一种信息提取评估方法及计算机可读存储介质
本发明涉及数据分析,具体涉及一种信息提取评估方法及计算机可读存储介质。
背景技术:
1、在当今信息化社会,尤其是在金融服务领域,用户对快速响应、高价值的信息筛选需求变得尤为迫切。然而,传统的信息筛选和处理方法在应对大规模、多样化的金融数据时存在诸多局限,主要体现在以下几个方面:
2、1.时效性难以保障
3、传统的信息筛选方式通常依赖于预设的关键词或规则匹配,处理流程相对简单,难以适应信息的快速变化。例如,在金融市场中,用户关注的产品和市场动态可能发生在短时间内,而传统的筛选方式因其手动设置的规则,难以及时响应并筛选出与用户高度相关的信息。这导致用户无法及时获取有效信息,进而可能错失市场机遇。
4、2.个性化需求难以满足
5、现有方法在信息筛选上缺乏对用户个性化需求的深入理解,通常依赖于静态的关键词匹配和通用化的信息推送,忽视了用户在风险偏好、投资记录、行业关注等方面的差异性。由于没有实现用户个体的动态偏好匹配,导致信息推送的精确度不足,不能充分满足用户的个性化需求。
6、3.数据处理能力有限
7、现有的机器学习模型或基于tf-idf等统计方法的文本处理模型在面对金融领域的海量数据时难以保证高效性。这些方法通常缺少对数据多维度的关联分析,例如关联金融产品的相似性、时效性及传播热度,导致信息筛选时冗余信息多、关键性信息识别不足,无法为用户提供精准的高价值信息。
8、在金融服务领域,投资者需要紧密关注市场动态、企业信息以及其投资组合的变化,而在信息过载的背景下,用户往往难以从繁杂的信息中快速提取到对其投资决策有重要影响的资讯。例如:
9、1.市场快速变动:在股票或基金市场中,突发的新闻或企业公告往往会对市场造成重大影响。用户需要快速判断这些信息与其持有的金融产品相关性,以便及时调整投资策略。传统的关键词匹配难以迅速响应这些高频率、短时效的资讯更新。
10、2.用户偏好的多样性:不同用户在投资风格和风险偏好上差异明显,部分用户偏好保守型投资,而另一些用户可能偏好高风险高收益的产品。现有的推送方式无法有效区分用户的个体需求,无法向用户精准推送符合其偏好的信息。
11、3.多渠道信息处理:金融信息来自多种渠道,如新闻平台、社交媒体、市场公告等。这些渠道的信息格式多样、更新频率快,现有的信息筛选方式难以对多源异构信息进行有效整合和分析,导致推送的资讯未能有效满足用户的实际需求。
技术实现思路
1、本发明的目的是针对现有技术存在的不足,提供一种信息提取评估方法及计算机可读存储介质。本发明提供的“信息提取评估方法”通过结合大语言模型和个性化偏好匹配模型,有效解决了现有技术在时效性、个性化、数据处理能力上的不足。该方法不仅能够从大规模、多源异构的信息中精准提取出高价值资讯,同时还能基于用户的风险偏好动态更新筛选规则,为用户提供实时、准确的个性化金融信息服务。
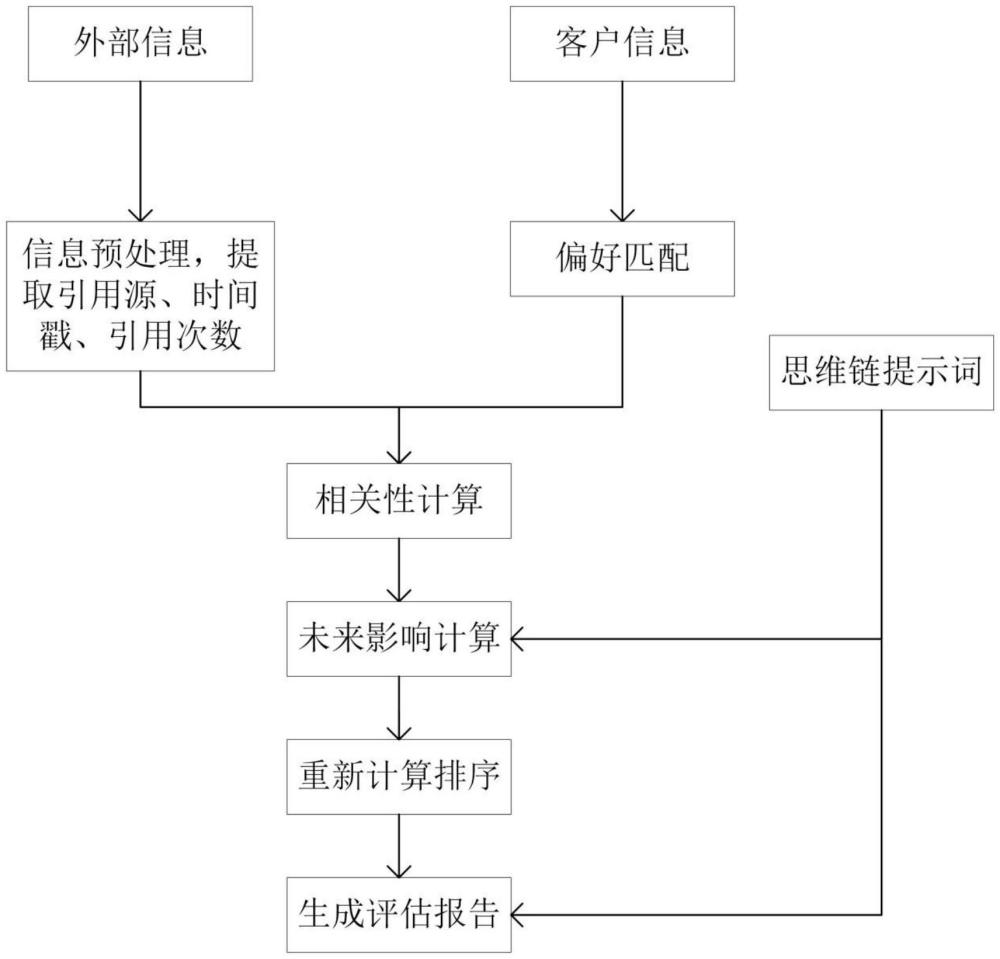
2、为实现上述目的,在第一方面,本发明提供了一种信息提取评估方法,包括:
3、获取外部信息;
4、对所述外部信息进行预处理,以提取引用源、时间戳、引用次数,并输出结构化的外部信息至数据库;
5、收集并更新用户的个人信息,所述个人信息包括风险偏好、当前产品持有情况、历史持有记录以及关注的企业和行业信息;
