以下结合本技术的具体实施方式及附图进行说明。
- 还没有人留言评论。精彩留言会获得点赞!