基于大语言模型赋能Text2SQL的电力数据增强分析方法与流程
本发明涉及大语言模型领域,尤其涉及一种基于大语言模型赋能text2sql的电力数据增强分析方法。
背景技术:
1、在电力系统中,面对海量的电力设备运行数据、用户需求问答和历史故障记录,如何高效、准确地提取信息和执行数据查询是一个关键问题。传统的查询方式一般需要用户具备一定的技术背景和sql查询技能,这对于非技术背景的用户而言十分困难。为此,文本到sql(text2sql)技术应运而生,通过将自然语言查询自动转换为结构化的sql查询,使用户无需了解数据库管理系统和查询语言,即可直接获取所需数据。
2、然而,电力领域的数据特征与通用数据存在较大差异,包括数据格式、术语、以及应用场景的专业性,使得现有的通用text2sql模型难以直接适用于电力领域。因此,构建一个适用于电力领域的专用text2sql模型对于提升电力数据查询与分析的效率至关重要。
技术实现思路
1、为了解决上述问题,本发明的目的在于提供一种基于大语言模型赋能text2sql的电力数据增强分析方法,能够更有效地处理电力系统中的自然语言查询,转换为sql执行查询,为电力系统的运行和决策提供数据支持。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于大语言模型赋能text2sql的电力数据增强分析方法,包括以下步骤:
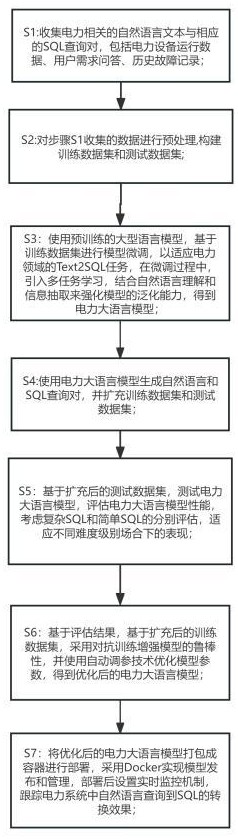
4、s1:收集电力相关的自然语言文本与相应的sql查询对,包括电力设备运行数据、用户需求问答、历史故障记录;
5、s2:对步骤s1收集的数据进行预处理,构建训练数据集和测试数据集;
6、s3:使用预训练的大型语言模型,基于训练数据集进行模型微调,以适应电力领域的text2sql任务,在微调过程中,引入多任务学习,结合自然语言理解和信息抽取来强化模型的泛化能力,得到电力大语言模型;
7、s4:使用电力大语言模型生成自然语言和sql查询对,并扩充训练数据集和测试数据集;
8、s5:基于扩充后的测试数据集,测试电力大语言模型,评估电力大语言模型性能,并考虑复杂sql和简单sql的分别评估,适应不同难度级别场合下的表现;
9、s6:基于评估结果,基于扩充后的训练数据集,采用对抗训练增强模型的鲁棒性,并使用自动调参技术优化模型参数,得到优化后的电力大语言模型;
10、s7:将优化后的电力大语言模型打包成容器进行部署,采用docker实现模型发布和管理,部署后设置实时监控机制,跟踪电力系统中自然语言查询到sql的转换效果。
11、进一步的,预处理包括文本预处理和sql预处理,具体如下:
12、文本预处理:使用正则表达式匹配并移除文本中的html标签
13、;
14、其中,regex.sub表示正则表达式替换操作,匹配html标签;text表示文本;textclean为移除了html标签的文本;
15、使用正则表达式移除除字母、数字和空格外的所有字符,并去除多余的空格;
16、textz=regex.sub(a,′′,textclean)
17、其中,regex.sub用于移除特殊字符a;textz为预处理后的文本;
18、基于空格和标点符号对文本进行分词,并对分词结果进行词性标注;
19、将电力领域的专有词汇加入词性标注模型的词典中,并使用训练好的命名实体识别模型识别电力相关实体;然后对电力设备运行数据标注,将数据与相关设备及运行状态进行关联,以生成sql查询对,并进行注释和验证;
20、sql预处理:使用sql解析器保证sql语句的语法合法性;从数据库中获取表结构信息,包括表名、字段名及其数据类型,验证sql查询中的表名和字段名是否存在于数据库表结构中。
21、进一步的,s3具体为:
22、步骤s31:根据s2获取的电力领域自然语言查询和对应的sql语句对,训练数据集表示为:
23、
24、其中, q i是第 i 条自然语言查询, s i是对应的sql查询,n 是数据集的大小;
25、标注电力领域的专有名词,标注结果表示为:
26、
27、其中,entity 表示电力领域的专有名词,m 是名词的数量;
28、步骤s32:加载预训练的大语言模型bert:
29、;
30、其中,为模型参数;
31、步骤s33:对预训练的大语言模型进行微调,采用转换文本到sql的任务,并构建损失函数:
32、;
33、其中, l ce表示交叉熵损失,m(qi)表示模型输出的sql预测;
34、步骤s34:结合自然语言理解和信息抽取任务,提升模型的泛化能力,总损失函数l表示为:
35、;
36、
37、;
38、其中,、、是权重系数,是自然语言理解任务的损失,是信息抽取任务的损失;表示第i个样本的真实标签,表示模型预测的概率分布,c是类别数;表示第i个样本的真实实体标签,是模型预测的实体概率,e是实体类别数;
39、步骤s35训练过程中,使用优化算法adam对模型参数进行更新,直至满足预设要求,得到电力大语言模型mfinetuned。
40、进一步的,步骤s4具体为:
