基于上下文感知和跨模态共享注意力的对话情感识别方法
本发明属于计算机自然语言处理领域,具体涉及一种基于上下文感知和跨模态共享注意力的对话情感识别方法。
背景技术:
1、对话情感识别(emotion recognition in conversation,erc)的目标是在对话中识别每个话语的情感标签。通过提供语境丰富的情感响应,erc可以显著提升对话系统中的用户体验。这一能力在诸如聊天机器人、推荐系统和医疗系统等多个领域中扮演着关键角色。然而,erc任务面临着若干挑战。仅依赖文本数据会导致无法准确识别的问题,因为相似的陈述可能传达着完全不同的情感。因此,采用多种模态(例如文本、音频和视频)对于全面准确地理解对话中的情感表达至关重要。
2、根据输入模态的不同,情感识别模型可以分为两类:基于文本的方法和基于多模态的方法。基于文本的情感识别模型主要关注对话上下文、说话人建模和常识知识。这类模型虽然在某些场景中能有效地捕捉到文本情感,但在遇到模糊或复杂的情感表达时,单靠文本可能无法充分理解情感。基于多模态的情感识别模型通过整合文本、音频和视觉信息,可以更全面地理解对话中的情感表达,当前模型主要集中在多模态特征提取、交互和融合上。
3、在多模态特征的提取方面,不同类型的数据(如文本、音频、视频)需要通过不同的工具和模型进行处理。例如,文本特征可以通过bert或roberta模型进行提取,音频特征可以通过librosa或wav2vec2提取,而视频中的面部表情和手势特征可以通过mtcnn或openface等工具提取,这些工具能有效捕捉不同模态下的情感表达。在多模态特征交互方面,现有技术通过使用rnn、lstm、gru、gcn等神经网络方法进行特征交互,但是这些现有工作并未充分考虑不同模态在特征空间中的异质性。在多模态融合领域,一些方法通过早期融合技术整合特征,即在处理前将来自不同模态的原始特征拼接在一起,输入共享网络。其他方法则采用后期融合策略,让独立的模态特定网络分别处理特征,然后在后期拼接它们的输出,但是这种简单的拼接无法有效的融合处于不同特征空间中的多模态特征。为此,亟需提供一种基于上下文感知和跨模态共享注意力的对话情感识别方法。
技术实现思路
1、针对上述现有技术存在的问题,本发明提供一种基于上下文感知和跨模态共享注意力的对话情感识别方法,该方法能有效解决目前基于各类神经网络的情感识别方法中存在的对不同模态在特征空间中的异质性考虑不足、无法有效的在多种模态之间交互情感信息,从而导致在最后的融合阶段表现不佳的问题,同时,该方法能有效提高情感识别算法的鲁棒性,且能够有效的解决空间异质性问题,具备优异的识别效果。
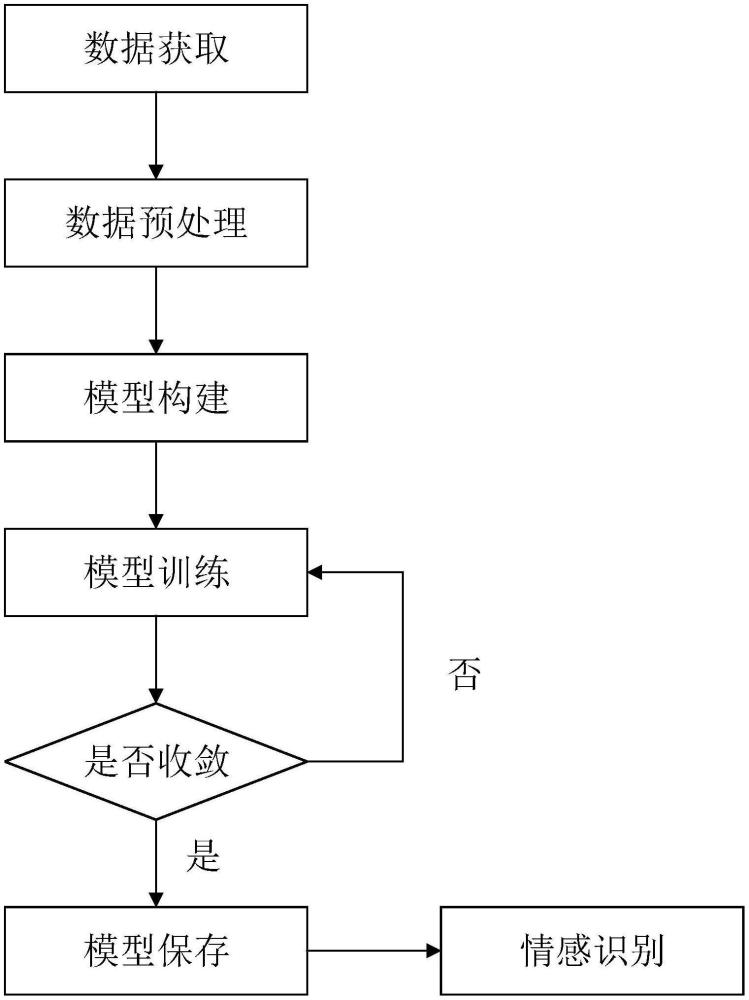
2、为了解决上述技术问题,本发明提供了一种基于上下文感知和跨模态共享注意力的对话情感识别方法,包括以下步骤:
3、步骤一:数据获取;
4、采集不同对话场景下的蕴含上下文的文本以及音频信息形成数据集,完成数据集的构建;
5、步骤二:数据预处理;
6、对构建的数据集进行预处理,以提取相应的模态特征;对于文本信息,提取出每个对话中的上下文特征;对于音频信息,提取出每个语句的音频特征;
7、步骤三:模型构建;
8、分别搭建一个音频上下文感知网络、一个跨模态共享注意力网络及一个自适应融合网络,再将所搭建的三个网络依次连接形成初始情感分类模型;
9、步骤四:模型训练;
10、s41:设置训练最大轮数和训练所需的其他超参数;
11、s42:对步骤一中的数据集进行调整,并按设定比例将调整后的数据集划分为训练集、验证集和测试集;
