一种基于二次重构的视频异常事件并行检测方法
本发明属于计算机视觉领域中的视频异常检测技术,具体涉及一种基于二次重构的视频异常事件并行检测技术。
背景技术:
1、传统的视频监控技术随着网络的普及和摄像技术的发展逐渐过时,智能化的视频监控成为发展趋势。仅依赖人力管理广泛分布的视频监控设施,将面临巨大的工作负担、低报警准确度和缓慢的响应速度等问题,提高视频异常行为检测任务的智能化至关重要。目前基于重构的异常行为检测方法希望重构模型在重构正常视频帧时得到较小的重构误差,重构异常视频帧时得到较大的重构误差。然而由于重构模型在使用卷积神经网络继承了其强大的表征能力,这会导致异常帧在重构时有概率得到较小的重构误差,从而被检测为正常帧,使得检测结果不准确。
2、视频异常行为检测方法严重依赖于深度学习,需要大量资源对模型进行调参,在检测效率上仍有局限性的问题,在对监控视频进行检测时需要大量的时间对数据进行信息提取并对检测模型进行训练,无法合理分配检测模型运行所需算力,减少总体运行时间。
技术实现思路
1、为了解决现有技术存在的问题,本发明提供了一种基于二次重构的视频异常事件并行检测技术,并在其中引入记忆力模块,该模块可以记忆正常模式进行对比,用以有效提高视频异常事件检测的准确率。
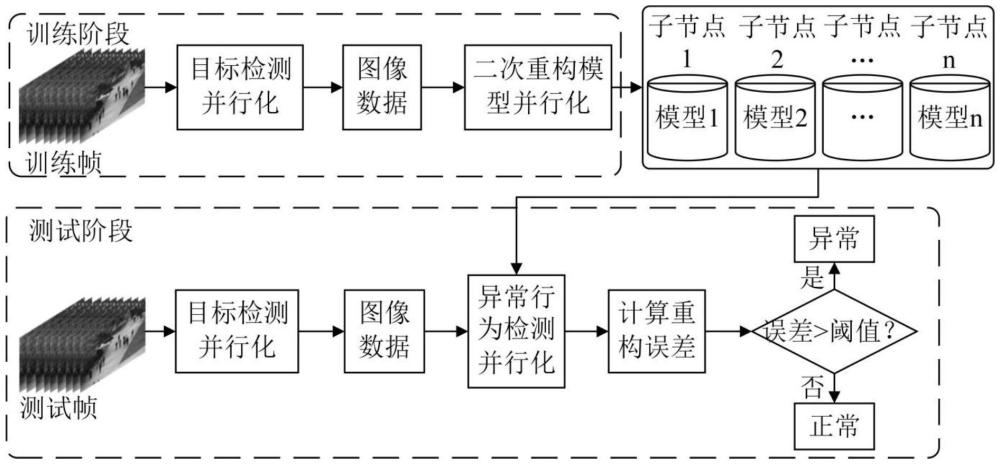
2、本发明实施例第一方面提供了一种基于二次重构的视频异常事件并行检测方法,其特征在于,包括:
3、s1:收集所需视频集,将其进行预处理,得到一张或多张训练视频帧和测试视频帧;
4、s2:建立并行计算策略,将其用于视频异常事件检测中;
5、s3:对所述训练视频帧和/或测试视频帧进行目标检测,用以得到训练目标对象和/或测试目标对象;
6、s4:将所述训练目标对象输入至第一次重构模型中对模型进行训练,得到第一次重构目标对象;
7、s5:将所述训练目标对象和所述第一次重构目标对象共同输入第二次重构模型中对模型进行训练,从而构建二次重构模型;
8、s6:将测试目标对象输入所述二次重构模型中,得到第一次重构分数和/或第二次重构分数;
9、s7:对两次的重构分数进行加权计算,得到总重构分数,以此检测视频帧中是否存在异常事件。
10、进一步,所述s2提出一种并行计算策略,将其用于视频异常事件检测中,在目标检测、建立模型、异常检测等步骤中进行应用,以减少各个步骤所需时间,提高整体检测方法的检测效率
11、进一步,所述s3:对所述训练视频帧和/或测试视频帧进行目标检测,用以得到训练目标对象和/或测试目标对象,包括:
12、把所需的监控视频集分配给并行计算平台中不同计算节点,每个计算节点各自独立运行目标检测算法,多个计算节点共同完成目标检测提取任务。
13、进一步,所述目标检测提取任务,包括:
14、将所需的监控视频集存储在同一个路径下,以便并行计算平台可以访问这些视频数据;
15、创建sparkconf和sparkcontext,所述sparkcontext为spark应用程序的入口点,负责与集群管理器进行通信,创建rdd、累加器和广播变量等并行计算核心组件,并提供一些常用的操作函数,所述sparkconf为spark应用程序的配置类,可以设置所述spark应用程序的各种参数;
16、将包含视频数据路径的列表并行化为所述rdd,利用并行计算平台对监控视频数据进行划分,将大任务分割成多个子任务;
17、根据划分好的所述子任务的数量,动态分配计算节点,使每个计算节点独立地运行所述目标检测提取任务;
18、每个计算节点处理完自己的子任务后得到对象信息,将所述目标检测提取任务的结果汇总到一个中央存储位置或数据结构中;
19、当所有子任务都完成了目标检测并且结果经过合并和处理,监控视频的目标检测提取任务完成,将结果收集回驱动程序节点。
20、进一步,所述s4:将所述训练目标对象输入至第一次重构模型中对模型进行训练,得到第一次重构目标对象,包括:
21、通过yolov5算法从所述训练视频帧中提取感兴趣的目标对象,所述目标对象可以是视频帧中的人、车辆或任何其他感兴趣的对象;
