车辆座舱内的对象行为识别方法、车辆及存储介质与流程
本技术涉及车辆,特别是涉及一种车辆座舱内的对象行为识别方法、车辆及存储介质。
背景技术:
1、目前,车辆座舱内的多对象行为识别方法主要是通过以下方式实现的:对主驾驶位图像帧序列进行人脸检测,若检测到人脸,则在人脸感兴趣区域(region of interest,roi)进行人脸关键点回归;根据关键点截取roi区域的图像,例如,若要判断主驾驶位用户是否吸烟,则截取嘴巴附近roi区域的图像,同时,若要判断主驾驶位用户是否打电话,则截取眼睛附近roi区域的图像;之后,将截取的嘴巴附近roi区域的图像输入到吸烟图像分类模型中进行主驾驶位用户吸烟行为判断,将截取的眼睛附近roi区域的图像输入到打电话图像分类模型中进行主驾驶位用户打电话行为判断。其中,吸烟图像分类模型和打电话图像分类模型是同一种分类模型,这样,无形中浪费了计算设备的算力资源。
2、因此,在对车辆座舱内的多对象行为进行识别的过程中,如何减少算力资源的浪费成为了一个亟待解决的问题。
技术实现思路
1、本技术实施例提供了一种车辆座舱内的对象行为识别方法、车辆及存储介质,可在对车辆座舱内的多对象行为进行识别的过程中,减少算力资源的浪费。
2、第一方面,本技术实施例提供了一种车辆座舱内的对象行为识别方法,该方法包括:
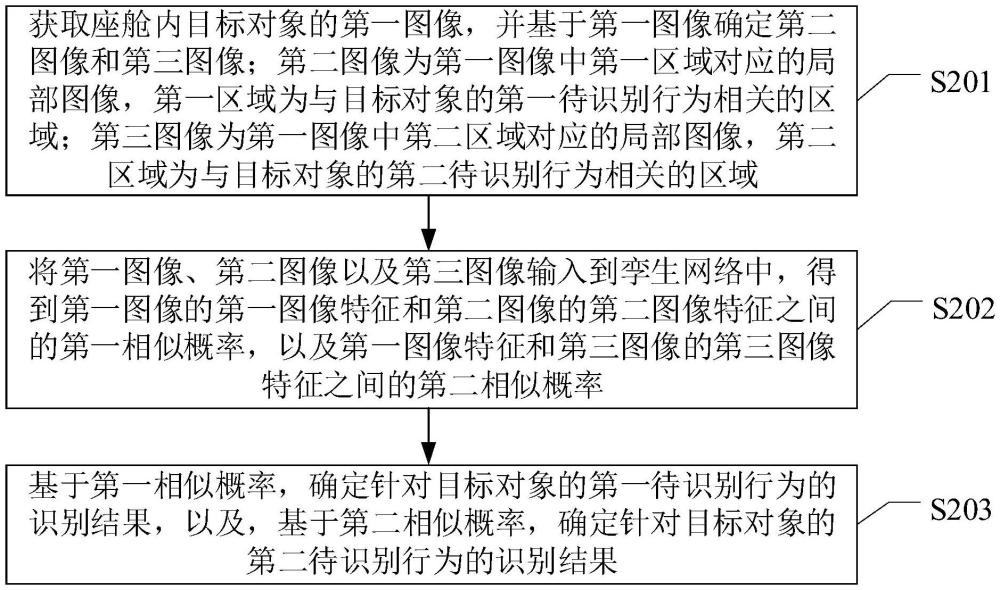
3、获取座舱内目标对象的第一图像,并基于第一图像确定第二图像和第三图像;第二图像为第一图像中第一区域对应的局部图像,第一区域为与目标对象的第一待识别行为相关的区域;第三图像为第一图像中第二区域对应的局部图像,第二区域为与目标对象的第二待识别行为相关的区域;
4、将第一图像、第二图像以及第三图像输入到孪生网络中,得到第一图像的第一图像特征和第二图像的第二图像特征之间的第一相似概率,以及第一图像特征和第三图像的第三图像特征之间的第二相似概率;
5、基于第一相似概率,确定针对目标对象的第一待识别行为的识别结果,以及,基于第二相似概率,确定针对目标对象的第二待识别行为的识别结果;
6、其中,孪生网络中至少一个分支被共享,孪生网络是利用多个样本组训练得到的;每个样本组是由样本对象的第一样本图像、第二样本图像以及第三样本图像构成的;第二样本图像为第一样本图像中第一区域对应的局部图像;第三样本图像为第一样本图像中第二区域对应的局部图像。
7、在其中一个实施例中,孪生网络中包括第一特征提取网络、第二特征提取网络以及第三特征提取网络;将第一图像、第二图像以及第三图像输入到孪生网络中,得到第一图像的第一图像特征和第二图像的第二图像特征之间的第一相似概率,以及第一图像特征和第三图像的第三图像特征之间的第二相似概率,包括:将第一图像、第二图像以及第三图像分别输入到第一特征提取网络、第二特征提取网络以及第三特征提取网络中,分别得到第一图像的第一图像特征、第二图像的第二图像特征以及第三图像的第三图像特征;确定第一图像特征和第二图像特征之间的第一相似度,以及,确定第一图像特征和第三图像特征之间的第二相似度;将第一相似度转化为预设取值区间内的第一目标值,并将第一目标值作为第一图像特征和第二图像特征之间的第一相似概率,以及,将第二相似度转化为预设取值区间内的第二目标值,并将第二目标值作为第一图像特征和第三图像特征之间的第二相似概率。
