一种基于多源异构大数据融合的矿产资源估算系统的制作方法
本发明涉及矿产资源管理,更具体地说,本发明涉及一种基于多源异构大数据融合的矿产资源估算系统。
背景技术:
1、矿产资源作为重要的战略资源,其科学开发和可持续管理是国家经济和环境发展的关键;然而,传统的矿产资源估算方法大多侧重于静态储量计算,通常依赖于地质勘探、钻探和采样等手段,主要关注矿体的现有储量和品位等静态数据;这些传统方法虽然能够提供矿产资源的初步评估,但由于其固有的局限性,难以满足对矿产开采过程的综合评估需求,在动态管理、资源优化以及可持续发展等方面存在显著不足,无法有效支持开采方案优化和矿体开采周期预测。
2、随着遥感技术、物探技术和地理信息系统的进步,多源异构数据逐渐应用于矿产资源估算中,这些数据来源于不同的渠道和技术手段,涵盖了矿产资源的不同维度,能够为精确反映矿体开采潜力、评估开采效益及其对环境的影响提供更加全面和准确的信息;通过多源异构数据的融合,能够弥补传统静态估算方法的不足,为精确反映开采潜力和环境影响提供更多可能;因此,如何在融合多源异构数据的基础上评估矿体开采周期和优化开采方案,已成为矿产资源估算中的关键挑战。
3、鉴于此,本发明提出一种基于多源异构大数据融合的矿产资源估算系统以解决上述问题。
技术实现思路
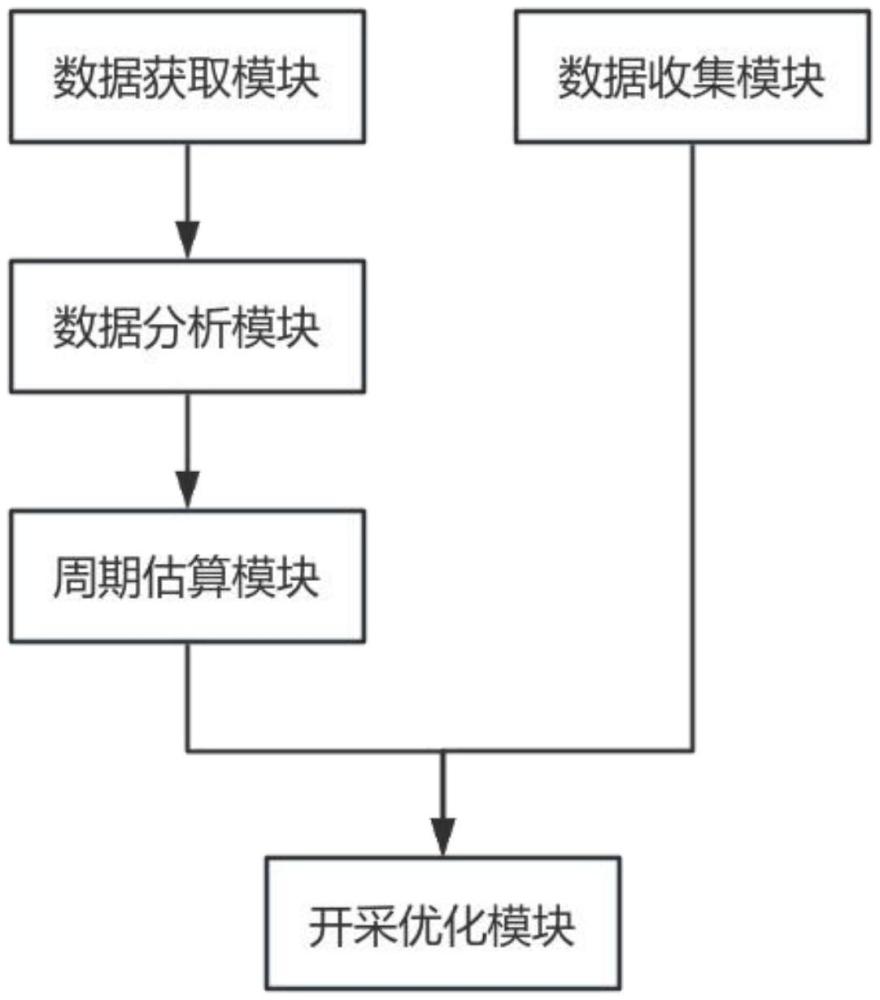
1、为了克服现有技术的上述缺陷,为实现上述目的,本发明提供如下技术方案:一种基于多源异构大数据融合的矿产资源估算系统,包括:
2、数据获取模块,用于获取矿产特征数据;
3、数据分析模块,用于对矿产特征数据进行分析,评估开采方式;
4、周期估算模块,基于开采方式,估算开采周期;
5、数据收集模块,用于收集矿产影响数据;
6、开采优化模块,根据矿产影响数据和开采周期,优化开采方案。
7、进一步地,所述矿产特征数据包括储量数据、品位数据和分布数据;
8、所述评估开采方式的方法包括:
9、对不同的开采方式设置不同的数字标签,并标记为方式标签;将矿产特征数据输入训练好的方式评估模型中,输出对应的方式标签,根据方式标签获取对应的开采方式;方式评估模型的训练过程包括:
10、方式评估模型采用随机森林回归模型,预先收集a组历史数据,历史数据包括矿产特征数据以及与矿产特征数据对应的方式标签;从a组历史数据中采样出b个树子集,每个树子集包括c组历史数据,根据b个树子集训练每棵决策树;其中,a和b均为大于1的整数,且b<a,a=bc;
11、初始化模型参数,包括决策树的数量b,每棵决策树的最大深度d,内部节点最少样本数u;
12、采用一个树子集递归构建第一棵决策树,再依次使用其余b-1个树子集训练出b-1棵决策树;其中每棵决策树的生成过程独立且相同;最终构建出包含b棵决策树的随机森林;
13、在b棵决策树上计算损失函数值;将矿产特征数据输入每棵决策树,记录决策输出,决策输出为每棵决策树输出的方式标签,并标记为预测标签;计算所有预测标签的平均值与真实值间的均方误差,作为损失函数值,真实值为输入决策树中的矿产特征数据对应的方式标签;通过参数调优降低损失函数值,选择损失函数值最小的模型超参数作为方式评估模型的模型超参数。
14、进一步地,所述采用一个树子集递归构建第一棵决策树的方法包括:
15、将一个树子集中的c组历史数据划分成训练集α和验证集β,αp为训练集α中第p组历史数据,p∈[1,α′],α′<c,α′为训练集α中的历史数据数量;用特征th表示矿产特征数据中的一个数据,计算第h个特征th的信息增益率z(α,th);