22、所述第一次重构模型为生成对抗网络结构,该结构包括生成器和鉴别器部分,其中生成器由编码器、解码器、跳跃连接部分和记忆力模块组成;
23、将所述目标对象输入到自编码器网络的编码器部分,编码器通过多次卷积和池化操作处理所述目标对象,减小特征图的尺寸,并增加通道数,以获得潜在的特征图;将所述特征图输入解码器部分,解码器执行上采样操作,将所述特征图的尺寸还原到输入图像的原始尺寸;
24、所述自编码器网络,为了更好地保留输入图像的细节信息,采用跳跃连接将不同层次的特征图进行连接,即拼接每层特征图与对应层的重构特征图,最终生成与输入视频帧尺寸相同的第一次重构视频帧,即第一次重构目标对象。
25、在第一次重构目标对象生成后,将其与所述目标对象进行对抗性训练,以进一步提高第一次重构模型的能力。这个对抗性训练的目标是拉近第一次重构帧和正常训练视频帧之间的距离,使第一次重构模型更好地学习并捕捉正常帧的特征和分布。
26、进一步,所述s5:将所述训练目标对象和所述第一次重构目标对象共同输入第二次重构模型中对模型进行训练,从而构建二次重构模型,包括:
27、所述第二次重构模型为生成对抗网络结构,该结构包括生成器和鉴别器部分,其中生成器由编码器、解码器、跳跃连接部分和记忆力模块组成,所述生成器的训练方法为:
28、通过yolov5算法从所述训练视频帧中提取感兴趣的目标对象,和所述第一次重构目标对象输入到所述编码器中,经过多次卷积池化处理后,得到每层不同尺寸不同通道数的第一特征图,在最低层得到潜在特征;
29、将所述潜在特征输入记忆力模块中学习建模正常行为并并且存储正常模式;
30、将所述潜在特征输入解码器,解码器执行上采样操作,生成第二特征图,同时采用跳跃连接将与所述第二特征图同层的所述第一特征图与所述第二特征图进行连接以得到新的第二特征图,最终将第二特征图的尺寸还原到输入图像的原始尺寸,得到与输入帧尺寸相同的第二次重构视频帧,即第二次重构目标对象;
31、将第二次重构目标对象与训练目标对象进行对抗性训练,其中所述第一次重构目标对象生成的所述第二次重构目标对象和所述第一次重构目标对象对应的所述训练目标对象进行对抗,所述训练目标对象生成的所述第一次重构目标对象与对应的所述训练目标对象进行对抗,所述第一次重构目标对象与所述第二次重构目标对象进行对抗。通过对抗训练拉近两两之间的距离,使第二次重构模型更好地学习并捕捉正常帧的特征和分布。
32、进一步,所述s5:将所述训练目标对象和所述第一次重构目标对象共同输入第二次重构模型中对模型进行训练,从而构建二次重构模型,还包括:
33、通过记忆力模块学习建模正常行为并存储正常模式:
34、记忆力模块为存储一个大小为n×c的矩阵,定义为m∈rn×c,其中n表示记忆力模块包含n个有效特征信息,c表示特征信息的值,与所述编码器得到的所述潜在特征z维度相同,其计算公式为:
35、
36、其中mi表示所述记忆力模块中的存储项,向量ω∈r1×n为针对所述潜在特征z计算得到的注意力系数;
37、利用非指数形式的softmax函数,计算出权重ωi,计算公式如下:
38、
39、其中d(·)为cosine相似度,其计算公式如下:
40、
41、虽然采用了注意力寻址方式,有些异常仍可能通过的复杂组合被很好的重构。为了解决这个问题,采用了硬收缩(hard shrinkage)策略,只有当注意力权重大于设定的阈值时才有效,否则为0:
42、
43、然而所述硬收缩策略由于不能反向传播无法直接实现,因此借用relu函数重新实现:
44、
45、其中max(·,·)为relu函数,ε为很小的正数项,阈值λ通常设置为[1/n,3/n]之间;归一化权重,其计算公式为:
46、
47、可得到最终含有记忆力模块的变换公式,其计算公式如下:
48、
49、进一步,所述s4:将所述训练目标对象输入至第一次重构模型中对模型进行训练,得到第一次重构目标对象,还包括:
50、为了在第一次重构中使第一次重构帧与输入帧距离尽可能缩小,在外观层面和运动层面进行约束,外观约束lapp1由梯度约束lgc1和强度约束lsc1构成,所述梯度约束lgc1和所述强度约束lsc1计算方式如下:
51、
