一种运价数据更新的方法及系统与流程
本发明涉及国内运价数据构建领域,尤其涉及一种运价数据更新的方法及系统。
背景技术:
1、当前国内运价计算软件,使用mmap内存映射的方式构建数据,将rawdata源数据(运价源数据)构建成为dff数据(运价数据),将其作为计算引擎的数据源,供计算引擎进行业务逻辑使用。通常构建数据使用intake服务器、updater服务器和pricing node服务器自动化完成,其中,intake服务器用于接收rawdata源数据(运价源数据),并通过多播的方式将rawdata源数据(运价源数据)推送到updater服务器;updater服务器使用全量的rawdata源数据(运价源数据)做全量的数据构建,每次有rawdata源数据(运价源数据)更新时,updater服务器在全量数据的基础上,使用增量的rawdata源数据(运价源数据)做增量数据构建;构建完成的dff数据(运价数据)包含三种类型:recode类型数据、segment类型数据、index类型数据;数据构建成功后,updater服务器使用多播的方式将dff数据(运价数据)推送到pricing node服务器;当pricing node服务器接收到updater服务器推送的增量dff数据(运价数据)时,le(国内运价计算引擎)需要重新加载全部的dff数据(运价数据),由于数据文件大,增加了每次数据更新的时间。
2、为了缩短每次数据更新时间,提高更新效率,通常是通过将构建完成的dff数据(运价数据)包中的recode类型数据、segment类型数据和index类型数据进行碎片化处理,但在目前国内运价系统中,只能将recode类型数据和segment类型数据进行碎片化处理,而index类型的数据是一种使用stl map保存key-value形式的数据,其中stl map是c++标准中提供的库,使得stl map数据的数据结构无法控制,进而无法对index类型的数据进行碎片化,使得le(国内运价计算引擎)在加载更新整个index类型的数据文件时,其数据更新的性能和效率并未得到有效的改善。
技术实现思路
1、本发明针对现有技术存在的不足,本发明提供了一种运价数据更新的方法及系统,利用hash桶数据结构代替stl map的数据结构,对hash桶数据结构实行全面控制,进而对index数据类型进行碎片处理来提高数据更新的效率。本发明具体实施方案如下:
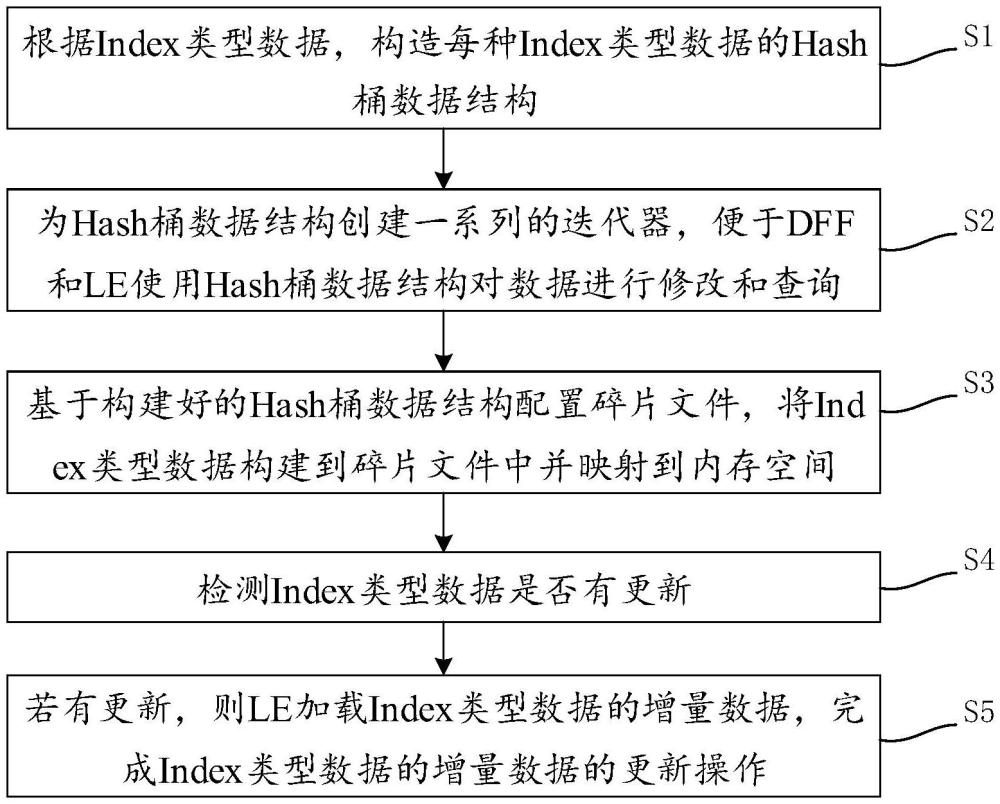
2、一方面,本发明提供了一种运价数据更新的方法,所述方法包括如下步骤:
3、步骤s1:根据index类型数据,构造每种index类型数据的hash桶数据结构;
4、进一步的,在步骤s1中,还包括:
5、步骤s101:根据每个数据表中每个类型键的数据的数量确定hash桶的大小,并创建相同数据的数据节点来存储数据,所述数据节点包括:键、next指针、数据集;
6、步骤s102:通过hash函数将键转换为hash值,然后对hash桶的数量取模来得到键的索引值,将数据节点存储到hash桶的索引中;
7、步骤s103:数据对象中保存record类型数据的地址,当数据集被推入数据时,若数据集已经存满,内存构造器动态扩展数据集的大小。
8、进一步的,在步骤101中,所述键用于查询时候与查询键的比对,所述next指针指向下一个数据节点,所述数据集是一个可变长数组用于存储键对应的数据。
9、进一步的,在步骤102中,还包括:当hash值产出冲突的时候,将冲突的数据节点以单链表的形式存储到hash桶的一个索引中。
10、步骤s2:为hash桶数据结构创建一系列的迭代器,便于dff和le使用hash桶数据结构对数据进行修改和查询;
11、进一步的,所述创建一系列的迭代器包括普通迭代器、常量迭代器、逆向迭代器和常量逆向迭代器,其中,普通迭代器和逆向迭代器用于修改数据,常量迭代器和常量逆向迭代器用于查询数据。
12、步骤s3:基于构建好的hash桶数据结构配置碎片文件,将index类型数据构建到碎片文件中并映射到内存空间;
13、进一步的,在步骤s3中,还包括如下步骤:
14、步骤s301:根据软件的配置文件配置的碎片大小,创建index类型数据的碎片文件,使用内存构造器为每个index类型数据的hash桶数据结构构造连续的内存空间;
15、步骤s302:通过mmap组件将每个index类型数据所有碎片文件映射到构建好的内存空间;
