一种基于相似度和Wasserstein距离的变压器谱图基线异常识别方法与流程
本发明属于变压器领域,特别涉及一种基于相似度和wasserstein距离的变压器谱图基线异常识别方法。
背景技术:
1、在电力系统中,变压器作为关键设备之一,其运行状态直接影响到整个电网的安全与稳定。变压器油色谱分析作为一种重要的故障诊断方法,通过对变压器油中溶解气体的成分和含量进行分析,可以间接反映变压器的内部故障情况。然而,在实际应用中,色谱图常常受到各种因素的影响,如设备精度、操作条件等,导致基线出现漂移、鬼峰或杂峰等异常现象,这些异常不仅增加了故障诊断的难度,还可能误导诊断结果。
2、传统的色谱图异常识别方法多依赖于人工经验判断,存在主观性强、效率低下的问题。随着计算机技术和机器学习的发展,一些基于算法的自动异常识别方法逐渐兴起。这些方法通过提取色谱图的特征参数,并与标准谱图进行对比分析,以实现异常的自动识别。然而,现有方法往往侧重于整体相似度的评估,忽略了基线部分的微小变化,导致对基线漂移等异常的识别能力不足。
3、目前,与本发明最相近似的现有实现方案主要集中在基于相似度计算的色谱图异常识别方法上。这些方法通常利用余弦相似度、皮尔逊相关系数等指标计算待测谱图与标准谱图之间的相似度,通过设定阈值来判断是否存在异常。
4、然而,这些方法存在以下不足:一是相似度计算易受整体趋势影响,难以准确捕捉基线部分的微小变化;二是缺乏对基线漂移等特定异常类型的针对性检测手段;三是识别结果受阈值设定影响较大,鲁棒性较差。
技术实现思路
1、本发明所要解决的技术问题是提供一种基于相似度和wasserstein距离的变压器谱图基线异常识别方法,通过精确计算变压器油色谱谱图与标准谱图之间的相似度以及基线部分的wasserstein距离,实现对谱图中基线漂移、鬼峰或杂峰等异常的自动识别。该方法结合了全局相似度评估与局部基线差异检测的优势,提高了异常识别的准确性和鲁棒性,为变压器故障诊断提供了一种高效、可靠的技术手段。
2、为解决上述技术问题,本发明所采用的技术方案是:
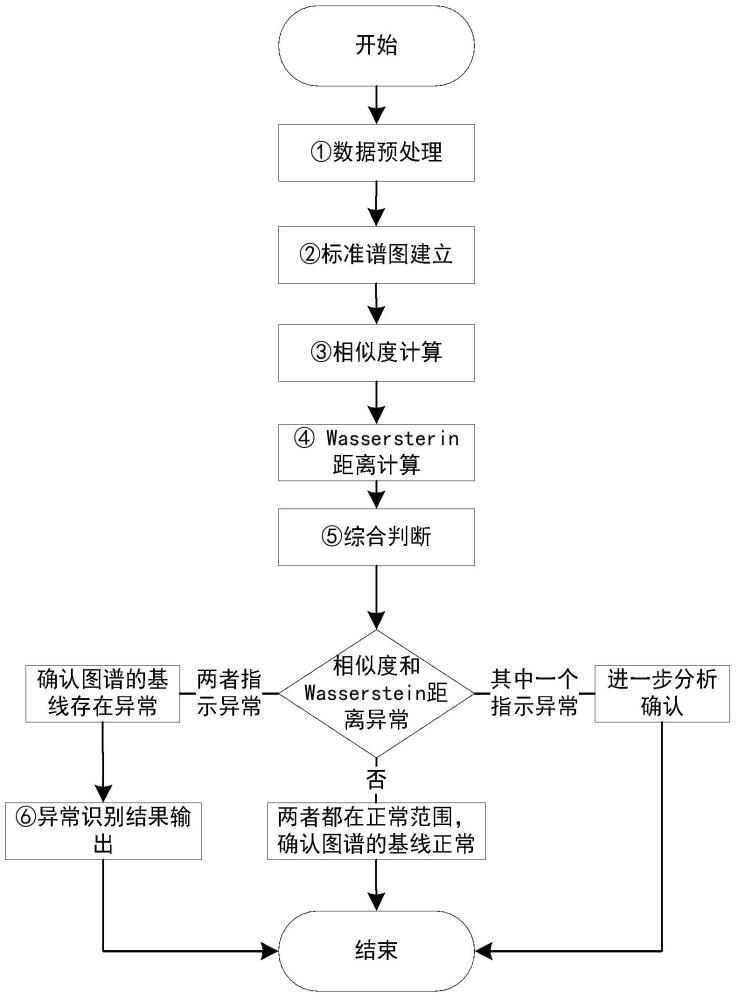
3、一种基于相似度和wasserstein距离的变压器谱图基线异常识别方法,步骤 1、采用滤波器去除色谱图的高频噪声,通过基线校正算法去除基线漂移,进行包括数据清理、数据集成、数据变换和数据归约在内的操作确保数据可比性和质量;
4、步骤 2、从数据源选取候选参考图谱,进行包括去噪、平滑在内的预处理,筛选并验证图谱,整理成标准图谱库并维护更新;
5、步骤 3、用皮尔逊相关系数方法计算待测谱图与标准谱图整体相似度,设定阈值判断异常;
6、步骤 4、计算待测谱图基线与标准基线模板之间的 wasserstein 距离,设定阈值判断基线异常;
7、步骤 5、结合相似度和 wasserstein 距离结果判断谱图基线是否异常;
8、步骤 6、识别并输出异常结果,异常结果包括相似度超阈值、wasserstein 距离值超阈值及异常类型在内的结果。
9、优选地,步骤1中,所述的数据清理包括:
10、(1)填充缺失值:利用预测模型进行填充。
11、(2)去除高频噪声:利用滤波器去除高频噪声。
