一种面向室外场景的高效多视图立体重建方法及系统
本发明涉及多视图三维重建领域、计算机图形学与计算机视觉领域,具体涉及一种面向室外场景的高效多视图立体重建方法及系统。
背景技术:
1、近年来,基于深度学习的多视图立体重建因其在无人驾驶、虚拟现实、增强现实等领域的广泛应用,引起了人们越来越多的兴趣。尽管现有的多视图立体重建方法已经在室内可控环境下取得了较大的研究进展,但是这些方法难以处理在室外复杂场景下的物体之间的遮挡、非朗伯表面、光照不均匀和弱纹理区域等问题。虽然最近的研究通过引入视觉转换器模块,使网络具备关注全局上下文的能力,增强了三维模型的质量,但是由于自注意力具有二次复杂度问题,这些引入视觉转换器的多视图立体重建方法需要消耗大量的运行时间和较高的显存容量,严重影响了多视图立体三维重建技术的发展和应用。因此,设计一种面向室外场景的高效多视图立体重建方法具有重要的研究意义。
2、中国专利公开号为“cn115908723a”,名称为“基于区间感知的极限引导多视图立体重建方法”,该方法首先通过极线引导聚合子模块来捕获图像内部和跨图像的全局上下文信息,然后利用可见融合子模块生成代价体,最后使用深度估计模块计算损失。虽然该方法在一定程度上应对了多视图立体重建网络跨信息特征提取能力弱的问题,但是既无法解决物体之间的遮挡、非朗伯表面、光照不均匀和弱纹理区域等问题,又不能有效的处理基于室外场景的多视图立体重建过程中的时间效率低、模型参数量大和模型计算量大等问题。所以设计一种能够在真实室外场景下高效的完成多视图立体重建任务的方法是本发明重点解决的关键问题。
技术实现思路
1、针对现有技术的不足,本发明提供了一种面向室外场景的高效多视图立体重建方法及系统,可以在室外复杂场景下从大规模图像中快速计算得到高质量重建场景的稠密点云模型,并且较现有的多视图立体方法具有更快的运行时间、更少的计算成本和更小的存储成本,促进面向室外场景的多视图立体重建技术的进步。同时本发明可以提高训练的稳定性和性能,具有高泛化性。
2、本发明为了实现上述目的具体采用以下技术方案:
3、一种面向室外场景的高效多视图立体重建方法,包括如下步骤:
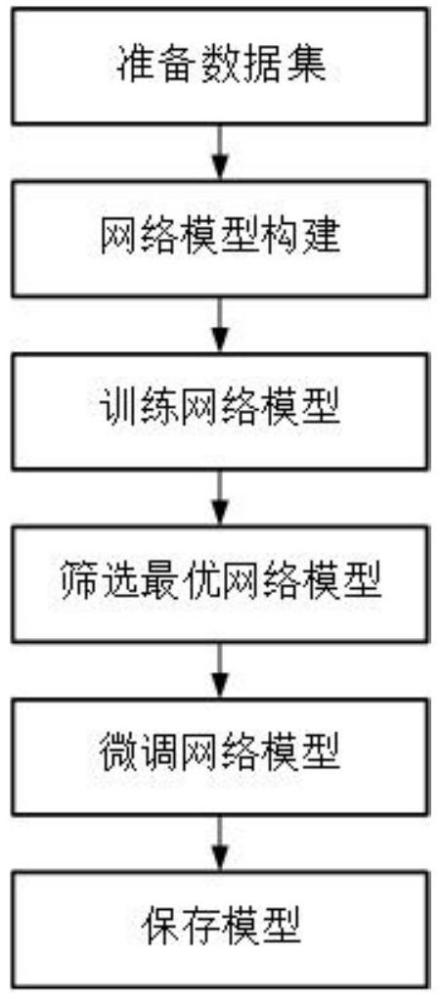
4、步骤1,准备数据集:准备第一多视图立体重建数据集和第二多视图立体重建数据集,分别将两个数据集划分为训练数据集和测试数据集;训练数据集用来训练网络模型,测试数据集用来评估模型训练效果;
5、步骤2,构建网络模型:网络由主干网络、基于大核注意力的自适应特征提取转换器模块、代价正则化模块以及深度估计模块构成。
6、步骤3,训练网络模型:将步骤1准备好的数据集输入到步骤2中构建好的网络模型中进行训练;通过最小化网络的输出与标签之间的损失,达到更好的深度预测结果;
7、步骤4,筛选最优网络模型;使用测试数据集作为输入,评估并筛选最优网络模型参数;
8、步骤5,微调网络模型;用第二多视图立体重建数据集对网络模型进行微调,使模型从光照可控的室内场景泛化到室外大规模场景。
9、步骤6,保存网络模型;将网络训练完成后,保存最优的网络参数,之后用将要三维重建的多视图场景图像输入到网络中就可以得到预测的深度图,通过深度滤波和融合操作,得到重建后的三维点云。
10、进一步地,第一多视图立体重建数据集为dtu数据集,获取每个场景多视角图像、深度图以及相对应的相机内外参数。
11、进一步地,所述主干网络为特征金字塔特征提取网络,用于提取输入参考图像和源图像的多尺度特征;
12、进一步地,所述基于大核注意力的自适应特征提取转换器模块包括自适应大核注意力块、混合前馈神经网络块、线性交叉注意力块和上采样模块;
13、所述自适应大核注意力块,利用不同膨胀系数的多尺度卷积核组合成大尺寸卷积核,使模型可以在不牺牲性能的前提下,有效减少计算代价,提高模型的计算效率。在此基础上,通过引入可变形卷积,使大尺寸卷积核可以自适应的学习到不同尺度的多视图目标,获得更大的感受野,使得模型能够更好地理解室外场景下的目标上下文信息,从而提高对复杂特征的提取能力。
