一种基于注意力级联代价体神经网络的双目立体匹配方法
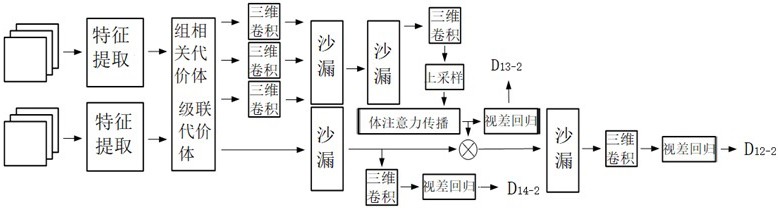
本发明属于图像处理,具体是一种基于注意力级联代价体神经网络的双目立体匹配方法。
背景技术:
1、双目立体视觉是机器视觉中的一种关键技术,通过计算不同视角下两张图像中相同目标的像素视差,并结合双目摄像机的标定信息,得到视差,从而获取目标的深度数据,实现非接触式的物体距离测量。双目立体视觉技术在机器人视觉、航空测绘、医学成像和工业检测等领域得到了广泛应用,始终是机器视觉研究的热点。双目立体匹配算法对双目立体视觉系统性能优劣具有决定性作用。近年来,卷积神经网络在目标检测和识别领域取得了显著进展,对图像处理领域产生了深远的影响。与传统的双目立体匹配算法相比,基于卷积神经网络的算法在准确性和速度上都有显著提升,已成为现在的主流。
2、目前,基于深度学习卷积神经网络的双目立体匹配主要分为两种,一种是非端到端的算法,一种是端到端的算法。非端到端的算法是由卷积神经网络代替传统双目立体匹配过程中的部分步骤,端到端的双目立体匹配方法是指整个双目立体匹配过程全部由卷积神经网络实现,中间没有传统算法参与。相比非端到端的算法,端到端的算法能够更加准确地计算出视差。它利用神经网络的非线性特性和学习能力,对传统算法中的关键步骤进行改进和优化,从而实现更精确的估计结果。
3、然而,尽管基于卷积神经网络的双目立体匹配方法已经取得了显著的发展,现有的双目立体匹配卷积神经网络仍存在一些具有挑战性的问题,如难以处理重复结构、弱纹理或透明物体和遮挡区域,生成的代价体中含有很多冗余信息,网络的计算量较大等。
技术实现思路
1、为改善上述问题,本发明提出了一种基于注意力级联代价体神经网络的双目立体匹配方法。通过多尺度的特征提取和代价体构建丰富了感受野,进而来改善对重复结构、弱纹理或透明物体和遮挡区域的处理效果,通过引入并改进注意力级联代价体和代价体融合方法减少了代价体中的冗余信息和网络的计算量。
2、本发明技术方案如下:
3、一种基于注意力级联代价体神经网络的双目立体匹配方法,步骤如下:
4、步骤s1:收集双目立体匹配数据集。
5、步骤s2:对双目立体匹配数据集进行预处理,将图像随机裁剪为h×w大小并对其归一化得到初始的左、右图像,h和w是随机裁剪后图像的高和宽。
6、步骤s3:将初始的左、右图像分别放进权值共享的特征提取模块,提取得到不同尺寸的左、右特征图。
7、步骤s3对初始的左、右图像分别的操作进一步包括:
8、步骤s3-1:使用三个二维卷积模块对初始的左、右图像进行二维卷积操作。二维卷积模块由二维卷积函数、批归一化函数和relu激活函数构成。经三个二维卷积模块后得到高为h/2、宽为w/2的特征图f3-1-1。
9、步骤s3-2:将f3-1-1放入连续两个基础模块中,其中基础模块由两个二维卷积模块构成。基础模块的第一个二维卷积模块由二维卷积函数、批归一化函数和relu激活函数构成。第二个二维卷积模块由二维卷积函数和批归一化函数构成。f3-1-1经过第一个基础模块输出高为h/2、宽为w/2的特征图f3-2-1,f3-2-1经过第二个基础模块输出高为h/4、宽为w/4大小的特征图f3-2-2。
10、步骤s3-3:将f3-2-2复制四次,分别经过四路不同步长的基础模块得到:高为h/32、宽为w/32的特征图,高为h/16、宽为w/16的特征图,高为h/8、宽为w/8的特征图和高为h/4、宽为w/4的特征图;每路由两个基础模块构成。将得到的四张特征图按由大到小的顺序依次经过上采样模块得到与更大一级的特征图相同大小的特征图,并与更大一级的特征图进行相加,用新得到的结果代替原来的特征图。最后输出四张特征图,分别为:高为h/32、宽为w/32的特征图f3-3-1,高为h/16、宽为w/16的特征图f3-3-2,高为h/8、宽为w/8的特征图f3-3-3,高为h/4、宽为w/4的特征图f3-3-4。
