一种用于车辆安全测试的场景提取生成及评价方法
本发明涉及自动驾驶汽车,具体是涉及一种用于车辆安全测试的场景提取生成及评价方法。
背景技术:
1、传统汽车测试考虑的驾驶人与汽车的单一交互模式,在自动驾驶测试场景中人、车、环境复杂的交互关系导致测试场景和任务更为复杂;在仿真场景测试中测试例数量过多,需要自动化来帮助提高场景生成效率。随着人工智能的进步,深度强化学习的决策方式能够帮助发掘在构建场景工况中的信息短缺和不足问题。例如公开号为cn111144015a的发明专利中公开了一种自动驾驶汽车虚拟场景库构建方法,该方法通过无监督学习的方法聚类获得逻辑场景数据;搭建自然驾驶数据采集系统,采集相关数据,并从采集的自然驾驶数据中提取变道切入场景数据;之后标注场景库要素,形成变道切入场景数据集;利用k均值算法获得k个变道切入逻辑场景;并基于prescan软件构建切入虚拟场景库。再如公开号为cn118067417a的发明专利中公开了一种基于自动驾驶汽车的驾乘舒适度测评方法及系统,该系统方法通过确定测试场景基本信息,使得测试人员基于测试场景基本信息搭建测试场景;通过在测试场景进行舒适度的过程中,基于检测设备采集测试人员的舒适度数据,再通过对舒适度数据的分析以此来确定影响驾乘舒适度的因素。
2、目前,现有技术中基于自然驾驶数据的测试场景提取与生成方法,对要素提取多采用人工标注的方法,在场景构建方式上多采取人工构建。而常见的基于特征指标的聚类场景构建方法高度抽象,过于直接的离散化赋值损失了过多信息量,不能很好体现人、车、环境间的耦合关系。综上所述,现有评价体系仅评估了自动驾驶车辆的自身性能,没有对场景生成方法提出相应的评价方法和指标;所以,自动化的场景提取生成和评价方法是极为必要且亟需的。
技术实现思路
1、本发明的目的是提供一种用于车辆安全测试的场景提取生成及评价方法,该场景提取生成及评价方法采用语义分割网络最大程度保留原始自然驾驶数据的中的场景要素特征,基于高层决策深度强化学习算法使用粗糙集提炼出典型危险场景的关联生成规则,并能够结合仿真软件自动生成典型危险场景。
2、为了实现上述目的,本发明采用如下技术方案:
3、一种用于车辆安全测试的场景提取生成及评价方法,包括以下步骤:
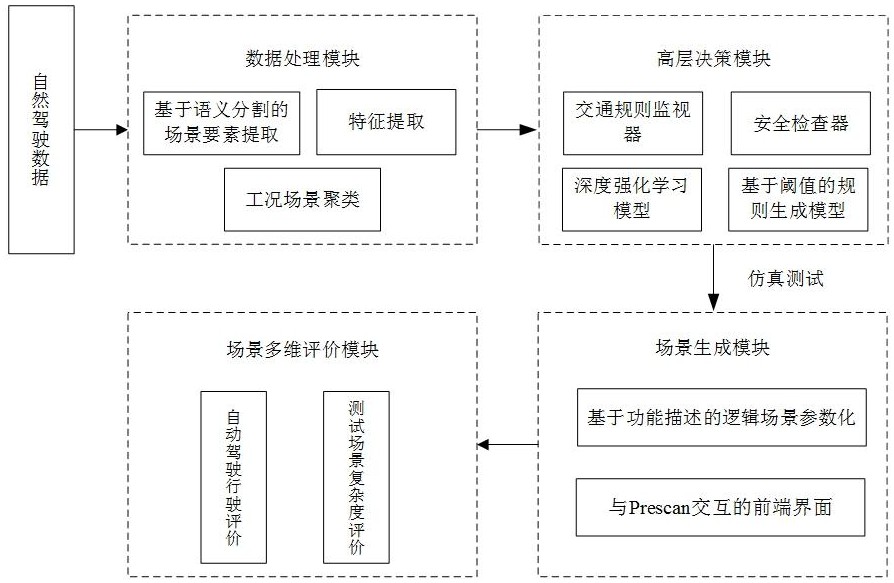
4、步骤1:数据处理模块:所用的原始数据为自然驾驶数据集;将自然驾驶数据集中的视频数据分为逐帧的图像;基于语义分割网络对每帧图像提取道路、交通设施、交通参与者场景要素;对同一要素按照时间戳进行跟踪,提取交通参与者数量、交通参与者相互间空间位置关系以及相互运动关系特征指标,并基于上述特征指标聚类出工况场景;
5、步骤2:高层决策模块:通过交通规则监视器提供自车与其他车辆之间优先级关系的优先级信息,基于责任敏感安全模型的安全检查器进一步了检查自车和他车是否违反了该规则,最终在高层决策模块限定奖励阈值及对应的危险动作簇,使用粗糙集提炼出典型危险场景的关联生成规则;
6、步骤3:场景生成模块:场景生成模块包括基于功能场景描述的逻辑场景关键要素参数化和基于prescan构建前端交互界面联合生成具体场景;
7、步骤4:场景评价模块:基于处理后的数据与场景变量,在自动驾驶行驶评价维度方面考虑:安全性、舒适性、预期功能安全性指标;在测试场景复杂度评价维度方面考虑:场景复杂度、任务复杂度指标;结合各评价指标对上述生成的具体场景进行评价并生成评价结果。
8、所述的步骤1包括以下分步骤:
9、步骤11:基于语义分割的场景要素提取;
10、步骤12:特征提取:对同一要素按照时间戳进行跟踪,从相邻帧的图片上同一要素的空间位置变化提取要素的特征;
11、步骤13:工况场景聚类:采用层析聚类法对带有时间戳和运动信息的场景进行聚类得到工况场景;将层析聚类的图片簇聚类结果按照时间戳连接为视频块。
12、所述的步骤2包括以下分步骤:
13、步骤21:构建交通规则监视器:引入的交通规则监视器来提供包含自我车辆与其他车辆之间优先级关系的优先级信息;交通规则监视器进一步检查自我车辆是否违反了该规则;
14、步骤22:构建安全检查器模型:根据rss模型验证当前状态是否安全;
