一种用于视图建模的数据索引方法及系统与流程
本发明属于体系建模,尤其涉及一种用于视图建模的数据索引方法及系统。
背景技术:
1、随着信息技术的发展,体系建模作为一种有效的组织和管理复杂系统的方法,在军事、商业、科研等领域得到了广泛的应用。然而,现有体系建模工具的设计往往基于传统的理念和技术规范,导致用户在使用这些工具时面临较高的学习曲线。一方面,工具本身的操作流程复杂,需要用户经过长时间的专业培训才能熟练掌握其功能;另一方面,即使用户已经掌握了工具的使用方法,如果不经常使用的话,也会因为记忆衰退而需要重新学习。此外,现有的体系建模工具在处理同一视图中的引用数据时,往往缺乏直观的展示机制,用户不得不花费大量时间去记忆和查找相关的引用数据,这不仅增加了用户的认知负担,还容易引入错误,从而影响建模的速度和质量。
2、如公开号为cn111563283a的专利公开了一种体系建模中快速引用数据的方法,该快速引用数据的方法根据体系建模实践、按照体系架构框架dodaf2.0标准和描述语言updm2.0标准将每张视图可以使用的主要引用数据类型进行分析整理、并定义出每张视图的引用数据列表,然后根据建模过程中产生的数据自动在视图中的引用数据部分将该视图的可引用数据展现出来,用户在建模时可直接从引用数据列表内拖拽所需引用的数据。
3、如授权公告号为cn117271530b的专利公开了一种数联网数字对象语用关系建模方法及装置,所述方法包括:分别确定起点数字对象和终点数字对象的数字对象类型;基于起点数字对象的数字对象类型、终点数字对象的数字对象类型和数字对象之间的语用关系进行数字对象关系定义,得到数字对象关系,语用关系包括:引用关系、使用关系、版本继承关系;将所述数字对象关系作为元数据与所述起点数字对象的元数据一起保存到关系注册表中。
4、以上现有技术存在以下问题:传统的数据检索方法往往因为数据分布不均和多节点查询等问题导致效率低下,尤其是在数据量大且分布广泛的情况下,查找和调取所需数据变得尤为困难,为此本发明提供了一种用于视图建模的数据索引方法及系统。
技术实现思路
1、针对现有技术的不足,本发明提出了一种用于视图建模的数据索引方法及系统,该方法通过构建视图生成分布式索引数据库,并将训练完成的强化调用模型配置到该数据库中,与每一个存储节点建立并行查找映射,以获取每个存储节点对应类型数据的实时存储量;其次,配置视图建模分解模型,并将视图建模需求输入到该模型进行分解,获得视图建模单类需求数据集;同时将单类需求数据集输入到强化调用模型中,利用并行查找映射并行查找并调取所需类型视图建模数据,同时根据实时存储量动态调整数据传输速率;最后,将调取的数据输入到判别模型中进行错误数据判别,将错误数据存储回原位置并进行二次调取,而正确数据则直接反馈到视图建模工具中进行视图建模;本发明通过动态调整数据传输速率和错误数据的二次调取机制,显著提高了视图建模过程中的数据处理效率和准确性,适用于需要高效处理大规模数据的视图建模应用场景。
2、为实现上述目的,本发明提供如下技术方案:
3、一种用于视图建模的数据索引方法,包括:
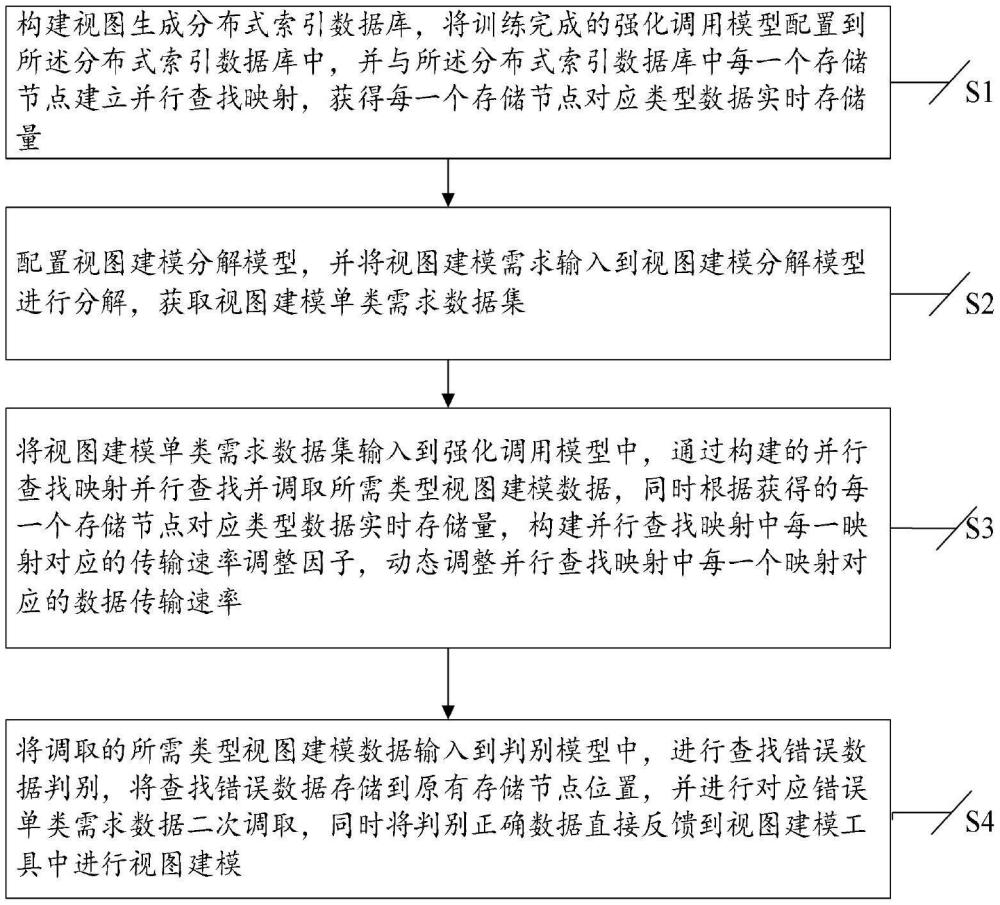
4、s1、构建视图生成分布式索引数据库,将训练完成的强化调用模型配置到分布式索引数据库中,并与分布式索引数据库中每一个存储节点建立并行查找映射,获得每一个存储节点对应类型数据实时存储量;
5、s2、配置视图建模分解模型,并将视图建模需求输入到视图建模分解模型进行分解,获取视图建模单类需求数据集;
6、s3、将视图建模单类需求数据集输入到强化调用模型中,通过构建的并行查找映射并行查找并调取所需类型视图建模数据,同时根据获得的每一个存储节点对应类型数据实时存储量,构建并行查找映射中每一映射对应的传输速率调整因子,动态调整并行查找映射中每一个映射对应的数据传输速率;
7、s4、将调取的所需类型视图建模数据输入到判别模型中,进行查找错误数据判别,将查找错误数据存储到原有存储节点位置,并进行对应错误单类需求数据二次调取,同时将判别正确数据直接反馈到视图建模工具中进行视图建模。
8、具体地,视图生成分布式索引数据库构建的步骤包括:
9、s101、结合树状数据库构建分布式索引数据库框架,并在分布式索引数据库内设置上层并发索引节点和下层存储节点;
10、s102、获取视图建模数据,并将获取的数据输入到配置的分类模型中,获得分类后的视图建模数据,并将分类后的每一类视图建模数据保存在一个存储节点,同时将保存在同一存储节点内的数据表进行分析,获取同一存储节点中数据表所有共有字段和非共有字段;
11、s103、基于树状数据库原理,将共有字段存储到存储节点内的一级共有子节点,将每一个非共有字段一一对应存储在一级共有子节点挂载的二级非共有子节点中;
12、s104、将s102中的分类标签标注在每一个存储节点上,同时根据存储节点和一级共有子节点的关系建立同一存储节点内分类标签与一级共有子节点的索引映射,一级共有子节点与所有二级非共有子节点之间的索引映射和分类标签与所有二级非共有子节点之间的索引映射,并将构建的三个索引映射保存到当前存储节点对应的上层并发索引节点中。
13、具体地,视图生成分布式索引数据库构建的步骤还包括:
14、s105、获取历史视图建模并发查询索引的对应数据类型,并输入到支持向量机构建的并发连接模型中进行训练,获取训练完成的并发连接模型,并将获取到训练完成的并发连接模型内置到上层并发索引节点中;
15、s106、将视图建模需求输入到视图建模分解模型中,获取需求索引数据类型;
16、s107、将获取的需求索引数据类型输入并发连接模型中,根据上层并发索引节点存储的存储节点分类标签,构建获得当前需求索引数据类型对应存储节点间的并发查询索引;
17、s108、当索引完毕将构建的并发查询索引在上层并发索引节点中进行备份保持,当有相同存储节点的数据索引,则直接调用该并发查询索引,进行查询。
18、具体地,s3中构建传输速率调整因子的步骤包括:
19、s301、假设当前视图建模需求经过视图建模分解模型分解,获得m种视图建模单类需求数据;
