一种基于图像文本对的图像目标计数方法及装置
本发明涉及图像处理,尤其是指一种基于图像文本对的图像目标计数方法及装置。
背景技术:
1、最近,开集模型引起了物体计数研究人员的关注,因为这些模型通过预测新的和未见过的类别,具有良好的泛化性能。
2、零点学习被引入到基于密度图的计数方法中,以处理图像-文本数据。例如,对比语言-图像预训练(contrastive language-image pre-training,clip)是一种嵌入式零点学习方法,已被应用于零点对象计数法中,如crowdclip和clip-count。这两种方法都是通过clip提取图像-文本数据的多模态信息,能够用于处理具有多类目标的图像-文本数据。
3、但是,由于现有方法都是基于密度图的计数方法,忽略了图像中目标的关键位置信息,难以有效利用图像的局部特征,导致目标计数不准确。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中无法利用图像局部信息,导致目标计数不准确的问题。
2、为解决上述技术问题,本发明提供了一种基于图像文本对的图像目标计数方法,包括:
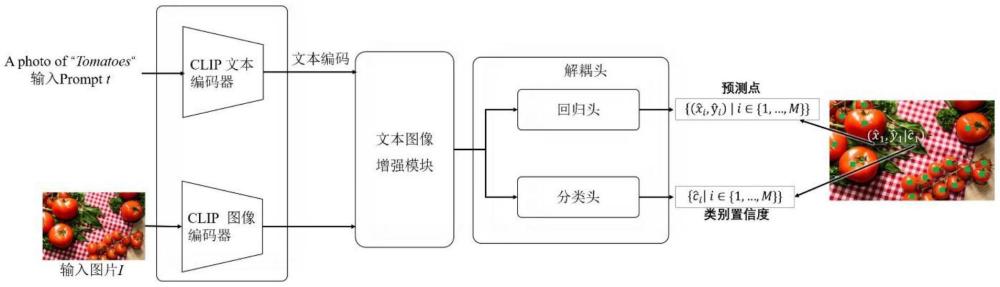
3、将原始图像输入图像编码器,输出图像编码;将原始图像中待计数的目标类别的文本输入文本编码器,输出文本编码;
4、将文本编码和图像编码输入至文本图像增强模块,输出目标融合特征,包括:
5、将文本编码和图像编码输入至文本图像增强模块的第一特征增强模块,得到第一增强特征;
6、将第一增强特征经过卷积层和上采样层后,输入至文本图像增强模块的第二特征增强模块,得到第二增强特征;
7、将第一增强特征和第二增强特征输入至文本图像增强模块的特征融合模块,得到目标融合特征;
8、其中,每个特征增强模块包括依次连接的局部增强多头自注意力机制、交叉注意力机制和多层感知机;所述局部增强多头自注意力机制为三分支结构,包括通道注意力分支、多头自注意力分支和空间注意力分支;
9、将目标融合特征输入至解耦头,解耦头的回归头输出个体的预测点的坐标,解耦头的分类头输出每个预测点的类别置信度;根据预测点的类别置信度判断预测点是否属于目标类别,若是,则输出该预测点的坐标和类别置信度,进而得到属于目标类别的个体的总数。
10、优选地,所述文本编码器包括依次连接的文本预处理模块和文本编码模块;所述文本预处理模块用于降低输入文本的噪声,输出预处理文本;所述文本编码模块用于接收预处理文本,输出文本编码;
11、所述图像编码器包括图像预处理模块和图像编码模块;所述图像预处理模块用于对输入图像缩放、随机翻转和归一化,输出预处理图像;所述图像编码模块用于接收预处理图像,输出图像编码。
12、优选地,所述文本编码模块采用bert模型。
13、优选地,所述图像编码模块采用vit模型。
14、优选地,所述将文本编码和图像编码输入至文本图像增强模块,输出目标融合特征,包括:
15、将图像编码作为第一局部增强多头自注意力机制的输入特征,得到第一图像增强特征;将文本编码和第一图像增强特征输入至第一交叉注意力机制,其中文本编码作为查询,第一图像增强特征作为键和值,输出第一文本图像融合特征;将第一文本图像融合特征输入至第一多层感知机,得到第一增强特征;
16、将第一增强特征经过卷积层和上采样层后,输入至第二特征增强模块的第一局部增强多头自注意力机制,得到第二图像增强特征;将文本编码和第二图像增强特征输入至第二交叉注意力机制,其中文本编码作为查询,第二图像增强特征作为键和值,输出第二文本图像融合特征;将第二文本图像融合特征输入至第二多层感知机,得到第二增强特征;
