一种基于PLTSK的偏标记学习方法
本发明涉及一种基于pltsk的偏标记学习方法,其属于偏标记学习的。
背景技术:
1、机器学习在分类和回归等有监督学习任务中取得了巨大成功。然而,手工标记数据的高成本使得获取可靠信息更具有挑战性。训练模型时对大量数据的需求不可避免地导致某些实例带有歧义标签。因此,弱监督学习成为了一个重要的研究方向。
2、偏标记学习(pll)作为弱监督学习框架的一种,旨在从带有模糊标签的数据中识别出唯一的真实标签,以归纳出多类分类器。这种学习框架在现实社会中有着广泛的应用,比如在自动人脸命名中,可以将图片中检测出的每个人脸作为一个实例,并从相关标题中提取的名字作为候选标签,但每个人脸与具体名字之间的真实对应关系是未知的;在基于众包的分类任务中,当标签空间非常庞大时(可能包含数百至数千个标签),标注者难以准确选择真实标签,因而倾向于提供查询到的不准确标签信息; 在词性标注(pos)任务中,一个单词可能对应多个词性标签,其中只有一个是正确的,学习一个能够准确执行词性标注的模型。
3、tsk模糊系统是一种基于模糊推理的经典的智能模型,因其强大的学习能力,已被广泛应用于多个领域。tsk模糊系统的核心是模糊推理规则。与mamdani模糊系统中使用的模糊集不同,tsk模糊系统的规则后件由输入的精确数值或函数构成,这一特性使得其在处理具体应用时更为精确和灵活。
4、偏标记学习(pll)的主要挑战在于,训练实例的真实标签对于学习算法而言是不可直接获得的。处理pll问题的核心策略在于消除候选标签的歧义,具体而言,即通过区分各个候选标签的置信度来恢复真实的标签信息。目前的消歧方法大致可以分为两类:一种是基于平均的方法,它平等地处理每个候选标签,并试图通过平衡候选标签与非候选标签的分布来进行学习。例如,某些研究尝试区分候选标签的平均分配与非候选标签的分配,而其他一些研究则通过分析邻居的候选标签来对新实例进行分类。这种策略虽然简单易实现,但存在一个显著的问题,真实标签的输出可能会被假阳性标签的输出所淹没,导致模型性能显著下降。另一种消歧策略是基于识别的消歧。这种策略将真实标签视为一个潜在变量,并通过模型训练过程中的迭代优化来确定。一般来说,迭代优化过程(如em)用于预测潜在变量,这可以通过似然最大值或裕度最大方法来实现。虽然这种策略通常比基于平均的方法更为有效,但它们依赖于从候选标签集中识别出单一的真实标签,若某一迭代产生了不准确的预测,则可能严重影响模型后续训练的效果。除了上述策略外,一些工作通过特征感知消歧,试图挖掘特征空间中被忽略的信息并充分利用它。例如,一些方法利用训练数据中的图结构生成候选标签集的标签置信度。
5、然而,这些方法通常未能充分利用标签空间中的非候选标签信息,并且未考虑特征空间噪声导致的错误消歧问题,这使得模型对实例敏感,容易发生误判。
技术实现思路
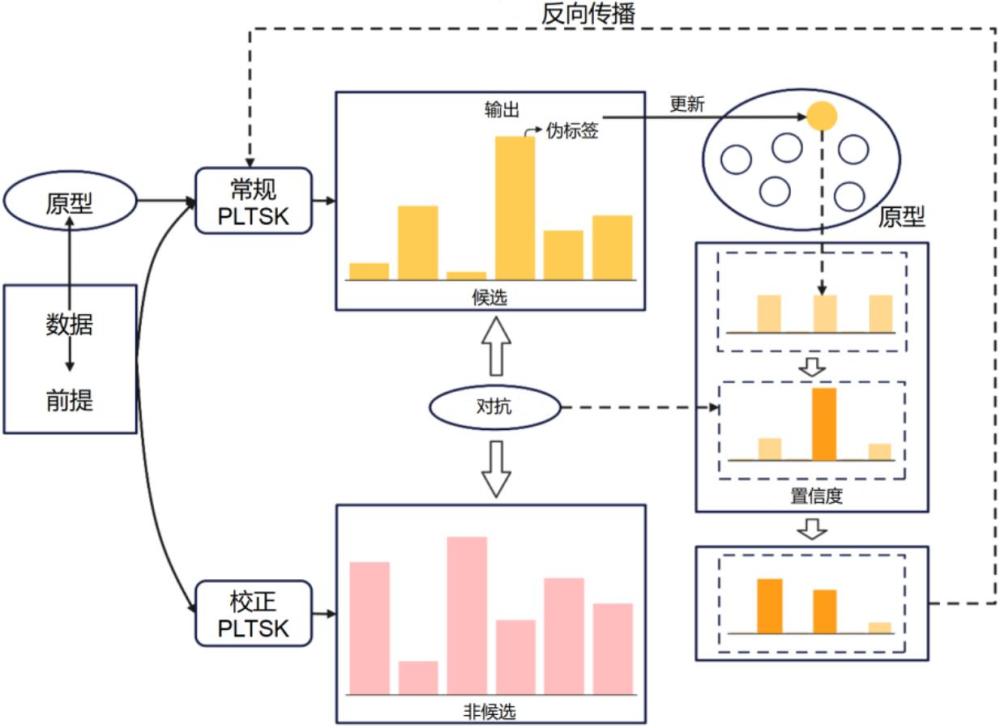
1、为解决现有技术中存在的问题,本发明提供一种基于pltsk的偏标记学习方法,该方法通过引入非候选标签信息来校正错误消歧标签,构建了适用于偏标记学习的 pltsk模糊系统,首次将模糊理论应用于解决偏标记学习问题。具有重要的技术价值和应用前景。采用双重特征输入和两阶段消歧策略,设计ploctsk偏标记模糊系统,实现了两个pltsk模糊系统的集成。
2、第一步:修改tsk模糊系统的后件输出部分,引入置信度矩阵,提出适用于偏标记学习(pll)的pltsk模糊系统,以增强对候选标签的处理能力。
3、第二步:构建集成两个pltsk模糊系统的ploctsk框架,常规pltsk模糊系统基于原型进行初步消歧,pltsk校正模糊系统专注于学习精确的非候选标签用于纠正常规pltsk中的错误消歧标签。通过交替迭代,使两个pltsk系统相互促进,有效提升消歧效果,最大化已消歧标签与非真标签之间的区分度。
