基于多模态融合深度学习的自然环境鸟类监测方法及计算机装置
本发明涉及鸟类监测领域,具体涉及一种基于多模态融合深度学习的自然环境鸟类监测方法及计算机装置。
背景技术:
1、在生态研究和环境保护中,鸟类监测是一个重要的领域。鸟类作为生态系统的重要组成部分,其种群的健康状况反映了生态环境的整体健康。传统的鸟类监测方法主要依赖人工观察,这不仅效率低下,而且在大范围或难以接近的自然环境中难以实施。尽管近年来技术的进步促进了自动化监测工具的发展,如使用定点相机和声音记录设备,但这些方法仍然存在局限性。
2、有限的数据采集:传统监测技术通常只能提供有限的视角和覆盖范围,难以全面捕捉鸟类在广阔环境中的活动。
3、数据处理不足:即使通过自动化工具收集了大量数据,也常常缺乏有效的数据处理和分析方法,导致难以从复杂的环境数据中提取有用信息。
4、对复杂环境适应性差:现有的自动监测系统往往在多变的自然环境条件下表现不佳,如在恶劣天气或在复杂背景噪声中的性能显著下降。
5、实时监测能力弱:大多数现有技术无法实现实时或近实时的数据分析和反馈,限制了对突发生态事件的快速响应能力。
6、由于这些问题,本发明提出一种新的技术解决方案,该方案能够更高效地收集和处理多模态数据,包含视觉和声音数据,并具备更强的环境适应性和实时处理能力。
技术实现思路
1、本发明的目的在于克服现有技术的缺点,提供一种基于多模态融合深度学习的自然环境鸟类监测方法及计算机装置,实现了对鸟类多模态数据的高效处理,提高了对鸟类分析的准确性。
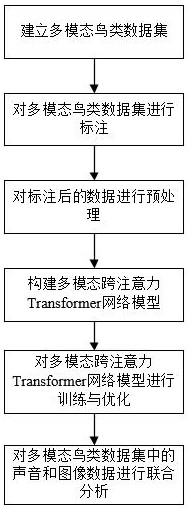
2、本发明采取如下技术方案实现上述目的,第一方面,本发明提供一种基于多模态融合深度学习的自然环境鸟类监测方法,包括:
3、s1、建立多模态鸟类数据集;
4、s2、对多模态鸟类数据集进行标注;
5、s3、对标注后的数据进行预处理;
6、s4、构建多模态跨注意力transformer网络模型;
7、对多模态鸟类数据集中的视觉数据与声音数据进行初始特征提取;
8、对于视觉数据,采用预训练的深度卷积神经网络来提取空间特征,具体方式如下:
9、
10、其中,是输入的图像数据,是从图像中提取的视觉特征;
11、对于声音数据,通过短时傅里叶变换转换为时频谱图,具体方式如下:
12、
13、其中,是输入的声音信号, s为时频谱图;
14、使用循环神经网络对时频谱图进行特征提取,得到声音特征,具体方式如下:
15、
16、为声音特征;
17、将视觉特征和声音特征通过展平操作分别转换为序列数据:
18、
19、其中,、为线性嵌入矩阵,、为对应的偏置项,为序列化后的视觉特征,为序列化后的声音特征;
20、将序列化后的视觉特征和声音特征分别输入到独立的transformer编码器中,捕获序列数据内部的长程依赖性,具体方式如下:
21、
22、为视觉特征内部的长程依赖性,为声音特征内部的长程依赖性;
23、引入跨模态注意力机制,该机制通过一个模态的数据作为查询,另一个模态的数据作为键和值,计算跨模态注意力;
24、计算视觉特征对声音特征的跨模态注意力:
25、
26、
27、计算声音特征对视觉特征的跨模态注意力:
28、
29、
30、其中,、、和、、为可学习的投影矩阵,为键的维度,表示计算视觉特征对声音特征的跨模态注意力,表示计算声音特征对视觉特征的跨模态注意力,表示视觉特征通过投影矩阵得到的查询矩阵,表示声音特征通过投影矩阵得到的键矩阵,表示声音特征通过投影矩阵得到的值矩阵,表示声音特征通过投影矩阵得到的查询矩阵,表示视觉特征通过投影矩阵得到的键矩阵,表示视觉特征通过投影矩阵得到的值矩阵;