17、将第一增强特征和第二增强特征输入至特征融合模块,第一增强特征和第二增强特征相加后依次经过两个上采样子模块,得到目标融合特征。
18、优选地,局部增强多头自注意力机制的输入特征分别经过通道注意力分支、多头自注意力分支和空间注意力分支后,得到通道增强特征、自注意力增强特征和空间增强特征;将通道增强特征、自注意力增强特征和空间增强特征相加后得到局部增强多头自注意力机制的输出特征。
19、优选地,局部增强多头自注意力机制的输入特征经过通道注意力分支,得到通道增强特征,包括:
20、通道注意力分别在输入特征的高度和宽度维度上进行最大池化和平均池化,得到两个特征权值;将所述两个特征权值相加,再与输入特征进行点乘,得到通道增强特征。
21、优选地,局部增强多头自注意力机制的输入特征经过多头自注意力分支,得到自注意力增强特征,包括:
22、局部增强多头自注意力机制的输入特征的大小为b,c,h,w,其中b表示批次大小,c表示通道,h表示高度,w宽度;
23、首先将局部增强多头自注意力机制的输入特征转换为大小为b,c,h×w的三维序列,再将c和h×w两个维度交换,转换为大小为b,h×w,c的三维序列,作为多头自注意力机制的输入特征;
24、多头自注意力机制的输入特征经过多头自注意力机制后,得到大小为b,h×w,c的输出特征;
25、将该输出特征的h×w与c两个维度交换,再次转换为大小为b,h×w,c的三维序列;最后将该三维序列转为大小为b,c,h,w的特征图,得到自注意力增强特征。
26、优选地,局部增强多头自注意力机制的输入特征经过空间注意力分支,得到空间增强特征,包括:
27、空间注意力分别在输入特征的通道维度上取最大值和平均值,得到两个特征权值;将所述两个特征权值相加,再与输入特征进行点乘,得到空间增强特征。
28、本发明还提供了一种基于图像文本对的图像目标计数装置,包括:
29、编码模块,用于将原始图像输入图像编码器,输出图像编码;将原始图像中待计数的目标类别的文本输入文本编码器,输出文本编码;
30、特征融合模块,用于将文本编码和图像编码输入至文本图像增强模块,输出目标融合特征,包括:
31、将文本编码和图像编码输入至文本图像增强模块的第一特征增强模块,得到第一增强特征;
32、将第一增强特征经过卷积层和上采样层后,输入至文本图像增强模块的第二特征增强模块,得到第二增强特征;
33、将第一增强特征和第二增强特征输入至文本图像增强模块的特征融合模块,得到目标融合特征;
34、其中,每个特征增强模块包括依次连接的局部增强多头自注意力机制、交叉注意力机制和多层感知机;所述局部增强多头自注意力机制为三分支结构,包括通道注意力分支、多头自注意力分支和空间注意力分支;
35、预测模块,用于将目标融合特征输入至解耦头,解耦头的回归头输出个体的预测点的坐标,解耦头的分类头输出每个预测点的类别置信度;根据预测点的类别置信度判断预测点是否属于目标类别,若是,则输出该预测点的坐标和类别置信度,进而得到属于目标类别的个体的总数。
36、本发明的上述技术方案相比现有技术具有以下有益效果:
37、本发明所述的一种基于图像文本对的图像目标计数方法,构建目标计数模型,利用文本图像增强模块对输入文本和输入图像进行特征增强和特征融合,并在文本图像增强模块中引入局部增强多头自注意力机制,在现有的多头自注意力机制基础上,基于卷积善于捕捉局部特征的优势,增加了通道注意力和空间注意力两个分支,通过在不同空间和通道位置计算注意力权重,保留了图像的局部细节信息,增强了模型对局部信息的感知能力,进一步结合多头自注意力机制提取的全局信息,有效提高了模型对目标的识别能力,提高了对目标计数的准确性。
- 还没有人留言评论。精彩留言会获得点赞!