16、步骤s303:读取rawdata数据,把数据添加到对应的index类型的hash桶数据结构中,通过迭代器组件判断rawdata数据中每条数据在index碎片文件中是否存在;
17、步骤s304:若存在,将新数据存入已存在的数据集中,若不存在,在最后一个数据碎片文件的数据结尾追加新数据,当最后一个数据碎片文件已经存满的时候,动态创建新的数据碎片文件,并将新数据存入新的数据碎片文件中。
18、步骤s4:检测index类型数据是否有更新;
19、进一步的,所述检测index类型数据是否有更新,具体包括如下步骤:
20、步骤s401:当数据更新时,记录每个数据表的每条数据在hash桶的索引信息,并将更新信息和数据批次号持久化到数据信息文件中;
21、步骤s402:在增量更新完成后,根据数据信息文件中的批次号和更新信息,确定数据内容发生更新的数据碎片文件,将其按照数据批次号记录到changefile文件中。
22、步骤s5:若有更新,则le加载index类型数据的增量数据,完成index类型数据的增量数据的更新操作。
23、进一步的,所述增量数据是index类型数据中更新的index类型数据;所述le加载index类型数据的增量数据,完成index类型数据的增量数据的更新操作,具体为:le在接收到请求后会重新加载最新的dff数据,根据最新dff数据中changefile文件记录的批次号,确定这个批次数据更新的index类型数据的增量数据碎片文件,并将碎片文件映射到内存空间。
24、一方面,本发明还提供了一种运价数据更新的系统,所述系统包括构建数据组件、迭代器组件、hash桶组件、mmap组件、内存构造器组件、检测增量数据组件和增量数据加载组件,其中:
25、所述构建数据组件属于总控制组件,用于将rawdata数据构建成dff数据并对index类型数据碎片化处理;
26、所述hash桶组件用于负责数据的存储和访问;在hash桶组件中,通过映射到hash桶数据结构中的索引来存储和访问数据,使用一个定长数组来表示桶,每个桶可以存储一个或者多个数据节点,使用hash函数来计算键的hash值,然后对桶的数量取模来得到键的索引值;
27、进一步的,所述hash桶组件还包含数据节点、hash函数和链表,其中:
28、所述数据节点用于保存数据信息,包括:键、数据集和指向下一个数据节点的next指针,所述数据集是一个可变的长数组,用于替换stl vector数据结构存储键对应的数据;
29、所述hash函数用于计算键的hash值;
30、所述链表用于解决hash冲突。
31、进一步的,所述的hash冲突是指:不同的键被hash函数映射到相同的hash值,而产生hash冲突;所述链表用于解决hash冲突,具体为:将相同hash值的键放在一个桶中存储,使用链表来存储多个数据节点;因对index类型数据文件进行碎片化的时候stl vector的数据结构无法确定,所以使用数据集带代替stl vector存储键对应的数据。
32、所述迭代器组件用于负责对hash桶组件和数据集中的数据进行遍历、修改、增加等操作;
33、进一步的,所述迭代器包括普通迭代器、常量迭代器、逆向迭代器和常量逆向迭代器,其中:所述普通迭代器和逆向迭代器用于修改数据,所述常量迭代器和常量逆向迭代器用于查询数据。
34、所述内存构造器组件用于负责构建数据需要的内存;
35、所述mmap组件用于负责将数据文件映射到内存空间;
36、所述增量数据加载组件用于负责将构建完成的dff数据映射到内存空间;
37、所述检测增量数据组件用于检测index类型数据是否有更新,并负责计算增量数据位于哪个数据碎片文件内。
38、与现有技术相比,本发明具有如下优点:
39、1、本发明使用hash桶数据结构代替了stl map数据结构和stl vector数据结构,通过对hash桶数据结构的控制,可以对index数据文件进行碎片化处理,在le加载增量数据时,只需加载index碎片数据,就能完成数据的更新,不用对index类型的数据文件进行整个修改和加载,通过这种方式提高了数据增量更新的速度和效率。
40、2、hash桶数据结构使用键-值的形式存储数据,更加有利于内存的管理,在数据查询时,利用hash函数能快速查到对应的键,提升了数据查询的速度,同时在对外提供查询、修改时,hash桶数据结构不会发生变化,不影响le对dff数据的使用。
41、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所指出的结构来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!