6、根据用户的购买产品记录和产品属性,由专家经验定义用户风险偏好规则,建立样本集合;市场上金融产品的各项属性由专家给出标签定义规则,并建立风险偏好标签,利用transformer模型建立标签分类模型,生成与用户偏好的关联映射,对市场上的所有公开金融产品进行标签预测;
7、从所述外部信息中提取与用户关联的金融产品信息,并计算关联的金融产品信息与用户持有、关注及风险偏好关联的产品进行相关性计算,并在排序后,输出top n个关联的金融产品信息;
8、构建思维链提示词,将输出的每条关联的金融产品信息的现状和相应的外部信息输入至大语言模型,以使所述大语言模型输出影响分类;
9、将所述影响分类映射到权重,重新计算每条信息的价值得分,并在重新排序后,输出top m个关联的金融产品信息;
10、将top m个关联的金融产品信息结合思维链提示词,并调用大语言模型输出分析报告。
11、进一步的,还包括:
12、利用埋点技术评估用户对生成报告的反馈,结合用户的实际行为数据,定期动态更新用户偏好和对应的关注内容。
13、进一步的,所述相关性的计算方式具体如下:
14、通过关键字查询的方式,获取外部信息中与用户当前持有产品相关联的所有信息,并按照时间要求进行过滤;
15、利用指数衰减函数对外部信息的时效性进行量化评估,具体如下:
16、
17、其中,pt为外部信息的时效性的量化评估结果;e为自然常数,ω为时效性衰减系数,tcurrent为进行信息评估时的时间戳;tpubish为外部信息的发布时间戳;
18、使用专家规则定义各个引用源的权重,具体如下:
19、ps=sourcescore(s)
20、其中,ps为引用源s的权重,sourcescore为专家给引用源的分值;
21、根据主题或关键词计算外部信息与用户关注的企业和行业信息的相关性,具体如下:
22、
23、其中,pc为计算出的外部信息与用户关注的企业和行业信息的相关性,ei为外部信息的嵌入向量,eu为用户关注的企业和行业信息的嵌入向量;
24、计算所述外部信息的传播热度,具体如下:
25、ph=wr*norm(countr)+wf*norm(countf)+wc
26、*norm(countc)
27、其中,ph为计算出的所述外部信息的传播热度,wr为阅读权重,countr为外部信息的阅读次数,wf为转发权重,countf为外部信息的转发次数,wc为信息在系统的计数权重,countc为外部信息的计数次数,norm(.)为正则归一化函数;
28、计算所述外部信息的价值为:
29、pi=w1*pt+w2*ps+w3*pc+w4*ph
30、其中,pi为计算出的外部信息的价值,wi为各维度的权重,i=1,2,3,4。
31、进一步的,所述影响分类包括正向、负向和中性。
32、进一步的,所述正向映射到的权重为1,所述负向映射到的权重为1.5,所述中性映射到的权重为0.5。
33、进一步的,所述风险偏好标签包括保守型、稳健型、平衡型、积极型和激进型。
34、进一步的,所述外部信息的来源包括新闻和市场数据。
35、在第二方面,本发明提供了一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现上述的方法。
36、有益效果:本发明综合利用大语言模型提示词工程、transformer分类模型和相关性评估等,实现对高价值信息的排序和识别,最终筛选出符合用户风险偏好的信息清单;又利用大语言模型的总结能力,输出一份和用户密切相关的风险报告,为用户提供时效性高、信息准确的服务。
- 还没有人留言评论。精彩留言会获得点赞!