16、对每一个特征th所对应的信息增益率z(α,th)进行计算,选取最大信息增益率z(α,th)所对应的特征th作为内部节点,并根据最大信息增益率z(α,th)所对应的特征th将训练集α划分成决策子集,每个决策子集中历史数据的数量相同;
17、对于每一个根据最大信息增益率z(α,th)划分的决策子集,重复算法递归过程,直至决策子集中历史数据的数量小于或等于内部节点最少样本数u,或者递归次数大于或等于每棵决策树的最大深度d,递归结束;将训练完成的决策树模型采用验证集β进行评估,最终完成第一棵决策树模型的构建。
18、进一步地,z(α,th)的表达式为:式中,h∈[1,k],k为矿产特征数据中的数据种数,αg为训练集α根据特征th划分的决策子集,g∈[1,k′],k′为大于1的整数,h(αg)为ag的信息熵,h(α)为训练集α的信息熵,其中h(α)和h(αg)的计算方法分别包括:
19、
20、
21、式中,αgp表示αg中第p组历史数据对应的方式标签。
22、进一步地,所述估算开采周期的方法包括:
23、根据储量数据、分布数据和开采方式,估算开采速率范围;预设衰减因子q;开采速率的变化表达式为:v(t)=vmin+(vmax-vmin)×e-qt;式中,v(t)为开采时间为t时对应的开采速率,vmin为开采速率范围中的最小开采速率,vmax为开采速率范围中的最大开采速率,e为自然常数,t为开采时间;储量数据的表达式为:式中,s为储量数据,t为开采周期;采用数值求解方法从储量数据的表达式中求解出开采周期的数值。
24、进一步地,所述估算开采速率范围的步骤包括:
25、步骤a1:设定搜索区间[m,n]和精度ε;
26、步骤a2:确定搜索数列f(x);
27、步骤a3:从搜索数列中确定划分系数f(r);
28、步骤a4:采用划分系数对搜索区间进行划分,获取两个点ψ1和ψ2;
29、步骤a5:分别计算ψ1和ψ2对应的可行度;
30、步骤a6:对搜索区间进行更新;
31、步骤a7:计算搜索区间的宽度υ;
32、步骤a8:若宽度υ小于或等于精度ε,则将搜索区间作为开采速率范围;若宽度υ大于精度ε,则返回步骤a3。
33、进一步地,所述步骤a2中,搜索数列
34、所述步骤a3中,确定划分系数f(r)的方法为:计算初始划分系数δ′,将搜索数列中的每个数值分别减去初始划分系数,获取数值差值;将每个数值差值由小到大进行排序,获取排在最前面的数值差值对应的搜索数列中的数值,并作为划分系数f(r);
35、所述步骤a4中,式中,f(r-2)为搜索数列中排在划分系数f(r)前两位的数值,f(r-1)为搜索数列中排在划分系数f(r)前一位的数值;
36、所述步骤a5中,可行度的获取方法为:储量数据、分布数据、方式标签以及点对应的数值作为分析数据,将分析数据输入训练好的速率估算模型中,预测出对应的可行度;
37、所述步骤a6中,对搜索区间进行更新的方法为:将ψ1对应的可行度标记为第一可行度将ψ2对应的可行度标记为第二可行度若则搜索区间更新为即若则搜索区间更新为即
38、所述步骤a7中,将搜索区间的最大值减去最小值,获取宽度υ。
39、进一步地,速率估算模型的训练过程包括:
40、预先收集y组分析数据,对y组分析数据均设置对应的可行度,y为大于1的整数,将分析数据与对应的可行度转换为对应的一组特征向量;
41、将每组特征向量作为速率估算模型的输入,所述速率估算模型以每组分析数据对应的一组预测可行度作为输出,以每组分析数据对应的实际可行度作为预测目标,实际可行度即为预先设置的与分析数据对应的可行度;以最小化所有分析数据的预测误差之和作为训练目标;对速率估算模型进行训练,直至预测误差之和达到收敛时停止训练;所述速率估算模型为深度神经网络模型。