20、s302、将m种视图建模单类需求数据,通过匹配算法与视图生成分布式索引数据库中存储节点中存储的分类保存数据进行匹配,获得n个存储节点中满足视图建模需求的k个存储节点存储的分类数据,并输出k个存储节点对应类型数据的实时存储量;
21、s303、根据当前满足视图建模需求的k个存储节点对应类型数据的实时存储量,计算得到每一个存储节点对应的节点传输速率调整因子tk;
22、s304、获取传输设备最大传输速率rmax,根据获取的tk和rmax,获得当前匹配得到的存储节点对应的数据传输速率集rk,k=1…k,rk表示满足视图建模需求的第k个存储节点对应的数据传输速率。
23、具体地,s1中强化调用模型构建的步骤包括:
24、s111、根据当前视图建模需求、视图生成分布式索引数据库状态数据和网络传输状态数据,构建当前时刻输入状态st=(m,ns,x,rmax),其中,ns表示s302过程获取的满足m种视图建模单类需求数据的k个存储节点对应保存的数据,x表示保存在上层并发索引节点中的每个存储节点内对应的三个索引映射;
25、s112、根据当前时刻输入状态设置当前状态对应执行动作触发信息,具体为:
26、假设当前视图建模需求包括m种视图建模单类需求数据,通过s302过程对应匹配到k个存储节点,则通过强化调用模型调用并发连接模型,根据k个存储节点对应的分类标签,建立k-并发查询索引,对k个存储节点进行同时查询;
27、根据传输设备最大传输速率rmax,通过s301-s304过程获得k个存储节点对应并发查询索引的数据传输速率集rk,k=1…k,并将每一个获得的数据传输速率集rk,k=1…k配置到对应的查询索引上,对对应存储节点进行数据查询和数据传输。
28、具体地,对k个存储节点进行同时查询步骤包括:
29、配置索引解析模型对k-并发查询索引中每一个查询索引进行解析,获取每一个查询索引中包含的共有字段查询索引和非共有字段查询索引;
30、根据每一个查询索引中包含的共有字段查询索引和非共有字段查询索引和上层并发索引节点中的每个存储节点内对应的三个索引映射,对对应存储节点内的数据进行二次并发索引,获得每个存储节点内视图建模需求对应的数据;
31、当出现新的视图建模需求,则判别该新的视图建模需求是否属于当前视图建模,若属于,则判断新的视图建模需求对应的视图建模单类需求数据类型是否包含于k-并发查询索引中,若包含,则直接通过索引解析模型对新的视图建模需求中的共有字段查询索引和非共有字段查询索引进行解析并配置对应的数据传输速率,同时根据解析结果进行二次并发索引,获取新的视图建模需求对应的查询索引数据;
32、若属于当前视图建模但不包含于k-并发查询索引中,则根据新的视图建模需求对应的需求数据类型通过并发连接模型对k-并发查询索引进行扩充并配置对应的数据传输速率,同时根据扩充查询索引的解析结果进行二次并发索引,获取新的视图建模需求对应的查询索引数据;
33、若不属于当前视图建模但包含于k-并发查询索引中,则直接调用当前k-并发查询索引,进行二次并发索引;
34、若不属于当前视图建模也不包含于k-并发查询索引中,则重复s111-s112过程构建新的k-并发查询索引,进行新的视图建模需求索引。
