一种基于AI智慧视频分析方法及系统与流程
本发明涉及视频分析,具体是一种基于ai智慧视频分析方法及系统。
背景技术:
1、视频(video)泛指将一系列静态影像以电信号的方式加以捕捉、记录、处理、储存、传送与重现的各种技术。连续的图像变化每秒超过24帧(frame)画面以上时,根据视觉暂留原理,人眼无法辨别单幅的静态画面;看上去是平滑连续的视觉效果,这样连续的画面被称为视频。
2、现有的已普及的计算机设备的性能很高,这使得视频逐渐成为了主流媒体数据,但量,由于视频内容很大,阅读者很难提前初步了解视频内容,只能通过简介,对于一些没有简介或简介很简短的视频,阅读者只能自行查阅,在需要进行视频筛选的场合,筛选过程很困难,如果能够提供一种视频内容分析方案,使得阅读者能够提前了解视频内容,那么可以极大地简化筛选难度,提高筛选效率。
技术实现思路
1、本发明的目的在于提供一种基于ai智慧视频分析方法及系统,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、一种基于ai智慧视频分析方法,所述方法包括:
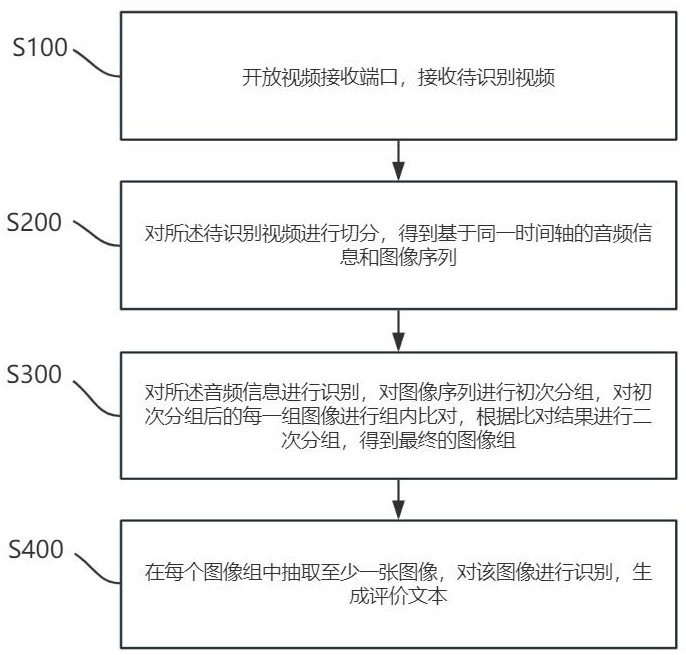
4、开放视频接收端口,接收待识别视频;
5、对所述待识别视频进行切分,得到基于同一时间轴的音频信息和图像序列;
6、对所述音频信息进行识别,对图像序列进行初次分组,对初次分组后的每一组图像进行组内比对,根据比对结果进行二次分组,得到最终的图像组;所述图像组是图像的集合,图像组中含有基于时间轴生成的时间标签;
7、在每个图像组中抽取至少一张图像,对该图像进行识别,生成评价文本;
8、其中,对图像进行识别的过程包括固定识别方案和动态识别方案,所述动态识别方案是基于神经网络模型的识别方案。
9、作为本发明进一步的方案:所述对所述待识别视频进行切分,得到基于同一时间轴的音频信息和图像序列的步骤包括:
10、获取待识别视频的时间跨度,创建时间轴;
11、基于时间轴在待识别视频的音频轨道上提取音频信息;
12、获取视频的帧率,基于帧率在时间轴上选取图像点,在待识别视频的图像轨道上读取图像,建立与图像点的对应关系;
13、基于图像点的排序顺序统计对应的图像,得到图像序列。
14、作为本发明进一步的方案:所述对所述音频信息进行识别,对图像序列进行初次分组,对初次分组后的每一组图像进行组内比对,根据比对结果进行二次分组,得到最终的图像组的步骤包括:
15、根据时间顺序读取音频信息的幅值,基于所述幅值对音频信息进行分段;
16、读取每一段音频信息对应的所有图像,保留图像顺序,得到初次分组结果;
17、在初次分组后的每一组图像中依次图像,将图像与相邻的预设数量的图像进行比对,确定图像的普遍度;
18、根据所述普遍度对同一组图像进行二次分组,得到最终的图像组。
19、作为本发明进一步的方案:对音频信息进行分段的过程为:
20、根据时间顺序读取音频幅值,根据音频幅值生成分段点;
21、;表示第个分段点,表示的前一个分段点,表示时间差,,表示时长范围内的幅值标准差,为预设的阈值;表示符合条件的取值的最大值;
22、图像的普遍度的确定过程为:
23、;表示图像的普遍度,表示预设的图像选取半径,其值为正值;表示在图像选取半径范围内的第个图像与当前图像的相似度,相似度的取值为零到一;为预设的调节常数。
24、作为本发明进一步的方案:所述在每个图像组中抽取至少一张图像,对该图像进行识别,生成评价文本的步骤包括:
25、对于每个图像组,读取每张图像的普遍度,根据所述普遍度抽取至少一张图像;
26、对抽取到的图像进行主体识别,得到主体词组;
27、根据图像序列的图像顺序排列每张图像的主体词组,基于统计语言模型将主体词组转换为语句;
28、统计所有语句,得到评价文本。
29、作为本发明进一步的方案:所述在每个图像组中抽取至少一张图像,对该图像进行识别,生成评价文本的步骤还包括:
30、预先构建图像至描述语句的样本集,基于所述样本集训练神经网络模型;
31、在图像进行识别时,将图像及其对应的语句作为新的样本,更新样本集;
32、根据新的样本实时判断神经网络模型的误差率,根据所述误差率调节固定识别方案的应用频率;
33、定时将新的样本向验证端发送,接收验证端反馈的样本修正指令。
34、本发明技术方案还提供了一种基于ai智慧视频分析系统,所述系统包括:
35、视频接收模块,用于开放视频接收端口,接收待识别视频;
36、成分提取模块,用于对所述待识别视频进行切分,得到基于同一时间轴的音频信息和图像序列;
37、视频分组模块,用于对所述音频信息进行识别,对图像序列进行初次分组,对初次分组后的每一组图像进行组内比对,根据比对结果进行二次分组,得到最终的图像组;所述图像组是图像的集合,图像组中含有基于时间轴生成的时间标签;
38、图像识别模块,用于在每个图像组中抽取至少一张图像,对该图像进行识别,生成评价文本;
39、其中,对图像进行识别的过程包括固定识别方案和动态识别方案,所述动态识别方案是基于神经网络模型的识别方案。
40、作为本发明进一步的方案:所述成分提取模块包括:
41、时间轴创建单元,用于获取待识别视频的时间跨度,创建时间轴;
42、音频信息提取单元,用于基于时间轴在待识别视频的音频轨道上提取音频信息;
43、图像插入单元,用于获取视频的帧率,基于帧率在时间轴上选取图像点,在待识别视频的图像轨道上读取图像,建立与图像点的对应关系;
44、图像排列单元,用于基于图像点的排序顺序统计对应的图像,得到图像序列。
45、作为本发明进一步的方案:所述视频分组模块包括:
46、音频信息分析单元,用于根据时间顺序读取音频信息的幅值,基于所述幅值对音频信息进行分段;
47、图像读取单元,用于读取每一段音频信息对应的所有图像,保留图像顺序,得到初次分组结果;
48、普遍度计算单元,用于在初次分组后的每一组图像中依次图像,将图像与相邻的预设数量的图像进行比对,确定图像的普遍度;
49、二次分组单元,用于根据所述普遍度对同一组图像进行二次分组,得到最终的图像组。
50、作为本发明进一步的方案:所述图像识别模块包括:
51、抽取执行单元,用于对于每个图像组,读取每张图像的普遍度,根据所述普遍度抽取至少一张图像;
52、主体识别单元,用于对抽取到的图像进行主体识别,得到主体词组;
53、语句生成单元,用于根据图像序列的图像顺序排列每张图像的主体词组,基于统计语言模型将主体词组转换为语句;
54、语句统计单元,用于统计所有语句,得到评价文本。
55、与现有技术相比,本发明的有益效果是:本发明在视频文件中抽取部分图像,借助基于ai的固定识别方案和基于本地模型的动态识别方案对图像进行分析,在生成分析内容的基础上,训练了本地模型,最终得到一个效率极高的本地模型,在接收到分析请求时,可以极快地将视频转换为文本,便于用户快速了解视频内容。
- 还没有人留言评论。精彩留言会获得点赞!