31、对跨模态注意力输出的特征进行融合,融合方式包括特征串联与前馈神经网络或加权求和;
32、特征串联与前馈神经网络:
33、通过将两个模态的跨模态注意力结果串联起来,输入到前馈网络中,具体方式如下:
34、
35、加权求和:
36、通过加权求和的方式,将视觉和声音模态的注意力输出进行融合,具体方式如下:
37、
38、其中,为可学习的融合权重,表示不同模态在融合过程中的相对重要性,f表示融合后的特征;
39、引入图神经网络对融合特征进行上下文建模,图神经网络通过构建图结构来表示鸟类个体及其之间的关联,节点v表示鸟类个体,边e表示鸟类个体之间的联系,每个节点的特征表示在第层中根据邻居节点信息进行更新,具体方式如下:
40、
41、其中,为节点i的邻居节点集合,为归一化系数,、为可学习的权重矩阵,为激活函数,表示图神经网络的第层中节点 i 的特征更新结果,表示节点 j 在图神经网络第层的特征向量;
42、s5、对多模态跨注意力transformer网络模型进行训练与优化;
43、s6、对多模态鸟类数据集中的声音和图像数据进行联合分析;
44、使用广义互相关相位变换算法进行声源定位,具体方式如下:
45、
46、其中,和分别为两个麦克风接收到的声音信号的傅里叶变换,为时间的变量,为互相关函数,表示一个复指数函数,用于对信号在频率域进行相位平移, f表示频率, j表示虚数单位;
47、使用yolov8目标检测模型,对标注好的图像数据进行训练,实现对鸟类目标的快速检测;
48、结合deepsort跟踪算法,对检测到的目标进行跟踪,获取鸟类的运动轨迹;
49、将声源定位信息与视觉跟踪结果进行时空同步,通过联合分析,验证鸟类的身份和位置。
50、进一步的是,步骤s1具体包括:
51、所述多模态鸟类数据集包含视觉与声音两种模态的数据;
52、视觉数据采集,使用摄像头在自然环境中采集鸟类的图像和视频,摄像头安装在不同的高度和角度,以覆盖各种栖息地和行为场景;
53、声音数据采集,采用定向麦克风和全向麦克风相结合的方法,收集鸟类的鸣叫声和环境声音,定向麦克风用于捕获设定方向的鸟类声音,全向麦克风则用于收集环境中的背景声音;
54、将已有的公开鸟类图像和声音数据集与采集到的数据相结合,对结合后的所有数据进行整理和标准化处理,统一数据的存储格式。
55、进一步的是,步骤s2具体包括:
56、使用labelimg对多模态鸟类数据集中的图像数据进行标注,包括鸟类目标的物种、年龄、性别以及行为特征信息,标注结果生成对应的标准格式的文件;
57、使用audacity对多模态鸟类数据集中的声音数据进行标注,包括鸟鸣声的时间段、频率特征与声音来源特征信息,标注结果生成对应的标准格式的文件;
58、对图像与声音数据的标注进行时间同步,确保多模态数据在同一时间段内的一致性。
59、进一步的是,步骤s3具体包括:
60、图像数据预处理,对多模态鸟类数据集中的每张图像进行直方图均衡化,增强图像的对比度,然后采用中值滤波与高斯滤波去除图像中的噪声,通过旋转、缩放、裁剪以及颜色抖动增加数据的多样性;
61、声音数据预处理,使用频域滤波和降噪算法去除声音数据中的背景噪声,对声音信号进行预加重处理,增强高频部分的能量,将处理后的声音信号转换为梅尔频谱图和梅尔频率倒谱系数时频特征。
62、进一步的是,步骤s5具体包括:
63、s51、自监督预训练;
64、使用未标注的图像和声音数据分别对视觉模型和声音模型进行自监督预训练;
65、视觉模型采用simclr或moco自监督对比学习方法,学习图像的潜在特征表示,目标函数为:
66、
67、其中,表示视觉模型的目标函数,和为正样本对的特征表示,为相似度函数,为温度参数,2n表示对比学习中使用的样本对的总数;
