一种浒苔数据融合处理方法及系统与流程
本发明涉及浒苔监测,具体涉及一种浒苔数据融合处理方法及系统。
背景技术:
1、自2008年夏季,黄海区域出现浒苔大规模爆发之后,每年夏季都会在黄海区域爆发大规模的浒苔灾害。大面积高密度漂浮浒苔会遮挡海面光照,降低浮游植物光合作用,改变海洋初级生产过程与物质能量流动,影响海洋生态系统结构与功能。
2、浒苔绿潮在暴发早期有一段高速增长期。这期间,浒苔绿潮在辐射沙洲至35°n之间持续时间的长短、生物量的多少,对最终浒苔绿潮暴发规模具有直接影响。监测数据显示,在绿潮暴发早期,因为所在海域的营养盐、水温、光照等条件十分适宜,藻株本身也处于快速成长阶段,浒苔绿潮整体规模呈暴发式增长,一周可以增长10倍。对浒苔进行实时监测,并前置打捞,阻断其自然暴发进程,对控制最终浒苔绿潮暴发规模具有事半功倍的效果。
3、现有技术中对浒苔进行实时监测包括传统方法依赖人工进行现场观察记录,数据通常按部门或任务类型分别收集和存储,缺乏复杂的数据融合利用和在预测模型中应用,数据存储可能依靠本地硬盘或简单的网络共享,缺乏集中化、规模化的数据中心,自动化程度低,难以应对大规模数据的高效处理和管理需求。
技术实现思路
1、(一)发明目的
2、本发明的目的是提供一种能对多源的浒苔监测数据进行融合利用,提高数据存储的自动化程度,满足大规模数据的高效处理和管理需求的浒苔数据融合处理方法及系统。
3、(二)技术方案
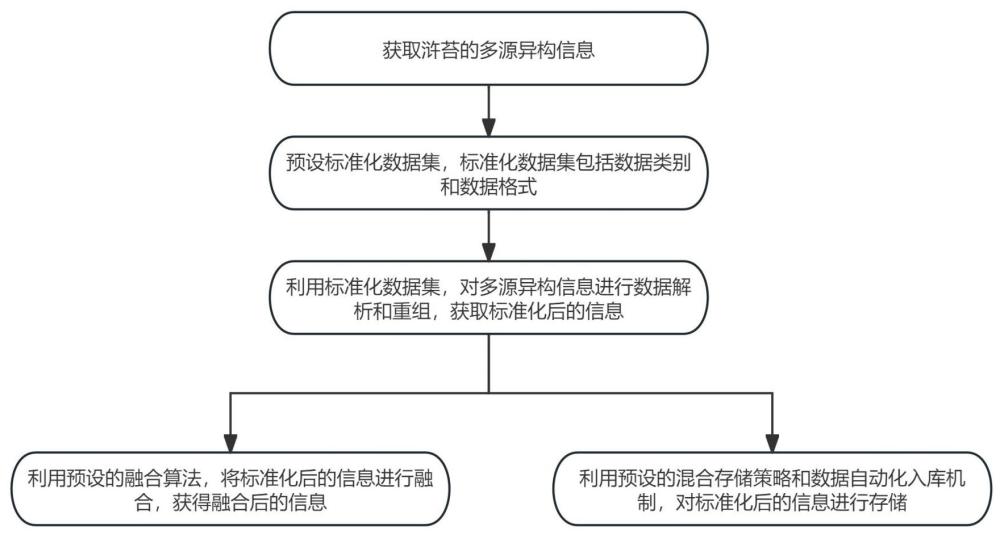
4、为解决上述问题,本发明提供了一种浒苔数据融合处理方法,包括:
5、获取浒苔的多源异构信息;
6、预设标准化数据集,所述标准化数据集包括数据类别和数据格式;
7、利用所述标准化数据集,对所述多源异构信息进行数据解析和重组,获取标准化后的信息;
8、利用预设的融合算法,将所述标准化后的信息进行融合,获得融合后的信息;
9、利用预设的混合存储策略和数据自动化入库机制,对所述标准化后的信息进行存储。
10、本发明的另一方面,优选地,所述数据类别包括:空间数据、实时动态数据、监测数据、气象环境数据和人员与管理数据;
11、所述空间数据包括:前置打捞空间数据和基础地理数据;
12、所述实时动态数据包括:船舶动态信息ais数据、现场打捞数据和现场监管数据;
13、所述监测数据包括:多手段浒苔监测数据和浒苔分布及漂移数据;
14、所述气象环境数据包括:海洋气象环境观测预报数据;
15、所述人员与管理数据包括:人员信息和养殖区防控监管数据。
16、本发明的另一方面,优选地,利用所述标准化数据集,对所述多源异构信息进行数据解析和重组,获取标准化后的信息包括:
17、对所述多源异构信息进行数据清洗,获取的清洗后的信息;
18、对所述清洗后的信息按照预设的标准化数据集进行格式统一,获得格式统一后的信息;
19、对所述格式统一后的信息进行数据转换,将非结构数据转换为结构化数据,获得数据转换后的信息;
20、对所述数据转换后的信息进行数值标准化处理,获得标准化后的信息。
21、本发明的另一方面,优选地,利用所述融合算法,将所述标准化后的信息进行融合,获得融合后的信息包括:
22、将所述标准化后的信息进行时空配准,将所述标准化后的信息的时间序列数据与空间数据匹配,获得时空匹配后的信息;
23、对所述时空匹配后的信息按照数据类别设置相应的权重,获得第一信息;
24、对所述第一信息,利用贝叶斯网络表示各数据类别之间的依赖关系,获得第二信息。
25、本发明的另一方面,优选地,利用所述融合算法,将所述标准化后的信息进行融合,获得融合后的信息还包括:
26、对所述第二信息进行特征提取,获得浒苔的分布信息;
27、将所述浒苔的分布信息与气象环境数据类,进行融合,预测浒苔动态。
28、本发明的另一方面,优选地,对所述第二信息进行特征提取,获得浒苔的分布信息包括:
29、将所述第二信息中的遥感图像裁剪成固定大小,进行数据增强;
30、利用卷积神经网络进行特征提取;
31、所述卷积神经网络的卷积层来捕捉遥感图像中的局部模式;
32、所述卷积神经网络的池化层来减少特征图的尺寸;
33、所述卷积神经网络的全连接层来连接卷积层的输出,进行分类或回归,获得提取的特征;
34、利用所述提取的特征进行浒苔覆盖区域的分类或定位。
35、本发明的另一方面,优选地,将所述浒苔的分布信息与气象环境数据,进行融合,预测浒苔动态包括:
36、根据所述浒苔的分布信息中的规模信息和气象环境数据中的光照及温度,利用生长模型,预测浒苔动态中的浒苔生长信息;
37、根据所述浒苔的分布信息中的定位信息和气象环境数据中的风向信息,利用漂移模型,预测浒苔动态中的浒苔的位置信息。
38、本发明的另一方面,优选地,所述预设混合存储策略和数据自动化入库机制,对所述标准化后的信息进行存储包括:
39、建立数据库和文件系统,所述数据库包括浒苔监测数据库、防控监管数据库、船舶信息数据库、人员信息数据库和打捞监管数据库,所述文件系统包括打捞监管文件系统;
40、将所述融合后的信息中的结构化数据存储于数据库中,将所述融合后的信息中的非结构化数据存储于文件系统中;
41、所述数据库设置为选择关系型数据库;
42、所述数据自动化入库机制设置为etl流程,并使用kafka消息队列技术来缓冲实时数据流。
43、本发明的另一方面,优选地,所述预设混合存储策略包括:
44、在所述数据库中存储非结构化数据的元数据,非结构化数据的实际文件存储于所述文件系统,通过数据库中的链接指向文件系统中的实际位置;
45、预设数据访问频率阈值,对高频访问的数据库记录或文件使用缓存技术来加速访问速度;
46、根据所述数据访问频率阈值,将存储介质分成不同存储层级。
47、本发明的另一方面,优选地,一种浒苔数据融合处理系统,包括:
48、获取模块:获取浒苔的多源异构信息;
49、预设模块:预设标准化数据集,所述标准化数据集包括数据类别和数据格式;
50、解析和重组模块:利用所述标准化数据集,对所述多源异构信息进行数据解析和重组,获取标准化后的信息;
51、融合模块:利用预设的所述融合算法,将所述标准化后的信息进行融合,获得融合后的信息;
52、存储模块:利用预设的混合存储策略和数据自动化入库机制,对所述标准化后的信息进行存储。
53、(三)有益效果
54、本发明的上述技术方案具有如下有益的技术效果:
55、本发明通过预设标准化数据集,对多源异构的浒苔数据进行统一解析和重组,确保了数据的格式一致性和内容准确性。这种标准化处理过程消除了不同数据源间的格式差异和潜在的数据冲突,为后续的数据分析和应用提供了高质量的数据基础。利用预设的融合算法,将标准化后的多源信息进行有机融合,能够更全面地反映浒苔的实际情况和变化趋势。这种融合不仅提高了数据的丰富度和综合性,还有助于发现单一数据源难以揭示的规律和特征。预设的混合存储策略和数据自动化入库机制,确保了融合后数据的高效存储和便捷管理。混合存储策略可以根据数据的特性和访问需求,灵活选择最适合的存储方式,同时,数据自动化入库机制减少了人工干预,降低了出错率,提高了数据处理的整体效率。
- 还没有人留言评论。精彩留言会获得点赞!