12、s43:开始对初始情感分类模型进行端到端的训练;
13、在训练的每一轮执行如下操作:判断当前轮次下是否需要调整学习率,将训练集中的文本与音频特征数据作为输入数据输入至初始情感分类模型,通过初始情感分类模型预测生成并输出预定义的情感类别,同时,计算初始情感分类模型预测生成的情感类别和原始类别的误差,计算损失函数并反向传播更新各层的参数,使用当前初始情感分类模型在验证集上进行预测,记录当前损失,并与最小损失做对比,当最小损失更新时,先对训练过程中的初始情感分类模型进行保存,再进行下一轮的训练,若最小损失没有更新时,不对训练过程中的初始情感分类模型进行保存,直接进行下一轮的训练;同时,计算当前轮次和上一轮次损失函数的差值,并将差值和收敛阈值进行比较以判定是否收敛,当收敛时,先对训练过程中的初始情感分类模型进行保存,再进行下一轮的训练,当未收敛时,不对训练过程中的初始情感分类模型进行保存,直接进行下一轮的训练;
14、s44:当损失函数收敛并达到最大训练轮次后,初始情感分类模型训练完毕,得到训练好的情感分类模型;
15、步骤五:模型保存;
16、对训练好的情感分类模型进行保存,形成情感识别模型;
17、步骤六:情感识别;
18、s61:采用特征编码器对所采集到的文本及音频数据进行特征提取,得到文本及音频特征;
19、s62:将文本及音频特征输入至情感识别模型中,利用情感识别模型识别并输出预定义的情况类别;
20、进一步,为了能有效提高情感识别模型的情况识别性能,同时,为了有效提升情感识别模的鲁棒性,在步骤三中,所述音频上下文感知网络由1个位置嵌入层以及5个编码层依次连接构成,其中编码层由2个残差结构依次连接,第一个残差结构由1个多头注意力网络层与1个层归一化网络层构成,第二个残差结构由1个前馈神经网络层与1个层归一化网络层构成,以实现音频中情感信息的聚合;
21、所述跨模态共享注意力网络由2个位置嵌入层以及5个编码层与5个解码层构成,其中每个编码器层由2个残差结构依次连接,第一个残差结构由1个多头注意力网络层构成,第二个残差结构由1个前馈神经网络层与1个层归一化网络层构成,以实现模态1信号的情感汇聚;每个解码层由3个残差结构依次连接,第一个残差结构由1个多头注意力网络层和1个层归一化网络层构成,第二个残差结构由1个跨模态多头注意力网络层和1个层归一化网络层构成,以实现模态2感知模态1的情感信息,第三个残差结构由1个前馈神经网络层与1个层归一化网络层构成,以实现在模态2汇聚情感信息的基础上感知模态1的情感信息;
22、所述自适应融合网络包括1个加性注意力层和1个前馈神经网络层,用于对时间尺度的特征进行融合。
23、进一步,为了有效提升情感分类模型针对上下文的感知能力,在步骤一中,在构建数据集过程中,成对地采集不同对话场景下的文本以及音频信息,并对场景中文本与音频信息进行句子级切分处理,形成具有上下文的数据集。
24、进一步,为了能够有效的提取出文本与音频特征,以确保后期能获得更优异的训练效果,在步骤二中,采用roberta预训练模型进行文本特征的提取,采用采样率为16000的librosa采样模块以及wav2vec2预训练模型进行音频特征的提取。
25、进一步,为了确保训练效果,在步骤四的s41中,设置训练最大轮数大于12次。
26、进一步,为了保证训练后的情感分类模型具有良好的去噪性能,在步骤四的s41中,训练所需的其他超参数包括初始学习率,其中,初始学习率设置为7e-6;在步骤四的s43中,训练过程中采用动态的学习率预热和衰减策略。