41、s41:基于电力大语言模型生成自然语言和sql查询对,并构建逆向生成模型,从sql查询生成对应的自然语言文本,以扩大测试数据集,得到初步扩大测试数据集;
42、s42:利用同义词替换、语序调整,进行自然语言文本的数据扩展;
43、s43:使用语法规则、电力业务知识库和逻辑验证来筛选生成的数据,确保sql查询的正确性和合理性。
44、进一步的,s41具体为:
45、从现有的测试数据集中选择初始的自然语言查询列表,表示为:
46、;
47、其中,是第条自然语言查询,是初始自然语言查询的数量;
48、使用电力大语言模型mfinetuned对每一条自然语言查询生成对应的sql查询 ,整个生成的sql查询集表示为:
49、;
50、将生成的sql查询集和对应的自然语言查询配对,形成第一数据集:
51、;
52、使用编码器-解码器架构训练一个反向生成模型mreverse,使其能够从sql查询s 生成自然语言查询q:
53、使用逆向生成模型对现有的sql查询集 sinit生成自然语言查询:
54、;
55、其中,是反向生成模型生成的自然语言查询的数量;表示反向生成模型生成的第条自然语言查询生成的sql查询;
56、将生成的自然语言查询与对应的sql查询配对,形成第二数据集:
57、;
58、结合第一数据和第二数据集得到初步扩大数据集。
59、进一步的,s42具体为:
60、使用同义词词典对自然语言查询中的部分词汇进行替换,生成新的查询:
61、;
62、其中,synonym-replace表示基于同义词词典进行同义词替换;所述同义词词典,包括电力领域的同义词与相关词汇;
63、通过调整句子成分的顺序,生成新的自然语言查询:
64、;
65、其中,order-adjust为语序调整函数;
66、将同义词替换和语序调整生成的新查询与对应的sql查询配对,扩展数据集:
67、;
68、其中,(q,s)为原始的自然语言查询与sql查询对;(qsyn,s)为同义词替换生成的新查询与对应的sql查询配对;(qorder,s)为语序调整生成的新查询与对应的sql查询配对。
69、进一步的,步骤s5具体为:
70、评估模型性能采用的指标包括准确率、精确度、召回率和f1分数, 根据sql查询的特征,包括联接、嵌套子查询和聚合函数,将其分为简单sql和复杂sql,其中简单sql不包含联接、子查询,仅有选择、投影操作;复杂sql包含联接、多级子查询、聚合操作;针对分拆后的简单sql数据集dsimple和复杂sql数据集 dcomplex,分别计算上述性能指标。
71、进一步的,基于扩充后的训练数据集,采用对抗训练增强模型的鲁棒性,具体为:
72、初始化模型参数,在扩充后的训练数据集上进行标准训练,给定输入嵌入 x 和标签 y, 标准交叉熵损失函数ltotal;
73、使用标准交叉熵损失函数ltotal更新模型参数:
74、计算对抗扰动 δ:
75、
76、其中, 是扰动的大小; 表示目标函数l(θ,x,y) 对输入 x 的梯度;
77、根据当前模型参数计算输入扰动:
78、进行对抗训练:
79、使用扰动后的输入进行训练,通过损失函数 l(θ,x+δ,y) 更新模型参数;
80、;
81、其中,η为学习率,表示参数的梯度;
82、在每个epoch结束时进行评估,记录模型性能。
83、进一步的,使用自动调参技术优化模型参数,具体如下:
84、定义需要优化的超参数空间,包括学习率、batch size、对抗扰动大小;
85、①使用贝叶斯优化库进行自动调参:
86、②随机选择一组初始超参数并评估性能;
87、③构建和更新代理模型;
88、④通过采样策略选择下一个超参数组合;
89、⑤更新代理模型并迭代上述过程;
90、⑥记录性能最好的超参数组合,并使用这些超参数进行最终模型训练。
91、进一步的,步骤s7具体为:首先通过docker进行打包,将依赖和代码一同封装至镜像;然后,通过kubernetes进行部署和管理,采用deployment配置模型副本,通过service暴露服务;部署后,使用prometheus和grafana进行实时监控,定义和收集请求总数、成功请求数和失败请求数。
92、本发明具有如下有益效果:
93、1、本发明能够更有效地处理电力系统中的自然语言查询,转换为sql执行查询,为电力系统的运行和决策提供数据支持,综合提升了电力数据分析与处理的效果,使电力系统能够更加智能化和高效地处理复杂的查询需求,最终提高运维效率和用户满意度;
94、2、本发明通过微调预训练的大型语言模型,考虑电力领域的专有名词和业务逻辑,结合自然语言理解和信息抽取,强化模型的泛化能力,并结合自然语言理解和信息抽取的多任务学习方式,使模型在处理电力text2sql任务时表现更加精准和稳健;
95、3、本发明通过逆向生成模型从sql查询生成自然语言文本,扩大数据集规模,采用同义词替换、语序调整等数据扩展方法,进一步丰富和多样化数据集,使模型更具鲁棒性,并使用语法规则和电力业务知识库筛选生成的数据,确保sql查询和自然语言文本的正确性和合理性。
- 还没有人留言评论。精彩留言会获得点赞!