8、在其中一个实施例中,基于第一相似概率,确定针对目标对象的第一待识别行为的识别结果,以及,基于第二相似概率,确定针对目标对象的第二待识别行为的识别结果,包括:在确定第一相似概率大于第一预设阈值的情况下,确定针对目标对象的第一待识别行为的识别结果为发生第一待识别行为;以及,在确定第二相似概率大于第二预设阈值的情况下,确定针对目标对象的第二待识别行为的识别结果为发生第二待识别行为;其中,第一预设阈值和第二预设阈值相同或不同。
9、在其中一个实施例中,该方法还包括:输出提示信息,提示信息用于指示针对目标对象的第一待识别行为和第二待识别行为的识别结果。
10、在其中一个实施例中,孪生网络通过以下方式训练得到:针对每个样本组,将该样本组中的第一样本图像、第二样本图像以及第三样本图像分别输入到待训练孪生网络包括的第一特征提取网络、第二特征提取网络以及第三特征提取网络中,分别得到第一样本图像特征、第二样本图像特征以及第三样本图像特征;确定该样本组的总损失值;总损失值值由第一损失值、第二损失值、第三损失值以及第四损失值构成;第一损失值为第一样本图像、第二样本图像以及第三样本图像之间的损失值,第一损失值是基于第一样本图像特征、第二样本图像特征以及第三样本图像特征确定的;第二损失值为样本对象的第一预测行为与样本对象的实际行为之间的损失值,第一预测行为是通过将第一样本图像特征输入到待训练孪生网络包括的第一分类网络中得到的;第三损失值为样本对象的第二预测行为与样本对象的实际第一行为之间的损失值,第二预测行为是通过将第二样本图像特征输入到待训练孪生网络包括的第二分类网络中得到的;第四损失值为样本对象的第三预测行为与样本对象的实际第二行为之间的损失值,第三预测行为是通过将第三样本图像特征输入到待训练孪生网络包括的第三分类网络中得到的;当存在任一样本组的总损失值不满足停止训练条件时,基于每个样本组的总损失值更新待训练孪生网络的网络参数,并再次训练待训练孪生网络,直至多个样本组分别的总损失值均满足停止训练条件,得到孪生网络。
11、在其中一个实施例中,第一损失值是通过以下方式确定的:确定第一样本图像特征和第二样本图像特征之间的第一样本图像特征相似度,以及,确定第一样本图像特征和第三样本图像特征之间的第二样本图像特征相似度;基于第一样本图像特征相似度和第二样本图像特征相似度,确定第一样本图像特征、第二样本图像特征以及第三样本图像特征之间的总样本图像特征相似度;将总样本图像特征相似度转化为预设取值区间内的样本图像特征相似概率;基于样本图像特征相似概率,确定第一样本图像、第二样本图像以及第三样本图像之间的第一损失值。
12、在其中一个实施例中,第二损失值、第三损失值以及第四损失值是通过以下方式确定的:将第一样本图像特征输入到待训练孪生网络包括的第一分类网络中,得到样本对象的第一预测行为;基于第一损失函数,确定第一预测行为和样本对象的实际行为之间的第二损失值;将第二样本图像特征输入到待训练孪生网络包括的第二分类网络中,得到样本对象的第二预测行为;基于第二损失函数,确定第一预测行为和样本对象的实际第一行为之间的第三损失值;以及,将第三样本图像特征输入到待训练孪生网络包括的第三分类网络中,得到样本对象的第三预测行为;基于第三损失函数,确定第三预测行为和样本对象的实际第二行为之间的第四损失值。