14、所述混合前馈神经网络块,更好地聚合全局和多尺度的局部信息,并将层归一化的设计扩展到一般形式,促进了跳跃连接的优化,提升网络特征提取能力;
15、所述线性交叉注意力块,使网络能够在不同视角图像之间学习到图像间的特征关联,帮助模型更好地理解物体的空间结构,提高立体重建的准确性和稳定性。
16、进一步地,所述代价正则化模块,通过将三维卷积核替换成三维自适应大核注意力,可以在不增加模型参数和计算复杂度的情况下扩大感受野,使模型能够更好地捕捉场景中的全局信息,从而提高立体重建的准确性。
17、进一步地,所述深度估计模块利用最大概率深度估计,对每个像素位置,从概率体中选择具有最高概率值的深度值,将其作为深度估计图中该像素位置的深度值。
18、进一步地,在训练网络模型中预设阈值包括损失函数预设值、迭代次数预设值和优化学习率预设值。
19、进一步地,所述损失函数为焦点损失,以加强在模糊区域的单一热点监督。
20、进一步地,在训练网络模型过程中还包括通过评价指标评估算法重建结果的精确性和完整性。
21、进一步地,第二多视图立体重建数据集为blendedmvs数据集。
22、一种面向室外场景的多视图立体重建系统,所述系统包括:
23、图像获取模块,用于获取训练数据和测试数据;所述训练数据和测试数据包括多视角图像和与之对应的深度图像。
24、模型搭建模块,用于搭建本方法提出的网络模型并初始化模型权重;
25、数据集及模型装载模块,用于将输入图像和网络模型装载到硬件设备上,用于模型训练;所述的硬件设备指的是图像处理器;
26、模型训练模块,用于对训练数据中每个场景的多视角图像通过本方法构建的网络模型进行有监督的模型训练,得到最优的模型权重;
27、深度估计模块,用于将测试数据中每个场景的多视角图像通过装有最优模型权重的网络模型进行深度估计,得到每个场景的多视角深度图;
28、深度滤波和融合模块,用于将网络预测的多视角深度图通过深度滤波和融合操作后,得到每个场景的三维点云文件;
29、点云可视化模块,用于将三维点云文件经过meshlab软件平台解析处理,实现三维点云可视化;
30、存储介质,用于存储多视图立体重建系统。
31、有益效果
32、与现有技术相比,本发明提供了一种面向室外场景的高效多视图立体重建方法及系统,具备以下有益效果:
33、1.本发明设计一种新的多视图立体重建网络架构,构建了基于自适应大核注意力的多视图特征提取和概率体预测网络,解决现有多视图立体重建方法在面对室外大规模场景时训练推理时间长和计算代价大的问题,为室外大规模场景图像数据在多视图三维重建领域的应用以及三维重建技术的发展奠定重要基础。
34、2.本发明提出的自适应大核注意力模块既考虑了卷积和自注意力机制的全局和局部信息捕获能力,又避免了它们计算二次复杂度高、模型参数冗余和感受野大小固定的局限性。在不降低立体重建的精确度和完整度的情况下,它可以加速模型的训练和推断过程,提高模型的计算效率,特别是在处理大规模室外场景数据时能够显著提升效率。
35、3.本发明提出的混合前馈神经网络模块利用多尺度卷积核和层归一化扩展来捕获同一场景下的多视图目标不同尺度特征之间的关系,进一步增强了不同通道之间的信息交互,聚合不同深度的特征映射与目标之间的对应关系,从而获得更丰富的特征信息。
36、4.本发明提出的基于三维自适应大核注意力的代价体转换器可以提高模型的特征表达能力、信息交互能力和感受野覆盖范围,从而在面对复杂场景和输入变化时表现出更强的稳定性和泛化性。
37、5.本发明提出的多视图立体重建网络在dtu数据集和blendedmvs数据集中均表现出了良好的效果,在保证重建质量的同时,内存占用、计算量和推理时间分别降低了33%、32%和41%,有效降低了模型的训练和使用成本,提高重建效率。
- 还没有人留言评论。精彩留言会获得点赞!