15、步骤23:构建深度强化学习drl模型:主要包括以下分步骤:定义状态空间、动作空间和奖励模型,并执行深度强化学习过程;
16、步骤24:基于阈值的规则生成模型。
17、所述的步骤3包括以下分步骤:
18、步骤31:基于功能场景描述的逻辑场景参数化:将聚类出的工况场景描述得到不同层级关键要素或关键类别;基于功能场景的理解描述,以参数化的形式,将逻辑场景中各要素通过赋值为数值和类型予以表征,实现自然驾驶数据的要素及特征向仿真测试场景的映射;
19、步骤32:在基于prescan平台构建的前端交互界面联合生成场景方法上,在javascript中使用vue.js(用于构建用户界面的javascript框架)构建与prescan联合仿真的前端界面;前端界面操作框主要包括四个部分为:场景选择、要素选择、参数设置及动作控制和可视化界面。
20、所述的步骤11包括以下分步骤:
21、步骤111:语义分割网络在要素提取时首先对图像中的不同类别和元素进行标注生成数据,将图像中的要素记为预定义类别之一,如道路、交通设施、交通参与者、气象,生成训练数据集;
22、步骤112:以数据为导向构建一个语义分割模型,选择bisenetv2双边分割网络作为模型中的神经网络,将网络布署后,使用生成的训练数据集对模型进行训练;
23、步骤113:将自然驾驶数据中的逐帧图像通过布署的语义分割模型输出预测结果。
24、所述的步骤24包括以下分步骤:
25、步骤241:定义总奖励值为前15%的场景为典型危险场景,输出阈值范围内的多个动作簇作为典型危险场景的运行规则,同步保留对应的状态空间,生成状态-动作粗糙集,进而形成典型危险场景的关联生成规则;
26、m=(u,at,{va|a∈at},{ia|a∈at})
27、式中,u={sa,aa}(a∈at)为有限对象集合组成的论域,为符合阈值的输入样本;at为符合阈值条件的状态和动作要素特征组成的有限非空属性集合;va表示属性a∈at的属性值范围,即属性a的值域。ia:u→va是一个信息函数及关联规则。
28、所述的步骤32包括以下分步骤:
29、步骤321:场景选择包括逻辑方案选择和逻辑子场景的设置;逻辑方案选择是面向功能,如交叉口通行功能;逻辑子场景设置是基于自然驾驶数据得到的聚类结果的,如无信号灯主干路-支路交叉口通行场景;
30、步骤322:要素选择是对基于自然驾驶数据提取的重要要素进行选择,包含静态场景要素、动态场景要素和气象要素;静态场景要素,可利用prescan场景编辑界面的元素库中快速建构;动态场景要素,可基于java语言框架设计的web界面作为前端操作界面的api(api,application programming interface),即应用程序编程接口,使其与prescan构建静态场景要素的api相联合;
31、步骤323:参数设置及动作控制部分由逻辑场景参数化驱动;对于可直接赋值的元件,可直接在输入框中输入具体参数值,实现数值参数的精确设置;对于不能直接赋值的元素,可以单次选择对类别参数进行设置;基于高层决策模块得到场景生成规则,对自然驾驶数据中的场景重现,生成在自然驾驶数据中未出现的边缘危险场景;
32、步骤324:可视化界面部分以可视化场景、图表演示显示场景自动提取生成结果;在逻辑场景参数化的基础上,前端界面中做好参数设置后,prescan会弹出并运行仿真,显示构建生成的典型场景。
33、本发明的有益效果为:本发明所提供的一种用于车辆安全测试的场景提取生成及评价方法与现有的车辆测试场景提取与生成方法相比较而言,具有与如下优点:
34、本发明的用于车辆安全测试的场景提取生成及评价方法,采用语义分割网络最大程度保留原始自然驾驶数据的中的场景要素特征,基于高层决策深度强化学习算法使用粗糙集提炼出典型危险场景的关联生成规则,并能够结合仿真软件自动生成典型危险场景,为参考自然驾驶数据自动化提取场景的特征及生成提出了一定的设计思路;同时又从自然驾驶行驶评价、测试场景复杂度评价两个维度上结合对自动驾驶汽车整体的智能性进行评价,结合不同方面的关键指标优势从而提高了对自动驾驶汽车评价的多维性;大幅提升场景生成的效率和智能化水平。
- 还没有人留言评论。精彩留言会获得点赞!