35、具体地,二次并发索引具体步骤包括:
36、根据索引解析模型解析获取的共有字段查询索引和非共有字段查询索引与每个存储节点对应的三个索引映射;
37、若当前第k个存储节点对应的查询索引包含共有字段查询索引和非共有字段查询索引,则同时调用第k个存储节点对应的分类标签与一级共有子节点的索引映射,一级共有子节点与所有二级非共有子节点之间的索引映射和分类标签与所有二级非共有子节点之间的索引映射;
38、利用分类标签与一级共有子节点的索引映射对共有字段进行查询,同时利用分类标签与第k个存储节点下的所有二级非共有子节点之间的索引映射对非共有字段进行并行查询,同时利用一级共有子节点与所有二级非共有子节点之间的索引映射,将查询到的共有字段和非共有字段进行对应合并,获得第k个存储节点查询到的视图建模需求数据。
39、具体地,二次并发索引具体步骤还包括:
40、若当前第k个存储节点对应的查询索引包含共有字段查询索引或非共有字段查询索引则同时调用第k个存储节点对应的分类标签与一级共有子节点的索引映射或分类标签与所有二级非共有子节点之间的索引映射;
41、当只包含共有字段查询索引,则调用第k个存储节点对应的分类标签与一级共有子节点的索引映射查询获取对应的共有字段;
42、当只包含非共有字段查询索引,则调用第k个存储节点对应的分类标签与所有二级非共有子节点之间的索引映射查询获取对应的非共有字段。
43、一种用于视图建模的数据索引系统,包括:索引构建模块、需求分解模块和数据调取模块;
44、索引构建模块,用于构建视图生成分布式索引数据库,并将强化调用模型配置到该数据库中,与每一个存储节点建立并行查找映射,获取每个存储节点对应类型数据的实时存储量;
45、需求分解模块,用于配置视图建模分解模型,并将视图建模需求输入到视图建模分解模型中进行分解,获取视图建模单类需求数据集;
46、数据调取模块,用于将视图建模单类需求数据集输入到强化调用模型中,并行查找并调取所需类型的视图建模数据。同时,根据实时存储量动态调整并行查找映射中的数据传输速率。
47、一种计算机可读存储介质,其上存储有计算机指令,当计算机指令运行时执行一种用于视图建模的数据索引方法。
48、与现有技术相比,本发明的有益效果是:
49、本发明针对现有技术的不足,通过构建视图生成分布式索引数据库并结合强化调用模型与并发连接模型,有效解决了传统数据检索方法因数据分布不均和多节点查询而导致的效率低下问题,其中,利用树状数据库原理构建分布式索引数据库框架,并通过分类模型将视图建模数据按需存储在不同的存储节点中,同时建立了三级索引映射机制,确保了数据的高效检索与快速定位;其次,通过强化调用模型动态调整数据传输速率,使得数据量大的节点能够获得更高的传输速率,从而加快数据的调取速度;此外,本发明还引入了并发查询索引机制,能够在接收到新的视图建模需求时快速判断并调用合适的二次并发索引,直接对数据进行查询,省去了对上级索引查询的过程,进一步提升了查询效率。
- 还没有人留言评论。精彩留言会获得点赞!