4、第三步:在数据集(包括四个合成数据集和五个真实世界数据集)上进行广泛实验,该方法在性能表现上优于六个现有的偏标记学习算法。
5、进一步地, 一种基于pltsk的偏标记学习方法,包括以下步骤:
6、s1.修改tsk模糊系统的后件输出部分,引入置信度矩阵;tsk模糊系统的输出为:
7、
8、其中,代表第r个规则的激活水平,是与模糊集关联的隶属函数,为第r条规则的标准化激活水平;
9、选择的htsk-ln-relu作为分类模型,对htsk-ln-relu的后件输出部分及损失函数部分进行修改,提出常规pltsk模糊系统;在pltsk模糊系统中,用于描述规则前件中模糊集的隶属函数如下:
10、
11、其中,,分别为模糊集的中心和标准差;
12、获得样本在每条规则上的隶属度之后,采用softmax函数并将隶属函数更改为平均运算,计算样本在每条规则的激活水平:
13、
14、标准化激活水平表示如下:
15、
16、为了更加直观地表示去模糊化过程,规则后件的输入重写为:
17、
18、其中,
19、
20、采用层归一化缩放,在改写后件的输入后加入layernorm层,在layernorm层后引入了relu函数;
21、
22、规则后件的输入最终重写为:
23、
24、
25、新的后件输出表示为:
26、
27、pltsk校正模糊系统最终的输出为:
28、
29、定义标签置信度矩阵,并使用均匀分布对其初始化,其中 表示第个标签是第i个实例的真实标签的置信度;
30、定义非候选标签置信度矩阵作为校正模型的训练目标;其中表示第个标签不是第i个实例的真实标签的置信度;
31、s2.构建集成两个pltsk模糊系统的ploctsk框架,常规pltsk模糊系统基于原型进行初步消歧,pltsk校正模糊系统专注于学习精确的非候选标签用于纠正常规pltsk中的错误消歧标签;
32、通过常规pltsk模糊系统与pltsk校正模糊系统之间的对抗关系,在整个ploctsk训练的过程中,动态的调整消歧后的标签置信度矩阵;然后再根据校正后的标签置信度,在新一轮迭代中训练常规pltsk模型;
33、pltsk校正模糊系统为:
34、
35、pltsk校正模糊系统是一个多标签问题,预测实例的非真标签;理想状态下两个分类器的输出结果是互补的;二者之间的互补状态表示为;因此,pltsk校正分类器的优化目标为:
36、
37、
38、其中:是长度为l的全1向量;通过使用adamw优化器,采用反向传播计算的梯度来最小化公式,将有价值的信息传递到标签置信度矩阵,优化样本的标签置信度矩阵;
39、在pltsk校正模型中,消歧后的标签置信度被作为损失函数的参数,用于在纠正消歧过程中进行调整,并将修正后的标签置信度用来指导下一轮消歧的更新;
40、采用基于原型的消歧方法,通过校正模型与消歧过程的反复交互,以迭代方式推动性能改进,直至收敛。
41、本发明与现有技术相比,其显著优点在于:(1)采用双重特征输入和两阶段消歧策略,增强了模型的消歧能力和准确性。(2)通过引入非候选标签信息,ploctsk 方法能够有效纠正常规 pltsk 模糊系统中的错误消歧标签,从而提升模型的鲁棒性和准确性。(3)通过交替迭代的方式优化消歧过程,最大化消歧标签与非候选标签之间的距离,确保更精确的标签识别。(4)ploctsk 不依赖于特定的特征空间结构,能够灵活适应多种类型的数据集,尤其在高维特征或标签的数据集中表现出色。(5)在真实世界数据集上的实验结果表明,ploctsk 方法在偏标记学习任务中表现优异,相较于其他现有算法具有更高的分类性能和消歧能力。
- 还没有人留言评论。精彩留言会获得点赞!