12、(3)处理离群点:利用设置阈值或基于统计分布的方法进行判断和处理。
13、(4)确保数据准确性和一致性:利用纠正错误和不一致性的方式确保。
14、所述的数据集成为:利用数据集成过程将多个数据源中的数据合并成统一数据集,同时解决数据冗余和冲突问题,确保数据完整性和一致性。
15、所述的数据变换包括:
16、(1)缩放数据:利用按比例缩放的方式将数据缩放至特定区间。
17、(2)调整分布:利用调整数据分布的方式将数据分布调整为标准正态分布,实现均值为 0、标准差为 1。
18、(3)转换数据:利用将连续数据转换为离散类别的方式便于数据分析或挖掘算法。
19、所述的数据归约为:减少数据量,利用降维、聚合等方法在保持数据原始信息的前提下减少数据量,提高数据处理和分析效率。
20、优选地,步骤2的子步骤为:
21、子步骤 2.1:从现有的数据库中选取具有代表性的图谱作为候选参考图谱,确保其来源可靠且经过严格审核验证;
22、子步骤 2.2:对候选参考图谱进行去噪、平滑预处理操作,提高图谱清晰度和准确性;
23、子步骤 2.3:对图谱进行标准化处理,确保不同图谱在同一尺度上比较,消除仪器和操作因素引起的差异;
24、子步骤 2.4:分离基线部分和峰值部分,便于后续分析和比较;
25、子步骤 2.5:根据标准对预处理后的图谱进行筛选,排除异常或不符合要求的图谱;
26、子步骤 2.6:对筛选出的图谱进行验证,通过与已知样本的图谱进行比较、重复测量方式确保其代表性和准确性;
27、子步骤 2.7:将经过筛选和验证的图谱整理成标准图谱库,并进行编号、分类和存储;
28、子步骤 2.8:确保标准图谱库的更新和维护,及时添加新的标准图谱并删除过时或不再使用的图谱。
29、优选地,步骤3的子步骤为:
30、子步骤 3.1:使用皮尔逊相关系数方法计算待测谱图与标准谱图之间的整体相似度;
31、子步骤 3.2:设定相似度阈值;
32、子步骤 3.3:若计算得到的相似度低于阈值,则视为可能异常。
33、优选地,步骤 3.3方法如下:
34、使用皮尔逊相关系数方法计算待测谱图与标准谱图之间的整体相似度;设定相似度阈值,低于阈值则视为可能异常;
35、皮尔逊相关系数,是衡量两个变量x和y线性相关程度的指标;皮尔逊相关系数r的值域为-1到1之间,其中:
36、当r=1时,表示x和y完全正相关,即一个变量随着另一个变量的增加而线性增加,或者随着另一个变量的减少而线性减少;
37、当r=-1时,表示x和y完全负相关,即一个变量随着另一个变量的增加而线性减少,或者随着另一个变量的减少而线性增加;
38、当r=0时,表示x和y之间没有线性相关关系;
39、皮尔逊相关系数的计算公式为:
40、;
41、其中,和分别是变量x和y的第i个观测值,和分别是x和y的均值,n是观测值的数量。
42、优选地,步骤4的子步骤为:
43、子步骤 4.1:针对基线部分,获取待测谱图的基线数据和标准基线模板的数据,这些数据为一维数组,表示不同波长或频率下的基线强度。子步骤 4.2:基于对基线漂移容忍度的理解以及大量实验数据得到的统计信息,设定 wasserstein 距离阈值。子步骤 4.3:计算待测谱图基线与标准基线模板之间的 wasserstein 距离:在 python 中可使用scipy 库中的 scipy.stats.wasserstein_distance 函数直接计算两个一维数组之间的wasserstein 距离。子步骤 4.4:若计算得到的 wasserstein 距离超过阈值,则视为基线异常。同时,wasserstein 距离能够捕捉分布间的微小差异,适合用于基线漂移的检测。