27、本发明中,在数据获取过程中,针对不同的对话场景,构建蕴含上下文的文本与音频数据形成数据集,有利于在后续的训练过程中有效的提升模型针对不同对话场景的处理能力,提高泛化性能。通过对构建的数据集进行预处理,以提取相应模态的特征,能有效提高所提取出特征数据的质量。在模型构建过程中,在所构建的情感分类模型中引入音频上下文感知网络,这样,在音频特征输入至音频上下文感知网络中所包含的多头注意力机制网络层中时,能将当前音频特征分别用三个全连接映射作为查询向量(q)、键向量(k)、值向量(v)传入多头注意力机制网络层中的缩放点积网络层,使得音频特征能感知上下文中的情感信息并且进行汇聚,接着经过层归一化网络,使得音频特征规范到标准范围内以方便和原始特征做对比,随后使用残差连接汇聚上下文情感的音频特征和原始的音频特征,使得模型能更加有效的学习两者特征之间的差异之处,结合更为丰富的情感信息;通过前馈神经网络层连接残差结构的输出端,先使用一个全连接层将768维度的音频特征映射为3072维度的特征空间,再将3072维度的音频特征映射到768维的音频空间,使得模型在不同的特征空间之下学习潜在的情感特征,最后统一映射到768维的特征空间之下,接着经过层归一化网络层以方便和进入前馈神经网络层之前的特征进行残差连接专注学习特征差异。因此,通过音频上下文感知网络的引入,可以使该情感识别模型可以更好的汇聚上下文中的情感信息,提升模型的性能。同时,在情感识别模型中引入了跨模态共享注意力网络层,其中,编码器的结构与音频上下文感知网络中的编码器结构类似,解码器的不同之处如下:解码器中的一个残差结构以及第三个残差结构也与音频上下文感知网络的第一个残差结构以及第二个残差结构类似,解码器中的第二个残差结构将当前模态1的特征分别用两个全连接网络层映射作为键向量(k)、值向量(v),将当前模态2的特征使用一个全连接网络层映射作为查询向量(q),使得模态2感知模态1中的情感特征,并且将两个模态使用同一套参数进行学习,使得模态1和模态2的特征在同一特征空间之下相同的情感特征进行靠近,相异的情感特征保持独立,使得模型再汇聚不同模态特征的同时保留其独立性,通过编码器和解码器的堆叠,可以使得模型融合不同层次的特征,这样,通过音频上下文感知网络的引入,可以有效提升该情感识别模型的鲁棒性。最后,在情感识别模型中引入了自适应融合网络层,首先通过加性注意力机制将时间尺度的特征进行融合,接着使用一个全连接网络层对数据的情感进行识别。在对模型训练过程中,每轮均计算模型预测生成的类别和原始类别的误差,计算损失函数并反向传播更新各层的参数,使用当前模型在验证数据集上进行预测,记录当前损失,与最小损失做对比,当最小损失更新时,先对训练过程中的模型进行保存,再进行下一轮的训练,但最小损失没有更新时,不对训练过程中的模型进行保存,直接进行下一轮的训练,直到完成所有的epoch训练,这样,最后保存的情感识别模型便能具备较好的情感识别性能。
28、该方法利用注意力机制和权重共享,使两个模态的共同特征在特征空间中相互靠近,同时保持各自专属特征不受影响。这种方法确保了特征的有效对齐和融合,显著提升了erc任务的整体性能,同时,解决了目前基于各类神经网络的情感识别方法中存在的对不同模态在特征空间中的异质性考虑不足、无法有效的在多种模态之间交互情感信息,从而导致在最后的融合阶段表现不佳的问题。本发明不仅有效提高了情感识别算法的鲁棒性,而且能够有效的解决空间异质性问题,从而具备很优异的识别效果。
- 还没有人留言评论。精彩留言会获得点赞!