42、进一步地,所述矿产影响数据包括历史市场数据和环境数据;所述历史市场数据包括历史供需数据和历史价格数据;历史供需数据为历史时刻矿产资源的生产量和消费量;历史价格数据为历史时刻矿产资源的交易价格;
43、将历史供需数据输入供需预测模型中,预测未来供需数据,未来供需数据包括开采周期内矿产资源的生产量和消费量;将历史价格数据输入价格预测模型中,预测未来价格数据,未来预测价格包括开采周期内矿产资源的交易价格;供需预测模型和价格预测模型均为循环神经网络模型中的lstm模型;根据未来供需数据和未来价格数据,对开采周期内的开采方案进行优化,开采方案包括开采速率和开采方式;
44、优化开采方案的步骤包括:
45、步骤b1:构建n个开采集合,对不同的开采集合设置不同的数字标签,并标记为集合标签,根据所有集合标签构建开采矩阵;
46、步骤b2:预设约束表容量和最大迭代次数,确定评价函数;
47、步骤b3:从开采矩阵中随机选取一个集合标签作为当前解,并加入约束表中,将当前解作为最优解;
48、步骤b4:根据开采矩阵,获取与当前解相邻的集合标签,并作为相邻解;
49、步骤b5:计算每个相邻解的评价值;
50、步骤b6:判断每个相邻解是否存在于约束表中;若存在,则将对应相邻解标记为约束解;若不存在,则将对应相邻解作为候选解;
51、步骤b7:将评价值最大的候选解标记为最优候选解,若约束解的评价值大于最优候选解的评价值,则将最优候选解更新为约束解,若约束解的评价值小于或等于最优候选解的评价值,则删除约束解;
52、步骤b8:将当前解更新为最优候选解,并判断是否更新最优解;将所有候选解均加入约束表中;
53、步骤b9:判断迭代次数是否等于最大迭代次数;若是,则迭代终止,获取最优解对应集合标签所对应的开采集合;若否,则令迭代次数加一,并返回步骤b4。
54、进一步地,所述步骤b1中,从所有开采方式中随机选取一种开采方式,从开采速率范围中随机选取一个数值,构建一个开采集合,共构建n个开采集合,n个开采集合均不相同;
55、所述步骤b2中,评价函数的表达式为:式中,f为评价值,jx为经济效益,hy为环境影响度,均为权重系数;
56、经济效益和环境影响度的获取方法为:根据未来供需数据和未来价格数据,获取预测供需数据和预测价格数据;预测供需数据为未来供需数据中的一个数据,预测价格数据为未来价格数据中的一个数据,预测供需数据和预测价格数据对应的时刻相同;将预测供需数据、预测价格数据和集合标签作为测试数据,将测试数据输入训练好的效益预测模型,预测出对应的经济效益;将环境数据和集合标签作为研究数据,将研究数据输入训练好的影响预测模型中,预测出对应的环境影响度;效益预测模型和影响预测模型的训练过程均与速率估算模型的训练过程一致,并且均为神经网络模型;
57、所述步骤b8中,判断是否更新最优解的方法为:若最优候选解的评价值大于最优解的评价值,则将最优解更新为最优候选解;若最优候选解的评价值小于或等于最优解的评价值,则不对最优解进行更新。
58、本发明一种基于多源异构大数据融合的矿产资源估算系统的技术效果和优点:
59、通过获取矿产特征数据,初步评估开采方式;并且基于开采方式,实现对矿产资源的开采速率范围和开采周期的动态精确估算;同时,融合多源异构数据,包括环境数据和历史市场数据,实现开采周期内的开采方式和开采速率全周期动态优化;不仅克服了传统静态估算方法的局限性,增强矿产资源的动态管理与优化能力,还能通过优化开采方案在经济效益和环境影响之间取得平衡,提升矿产资源的经济效益和环境保护水平,从而提高矿产开发的科学性和可持续性。
- 还没有人留言评论。精彩留言会获得点赞!