68、声音模型使用contrastive predictive coding方法,对未标注的声音数据进行自监督预训练;
69、s52、自监督预训练完成后,结合标注好的数据集,对多模态跨注意力transformer网络模型进行有监督微调;
70、通过融合视觉与声音模态的特征,优化多模态跨注意力transformer网络模型参数,优化训练过程中的联合损失函数如下:
71、
72、其中,表示联合损失函数,、、分别为视觉路径、声音路径和融合路径的有监督损失,,,为损失权重系数;
73、s53、设置多模态跨注意力transformer网络模型的损失函数;
74、多模态跨注意力transformer网络模型采用多任务学习框架,同时进行分类、定位和跨模态一致性学习,总损失函数由以下几部分组成:
75、分类损失:
76、
77、其中,表示分类损失函数,为真实类别标签,为多模态跨注意力transformer网络模型的预测概率;
78、定位损失:
79、
80、其中,表示定位损失函数,和分别为真实和预测的边界框位置,使用损失进行优化;
81、跨模态一致性损失:
82、
83、其中,表示跨模态一致性损失函数,表示第 i个样本的视觉特征,表示与第 i个视觉样本对应的声音特征,构成了一个正样本对,表示第 j个声音特征,为余弦相似度函数,n表示在一个训练批次中包含的样本数量,为温度参数;
84、总损失函数:
85、
86、其中,l表示总损失函数,为各损失项的权重系数,用于平衡不同任务之间的影响;
87、s54、采用增强学习优化多模态跨注意力transformer网络模型策略;
88、定义基于多模态跨注意力transformer网络模型表现的奖励函数 r,包括识别准确率 a、召回率 r和f1-score指标,具体如下:
89、
90、其中,,,为权重系数,使用策略梯度方法优化多模态跨注意力transformer网络模型的参数调整策略;
91、s55、采用网格搜索和贝叶斯优化方法对超参数进行搜索和调优,所述超参数包括学习率、批量大小以及网络深度。
92、第二方面,本发明提供一种计算机装置,包括存储器,所述存储器存储有程序指令,所述程序指令运行时,执行上述所述的基于多模态融合深度学习的自然环境鸟类监测方法。
93、本发明的有益效果为:
94、本发明构建一个包含高分辨率图像和清晰鸟鸣声的鸟类数据集,利用高清摄像头和定向及全向麦克风收集视觉和声音数据,结合公开数据集进行扩充,为深度学习模型提供丰富的训练和验证资源。
95、本发明采用图像增强和声音信号增强技术,如图像直方图均衡化、声音的噪声减除和信号预加重,提升数据质量,为模型训练提供优化的输入。
96、本发明整合预训练的视觉和声音模型,采用双路径联合建模网络,一个路径处理视觉数据,采用深度卷积神经网络(如resnet-50)提取图像特征;另一个路径处理声音数据,使用循环神经网络(如lstm)处理声音波形,捕捉时间序列依赖,结合视觉和声音数据,通过轻量化注意力机制提升识别精度,多模态融合层整合信息,并在有标记的数据集上进行微调,精细调整模型以适应具体的监测任务。
97、本发明定义基于模型表现的奖励机制,使用增强学习优化决策过程,实时调整模型参数,适应环境变化。
98、本发明在不同生态监测任务中应用模型,通过迁移学习方法评估和增强模型的泛化能力。
99、本发明使用gcc-phat方法进行声源定位,结合yolov8等先进的目标检测算法,以及deepsort跟踪技术,实现实时动态鸟类监测和行为分析,提高了鸟类分析的准确性。
100、本发明通过超参数调整和算法优化确保系统在实际应用中达到最佳效果。
- 还没有人留言评论。精彩留言会获得点赞!