11、步骤s4:对s3特征提取得到的不同尺寸的左、右特征图进行如下操作:用左、右特征图f3-3-1、f3-3-2、f3-3-3分别构建得到高为h/32、宽为w/32的组相关代价体v4-1,高为h/16、宽为w/16的组相关代价体v4-2,高为h/8、宽为w/8的组相关代价体v4-3。用左、右特征图f3-3-4构建得到高为h/4、宽为w/4的级联代价体v4-4。
12、步骤s5:将s4得到的组相关代价体v4-1、v4-2、v4-3各自经过三维卷积模块,得到高为h/32、宽为w/32的代价体v5-1,高为h/16、宽为w/16的代价体v5-2,高为h/8、宽为w/8的代价体v5-3。其中三维卷积模块由三维卷积函数、批归一化函数、relu激活函数构成。
13、步骤s6:将s5得到的代价体v5-1、v5-2、v5-3放入连续两个沙漏模块中,得到高为h/8、宽为w/8的代价体v6-2-4。
14、步骤s6的具体操作进一步包括:
15、步骤s6-1:将v5-3作为第一个沙漏模块的最初的输入,v5-2、v5-1在第一个沙漏模块中的后续处理过程中输入。在第一个沙漏模块内,首先将初始输入的v5-3经过一个三维卷积函数,输出高为h/16、宽为w/16的代价体v6-1-1,将代价体v5-2作为输入与v6-1-1进行串联,得到高为h/16、宽为w/16代价体v6-1-2。然后将v6-1-2经过两个三维卷积模块,得到高为h/16、宽为w/16的代价体v6-1-3。将v6-1-3经过三维卷积函数,得到高为h/16、宽为w/16的代价体v6-1-4。将v5-1作为输入与v6-1-4进行串联,得到高为h/16、宽为w/16的代价体v6-1-5。将v6-5依次经过三维卷积函数、批归一化函数、三维卷积模块、三维转置卷积函数和批归一化函数,得到高为h/16、宽为w/16的代价体v6-1-6。将v6-1-3经过三维卷积函数和批归一化函数,与v6-1-6相加,并将结果经过relu激活函数、三维转置卷积函数和批归一化函数得到高为h/8、宽为w/8的代价体v6-1-7。将v6-7与v5-3相加得到第一个沙漏模块的输出,高为h/8、宽为w/8的代价体v6-1-8。
16、步骤s6-2:将v6-1-8作为第二个沙漏模块的输入,首先经过两个三维卷积模块得到高为h/16、宽为w/16的代价体v6-2-1。将v6-2-1依次经过两个三维卷积模块、三维转置卷积函数、批归一化函数得到高为h/16、宽为w/16的代价体v6-2-2。将v6-2-1经过三维卷积函数、批归一化函数再与v6-2-2相加,再依次经过relu激活函数、三维转置卷积函数得到高为h/8、宽为w/8的代价体v6-2-3。将v6-1-8经过三维卷积函数与v6-2-3相加,再经过relu激活函数得到第二个沙漏模块的输出,高为h/8、宽为w/8的代价体v6-2-4。
17、步骤s7:将v6-2-4依次经过三维卷积模块和三维卷积函数得到高为h/8、宽为w/8的代价体v7-1。
18、步骤s8:将v7-1输入上采样模块得到高为h/4、宽为w/4的代价体v8-1。
19、步骤s9:将v8-1输入体注意力传播模块,得到高为h/4、宽为w/4的注意力权重,用来过滤和抑制级联代价体v4-4中的不相关信息,增多其中的有效信息。其中体注意力传播模块是对v8-1进行置信度估计与采样得到置信度分数,视差采样与评估得到匹配分数,最后将这两种分数通过交叉传播进行整合得到高为h/4、宽为w/4的注意力权重,再挑选其中得分高的一半,最终得到高为h/4、宽为w/4的注意力权重a9-3-2。
20、步骤s9的具体操作进一步包括:
21、步骤s9-1:体注意力传播模块中的置信度估计与采样的操作为:首先对v8-1进行视差回归计算得出预测视差,然后对预测视差进行方差计算、置信度估计和交叉展开,最后得到高为h/4、宽为w/4的置信度分数s9-1-1。
22、视差回归计算的公式如下:
23、
24、其中d为视差,dmax为最大视差值,σ(·)为softmax函数,cd为预测代价,为由每个视差d的概率加权得到的预测视差。视差回归后使用unsqueeze函数增加一个维度得到高为h/4、宽为w/4的输出。
