一种基于大模型的数据存储方法及系统与流程
本发明涉及大规模数据管理,尤其涉及一种基于大模型的数据存储方法及系统。
背景技术:
1、大规模数据管理是信息技术领域的一个重要分支,专注于开发和维护处理、存储和分析巨量数据集的技术和方法。这个领域涵盖数据的采集、存储、管理、分析和可视化等多个方面。技术领域的关键挑战包括数据的高效存储、快速查询处理以及实时数据流的管理。大规模数据管理技术广泛应用于云计算、大数据分析、互联网技术和企业数据仓库等领域,是支持现代数据密集型应用的基础架构。
2、其中,大模型的数据存储方法是指使用大型机器学习模型来优化数据存储过程的技术。这种方法通过自动化的数据分类、智能压缩技术和高效的数据检索技术来提高存储系统的性能和数据访问速度。主要用途包括减少存储空间需求、提高数据处理速度和优化数据中心的能效。这些技术特别适用于处理大规模的、结构化或非结构化的数据集,如社交媒体数据、科学研究数据以及企业级应用数据。
3、现有大规模数据管理技术在处理大量、多样化的数据时,面临效率和成本的双重挑战。常规的数据存储方法未能有效区分数据的重要性和使用频率,导致高价值数据和低价值数据以相同方式存储,增加无效的存储空间占用和成本。现有技术在数据访问和检索过程中,未能实现数据位置的动态优化,导致数据访问延时,降低处理速度和效率。这种静态的存储和访问方式,在数据量激增的情况下,尤其表现出不足,难以适应快速变化的数据访问需求。例如,未能频繁更新的数据存储结构会导致在需求急剧变化时,数据处理系统响应不及时,影响整个数据中心的性能和服务质量。
技术实现思路
1、本发明的目的是解决现有技术中存在的缺点,而提出的一种基于大模型的数据存储方法及系统。
2、为了实现上述目的,本发明采用了如下技术方案,一种基于大模型的数据存储方法,包括以下步骤:
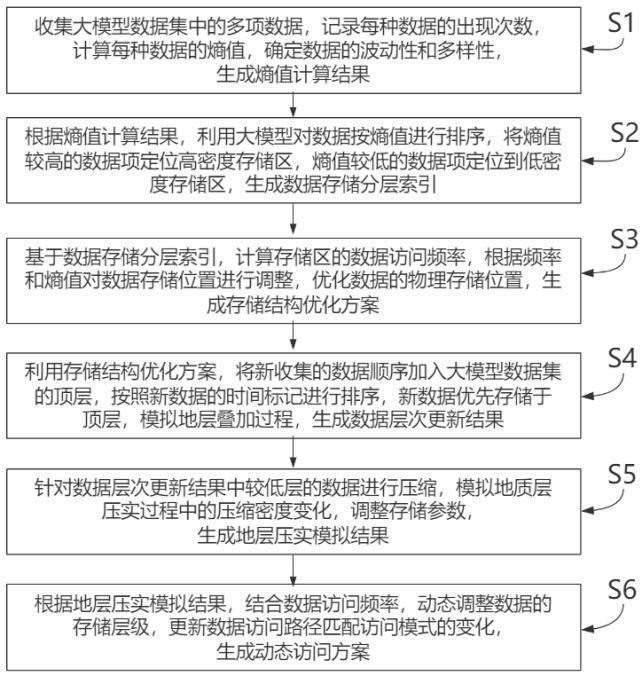
3、s1:收集大模型数据集中的多项数据,记录每种数据的出现次数,计算每种数据的熵值,确定数据的波动性和多样性,生成熵值计算结果;
4、s2:根据所述熵值计算结果,利用大模型对数据按熵值进行排序,将熵值较高的数据项定位高密度存储区,熵值较低的数据项定位到低密度存储区,生成数据存储分层索引;
5、s3:基于所述数据存储分层索引,计算存储区的数据访问频率,根据频率和熵值对数据存储位置进行调整,优化数据的物理存储位置,生成存储结构优化方案;
6、s4:利用所述存储结构优化方案,将新收集的数据顺序加入大模型数据集的顶层,按照新数据的时间标记进行排序,新数据优先存储于顶层,模拟地层叠加过程,生成数据层次更新结果;
7、s5:针对所述数据层次更新结果中较低层的数据进行压缩,模拟地质层压实过程中的压缩密度变化,调整存储参数,生成地层压实模拟结果;
8、s6:根据所述地层压实模拟结果,结合数据访问频率,动态调整数据的存储层级,更新数据访问路径匹配访问模式的变化,生成动态访问方案。
9、作为本发明的进一步方案,所述熵值计算结果包括数据项熵值的列表、数据项的标识符、对应的熵值和熵值大小的排名,所述数据存储分层索引包括数据项的排序索引、数据项对应的存储层级和每层的存储密度信息,所述存储结构优化方案包括存储位置的新配置、配置前后的访问频率比较和存储区域的容量变化,所述数据层次更新结果包括新增数据项的接入时间、存储层级和数据在层级中的顺序,所述地层压实模拟结果包括数据压缩前后的存储容量、压缩率和压缩后的访问效率,所述动态访问方案包括数据层级的调整记录、调整后的访问路径和路径优化前后的响应时间比较。