44、优选地, 子步骤 4.3的计算方法为:
45、对于一维概率分布p和q,定义在实数集r上,其p-阶wasserstein距离定义为:
46、(p、q)=;
47、其中,π(p,q)是p和q所有可能的联合分布的集合,联合分布的边际分布分别是p和q;表示从x到y的距离的p次方;是联合分布y在点(x,y)上的概率密度;p≥1是一个实数,表示考虑的是p-阶距离;
48、根据实际应用得到两组数据:一组是待测谱图的基线数据,另一组是标准基线模板的数据;这些数据是一维数组,表示在不同波长或频率下的基线强度;在python中,scipy库中的scipy.stats.wasserstein_distance函数可以直接用来计算两个一维数组之间的wasserstein距离。
49、优选地,子步骤 4.4中,设定阈值并判断基线是否异常,需要根据应用的具体需求设定一个wasserstein距离的阈值;这个阈值应该基于对基线漂移容忍度的理解,以及通过大量实验数据得到的统计信息。
50、优选地,步骤5中,结合相似度和wasserstein距离的结果进行综合判断;若两者均指示异常,则确认谱图存在基线异常;如果相似度低于其阈值,并且wasserstein距离高于其阈值,则指示谱图存在基线异常;如果只有其中一个指标指示异常,而另一个指标在正常范围内,需要进一步的分析或确认;如果两者都在正常范围内,则认为谱图的基线是正常的。
51、优选地,步骤6中,异常类型包括基线漂移、鬼峰、杂峰;通过开发图形用户界面,方便用户上传色谱图文件、查看异常识别结果并进行交互操作;提供异常报警功能,当检测到基线异常时及时通知用户。
52、本发明可达到以下有益效果:
53、1、通过结合皮尔逊相关系数和wasserstein距离两种方法,本发明能够从整体和局部两个维度全面评估待测谱图与标准谱图的相似性。皮尔逊相关系数用于评估整体谱图的相似性,而wasserstein距离则特别关注基线部分的微小变化。这种双重检测机制显著提高了异常检测的准确性和可靠性。
54、2、wasserstein距离能够捕捉基线部分的细微变化,特别适合检测基线漂移等微小异常。通过设定合适的阈值,本发明能够及时发现基线漂移、鬼峰或杂峰等基线异常,从而避免因基线问题导致的误判或漏检。
55、3、本发明采用了多种数据预处理技术,如高斯滤波器去除高频噪声、基线校正算法(如迭代多项式拟合、小波变换等)去除基线漂移,以及数据清理、数据集成、数据变换和数据归约等步骤。这些预处理措施有效提高了数据的质量,确保了后续分析的准确性。
56、4、本发明通过对不同类型的色谱图和异常情况进行适应性训练,提高了算法的鲁棒性。通过大量实验数据优化阈值设置,并采用准确率、召回率、f1分数等指标评估算法性能,确保了系统在各种复杂环境下的稳定性和可靠性。
- 还没有人留言评论。精彩留言会获得点赞!