25、预测视差的方差计算的公式如下:
26、
27、其中u为预测视差的方差。预测视差的方差计算后得到高为h/4、宽为w/4的输出。
28、置信度估计的公式如下:
29、
30、其中c为置信度分数,和为可学习的参数。置信度估计后的高为h/4、宽为w/4。
31、交叉展开的操作为:用5个卷积核对输入进行二维卷积,其中每个卷积核的元素只有1个为1,其余都为0。交叉展开后的输出高为h/4、宽为w/4。
32、步骤s9-2:体注意力传播模块中的视差采样与评估的操作为:首先对v8-1进行视差回归计算得出预测视差,然后对预测视差进行交叉展开,结合左、右特征图进行空间变换并做通道维度的平均得到高为h/4、宽为w/4的匹配分数s9-2-1。
33、其中视差回归计算、交叉展开方式同s9-1,得到高为h/4、宽为w/4的输出v9-2-1。然后结合左、右特征图进行空间变换得到高为h/4、宽为w/4的输出v9-2-2。将v9-2-2做通道维度的平均,得到高为h/4、宽为w/4的输出s9-2-1。
34、步骤s9-3:将s9-1-1和s9-2-1进行整合的操作为:首先将s9-1-1和s9-2-1相乘得到高为h/4、宽为w/4的输出,并对其视差维度使用softmax函数。然后使用unsqueeze函数增加一个维度,得到高为h/4、宽为w/4大小的输出s9-2-3。同时,对v8-1进行三维交叉展开:使用5个卷积核对输入进行三维卷积,其中每个卷积核的元素只有1个为1,其余都为0。三维交叉展开后的输出v9-3-1高为h/4、宽为w/4,随后将s9-2-3与v9-3-1相乘并对视差维度求和,得到高为h/4、宽为w/4的输出v9-3-2。在通道维度对v9-3-2使用softmax函数,得到高为h/4、宽为w/4的输出a9-3-1。使用sort函数和gather函数将所有通道中得分高的一半通道挑选出来,得到高为h/4、宽为w/4的注意力权重a9-3-2。
35、步骤s10:将v4-4输入结构同s6的第二个沙漏模块,得到高为h/4、宽为w/4的代价体v10-1。将v10-1与a9-3-2相乘,得到高为h/4、宽为w/4的代价体v10-2。将v10-2输入结构同s6的第二个沙漏模块,得到高为h/4、宽为w/4的输出v10-3。
36、步骤s11:将v10-3经过三维卷积模块,得到高为h/4、宽为w/4的输出v11-1。
37、步骤s12:对v11-1使用squeeze函数及视差回归计算得到高为h/4、宽为w/4的预测视差d12-1,对d12-1使用上采样,最终得到高为h、宽为w的输出预测视差d12-2。
38、以上为推理的步骤,若为训练,则还需要以下步骤:
39、步骤s13:对a9-3-1使用squeeze函数及视差回归计算得到高为h/4、宽为w/4的预测视差d13-1,对d13-1使用上采样,得到高为h、宽为w的输出预测视差d13-2。
40、步骤s14:将v10-1经过三维卷积模块,得到高为h/4、宽为w/4的输出v14-1。对v14-1使用squeeze函数及视差回归计算得到高为h/4、宽为w/4的预测视差d14-1,对d14-1使用上采样,得到高为h、宽为w的输出预测视差d14-2。
41、步骤s15:利用d12-2、d13-2和d14-2构建出最终的损失函数来训练网络。
42、损失函数的公式如下:
43、
44、其中,lf是损失函数。是d12-2的常数系数,是d13-2的常数系数,是d14-2的常数系数。是d12-2,是d13-2,是d14-2,是真实视差。smoothl1是平滑l1损失。
45、本发明的有益效果:与现有技术相比较,本发明使用双目立体数据集进行训练,建立了高效的立体匹配模型。其中,多尺度的特征提取和代价体构建丰富了感受野,改善了对重复结构、弱纹理或透明物体和遮挡区域的处理效果。同时,本发明引入并改进注意力级联代价体和代价体融合方法减少了代价体中的冗余信息和网络的计算量,保持了计算量、参数量和速度的平衡。
- 还没有人留言评论。精彩留言会获得点赞!