10、作为本发明的进一步方案,收集大模型数据集中的多项数据,记录每种数据的出现次数,计算每种数据的熵值,确定数据的波动性和多样性,生成熵值计算结果的步骤具体为:
11、s101:从大模型数据集中提取多种数据类型,统计每种数据的出现频次,采用键值对方式存储到字典中,得到数据类型频率表;
12、s102:基于所述数据类型频率表,计算每种数据类型的总出现次数占数据集总量的比例,得到数据概率分布表;
13、s103:采用所述数据概率分布表,对每种数据类型按照概率值计算熵值,使用概率乘以对数的负值累加求和的方式进行,得到熵值计算结果。
14、作为本发明的进一步方案,根据所述熵值计算结果,利用大模型对数据按熵值进行排序,将熵值较高的数据项定位高密度存储区,熵值较低的数据项定位到低密度存储区,生成数据存储分层索引的步骤具体为:
15、s201:基于所述熵值计算结果,对数据项进行筛选分类,识别高熵值与低熵值数据项,为每个数据项分配临时标识,标记为高优先级和低优先级,并对高熵值数据进行优先级排序,生成熵值分组表;
16、s202:采用所述熵值分组表,针对高熵值数据项,配置读写能力的存储区域,将数据迁移到高密度存储区,对低熵值数据项执行相反操作,分配到成本较低的低密度存储区,更新存储配置,生成数据分配记录;
17、s203:通过所述数据分配记录,同步存储区的访问权限和速度设置,查验每个数据项的存储位置与熵值匹配,配置数据访问路径,优化数据访问效率,生成数据存储分层索引。
18、作为本发明的进一步方案,基于所述数据存储分层索引,计算存储区的数据访问频率,根据频率和熵值对数据存储位置进行调整,优化数据的物理存储位置,生成存储结构优化方案的步骤具体为:
19、s301:基于所述数据存储分层索引,监测多个存储区的数据访问记录,计算数据项的访问频率,生成数据访问频率记录;
20、s302:采用所述数据访问频率记录,结合熵值分组表,对比访问频率和熵值,识别访问频率高且熵值低的数据项,访问频率低且熵值高的数据项,调整存储位置,生成待优化数据项列表;
21、s303:根据所述待优化数据项列表,重新分配数据存储位置,将访问频率高的数据移到高速存储区,访问频率低的数据移到低速存储区,优化数据的物理存储结构,生成存储结构优化方案。
22、作为本发明的进一步方案,利用所述存储结构优化方案,将新收集的数据顺序加入大模型数据集的顶层,按照新数据的时间标记进行排序,新数据优先存储于顶层,模拟地层叠加过程,生成数据层次更新结果的步骤具体为:
23、s401:根据所述存储结构优化方案,设定数据加入大模型数据集的策略,将新收集的数据加入数据集的顶层,记录新数据的时间标记,生成顶层数据加入记录;
24、s402:采用所述顶层数据加入记录,对新数据根据时间标记进行排序,查验新数据的优先访问,使用插入排序方法整合新旧数据,验证时间顺序性,生成新数据时间排序结果;
25、s403:基于所述新数据时间排序结果,模拟地层叠加过程,将新数据依时间顺序层叠存储于数据集顶层,查验数据结构的时效性和访问效率,生成数据层次更新结果。
26、作为本发明的进一步方案,针对所述数据层次更新结果中较低层的数据进行压缩,模拟地质层压实过程中的压缩密度变化,调整存储参数,生成地层压实模拟结果的步骤具体为:
27、s501:从所述数据层次更新结果中选取较低层的数据,评估压缩潜力,识别和标记需要压缩的数据,并调整存储密度,生成较低层数据选择结果;
28、s502:根据所述较低层数据选择结果,采用霍夫曼编码算法,对选定数据实施数据压缩,监控压缩过程中数据完整性和访问效率的变化,生成压缩参数设置结果;
29、s503:利用所述压缩参数设置结果,模拟地质层压实过程中的压缩密度变化,调整存储空间匹配压缩后的数据密度,优化数据存储效率和成本,生成地层压实模拟结果。
30、作为本发明的进一步方案,所述霍夫曼编码算法的公式如下:其中,为压缩效率值,代表数据块的权重,代表数据块的权重,代表数据块的原始长度,代表数据块的原始长度,代表和的绝对值差。
31、作为本发明的进一步方案,根据所述地层压实模拟结果,结合数据访问频率,动态调整数据的存储层级,更新数据访问路径匹配访问模式的变化,生成动态访问方案的步骤具体为:
32、s601:基于所述地层压实模拟结果,进行数据层次分析,识别存储密度低的数据,针对数据进行归档处理,并对高频访问数据进行优先级排序,得到数据分类表;
33、s602:采用所述数据分类表,对数据进行存储层级测量,针对测量结果调整低频数据到更低成本存储介质,并将高频数据迁移至快速访问层级,优化存储结构,生成存储层级调整记录;
34、s603:通过所述存储层级调整记录,对数据访问路径进行更新,验证新路径与实时访问频率的符合程度,配置访问规则和路径指向,优化访问效率,生成动态访问方案。
35、一种基于大模型的数据存储系统,所述基于大模型的数据存储系统用于执行上述基于大模型的数据存储方法,所述系统包括:
36、数据收集与分析模块进行数据集的抽取,识别每项数据并记录数据出现频次,计算数据的熵值评估多样性和变动性,得到熵值统计结果;
37、数据排序与分层模块基于所述熵值统计结果,对数据项进行熵值排序,高熵值数据定位到高密度存储区,低熵值数据定位到低密度存储区,构建层级索引结构;
38、存储调整模块利用所述层级索引结构,分析每个存储区的数据访问频率,根据数据的访问频率和熵值调整存储的物理位置,优化访问效率和存储成本,形成存储优化方案;
39、数据压实模拟模块根据所述存储优化方案,将新收集的数据添加到数据集的顶层,新数据根据时间标记排序并存储在顶层,模拟地层叠加过程,对老旧数据进行压缩,形成层次更新与压实结果;
40、动态存储管理模块基于所述层次更新与压实结果,结合数据访问频率的变化动态调整数据的存储层级,更新数据访问路径匹配访问模式的变化,生成动态访问方案。
41、与现有技术相比,本发明的优点和积极效果在于:
42、本发明中,通过收集数据集中的多样数据并计算出现次数及熵值,对数据的波动性和多样性进行评估,可显著提高数据存储效率和访问速度。按熵值对数据进行排序并分类存储,使得高熵值数据位于高密度存储区,而低熵值数据则存放在低密度区域,优化存储空间的利用率,减少不必要的存储成本。基于数据存储分层索引计算数据访问频率,并依此调整数据的物理存储位置,减少数据访问时间,提高数据处理速度。新增数据的层次式存储和按时间标记的排序模拟地层叠加,不仅优化存储结构,也方便新数据的快速定位和访问。数据压缩和存储参数的调整模拟地质层压实过程,有效管理存储容量,增强数据中心的能效。动态调整数据存储层级和更新访问路径以匹配访问模式的变化,确保存储系统的灵活性和适应性,增强对复杂数据环境的响应能力。
- 还没有人留言评论。精彩留言会获得点赞!