52、其中,x表示所述训练目标对象,表示所述第一次重构目标对象,a,b表示所述训练目标对象的像素的水平和垂直坐标;
53、由所述梯度约束lgc1和所述强度约束lsc1,得到所述外观约束lapp1,具体计算方法如下:
54、
55、其中m:n=1:1;
56、所述运动约束lopt1是光流约束,计算过程如下所示:
57、
58、其中t表示第t帧;
59、所述第一次重构模型的目标函数为:
60、l1=αlapp1+βlopt1。
61、进一步,所述s5:将所述训练目标对象和所述第一次重构目标对象共同输入第二次重构模型中对模型进行训练,从而构建二次重构模型,还包括:
62、为了在第二次重构中使正常帧与第二次重构帧距离尽可能缩小,在外观层面和运动层面进行约束,外观约束lapp2由梯度约束lgc2和强度约束lsc2构成,所述运动约束lopt2是所述光流约束,两者计算方式与所述第一次重构模型中所述外观约束lapp1和所述运动约束lopt1的计算方式相同,仅将其中的改为表示第二次重构目标对象;
63、在记忆模块中,进一步约束ω的稀疏性,对其进行正则化约束,公式如下:
64、
65、其中q为记忆力模块数量,n为一个记忆力模块中内存项数量,ωi,k为查询特征和记忆内存项的相似性系数;
66、具体的优化过程为:
67、在训练鉴别器时,固定生成器,目标是使鉴别器可以准确地区分第二次重构帧与正常训练帧,以提高鉴别器的鉴别能力,鉴别器的损失函数如下所示:
68、
69、其中,i、j是帧的索引,d(·)∈[0,1],l(·,·)表示两者之间差的绝对值;
70、当训练生成器时,固定鉴别器,目标是使生成器生成的重构帧和原始训练帧无法被鉴别器区分,以提高生成器的生成能力,生成器的损失函数如下所示:
71、
72、生成器的训练目标是仅重构正常帧,无法重构异常帧,即生成器和鉴别器仅针对正常帧进行优化,生成器函数如下所示:
73、
74、其中λapp2、λopt2、λadv和λm分别是外观损失、运动损失、生成器损失和记忆力模块损失的权重因子;
75、鉴别器的目标函数如下所示:
76、
77、进一步,所述s6:将测试目标对象输入所述二次重构模型中,得到第一次重构分数和/或第二次重构分数,包括:
78、第一次重构误差和第二次重构误差,所述第一次重构误差和/或所述第二次重构误差
79、计算公式为:
80、
81、其中x′代表所述测试目标对象,代表所述第一次重构目标对象,代表所述第二次重构目标对象;
82、通过归一化方法对所述第一次重构误差和/或所述第二次重构误差进行归一化得到所述第一次重构分数score(x′)1和所述第二次重构分数score(x′)2,计算如下所示:
83、
84、其中,s1是每个所述测试目标对象的第一次重构误差总集合,s2是每个所述测试目标对象的第二次重构误差总集合。
85、进一步,所述s7:对所述第一次重构分数和所述第二次重构分数进行加权计算,得到总重构分数,以此检测视频帧中是否存在异常事件,包括:
86、总重构分数的计算公式为:
87、score(x′)=λ1score(x′)1+λ2score(x′)2
88、其中,λ1为所述第一次重构分数的权重,λ2为所述第二次重构分数的权重,
89、当score(x′)小于阈值时,意味着视频帧中只存在正常行为,反之意味着视频帧中包含异常行为。
90、本发明提出了二次重构模型,该模型通过对使视频帧连续进行两次重构,加大异常帧在重构后与原始帧的重构误差,凸显异常区域,以便于更好地检测识别视频中的异常事件。视频帧输入到该模型中,模型会对帧进行两次重构,以获得不同尺度的重构帧,每个尺度捕获不同级别的特征和细节信息,若视频帧中存在异常事件,异常事件在两次重构中会引起不同程度的异常信号,用以更好地检测到存在异常事件的视频帧。同时在二次重构模型中引入记忆力模块,该模块能够帮助检测模型记录正常帧特征分布模式,使模型在难以区分视频帧时有必要的参考模式,进一步区分正常帧与异常帧。为减少总体运行时间,合理分配检测模型运行,本发明采用了并行计算策略。该策略将单任务分成多任务模式,通过多个工作节点同时进行任务求解。
- 还没有人留言评论。精彩留言会获得点赞!