13、在其中一个实施例中,基于第一图像确定第二图像和第三图像,包括:将第一图像输入到人脸检测模型中,在检测到第一图像中包含目标对象的情况下,输出目标对象对应的人脸信息;基于人脸信息,从第一图像中截取目标对象对应的人脸图像;将人脸图像输入到人脸关键点检测模型中,得到目标对象的人脸关键点坐标;基于人脸关键点坐标确定第一区域和第二区域,并从人脸图像中获取第一区域对应的第二图像和第二区域对应的第三图像。
14、第二方面,本技术实施例提供了一种车辆座舱内的对象行为识别装置,该装置包括:
15、获取与确定模块,用于获取座舱内目标对象的第一图像,并基于第一图像确定第二图像和第三图像;第二图像为第一图像中第一区域对应的局部图像,第一区域为与目标对象的第一待识别行为相关的区域;第三图像为第一图像中第二区域对应的局部图像,第二区域为与目标对象的第二待识别行为相关的区域;
16、处理模块,用于将第一图像、第二图像以及第三图像输入到孪生网络中,得到第一图像的第一图像特征和第二图像的第二图像特征之间的第一相似概率,以及第一图像特征和第三图像的第三图像特征之间的第二相似概率;
17、确定模块,用于基于第一相似概率,确定针对目标对象的第一待识别行为的识别结果,以及,基于第二相似概率,确定针对目标对象的第二待识别行为的识别结果;
18、其中,孪生网络中至少一个分支被共享,孪生网络是利用多个样本组训练得到的;每个样本组是由样本对象的第一样本图像、第二样本图像以及第三样本图像构成的;第二样本图像为第一样本图像中第一区域对应的局部图像;第三样本图像为第一样本图像中第二区域对应的局部图像。
19、第三方面,本技术实施例提供了一种车辆控制设备,包括存储器和处理器,存储器存储有计算机程序;处理器执行计算机程序时实现如下步骤:
20、获取座舱内目标对象的第一图像,并基于第一图像确定第二图像和第三图像;第二图像为第一图像中第一区域对应的局部图像,第一区域为与目标对象的第一待识别行为相关的区域;第三图像为第一图像中第二区域对应的局部图像,第二区域为与目标对象的第二待识别行为相关的区域;
21、将第一图像、第二图像以及第三图像输入到孪生网络中,得到第一图像的第一图像特征和第二图像的第二图像特征之间的第一相似概率,以及第一图像特征和第三图像的第三图像特征之间的第二相似概率;
22、基于第一相似概率,确定针对目标对象的第一待识别行为的识别结果,以及,基于第二相似概率,确定针对目标对象的第二待识别行为的识别结果;
23、其中,孪生网络中至少一个分支被共享,孪生网络是利用多个样本组训练得到的;每个样本组是由样本对象的第一样本图像、第二样本图像以及第三样本图像构成的;第二样本图像为第一样本图像中第一区域对应的局部图像;第三样本图像为第一样本图像中第二区域对应的局部图像。
24、第四方面,本技术还提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:
25、获取座舱内目标对象的第一图像,并基于第一图像确定第二图像和第三图像;第二图像为第一图像中第一区域对应的局部图像,第一区域为与目标对象的第一待识别行为相关的区域;第三图像为第一图像中第二区域对应的局部图像,第二区域为与目标对象的第二待识别行为相关的区域;
26、将第一图像、第二图像以及第三图像输入到孪生网络中,得到第一图像的第一图像特征和第二图像的第二图像特征之间的第一相似概率,以及第一图像特征和第三图像的第三图像特征之间的第二相似概率;
27、基于第一相似概率,确定针对目标对象的第一待识别行为的识别结果,以及,基于第二相似概率,确定针对目标对象的第二待识别行为的识别结果;
28、其中,孪生网络中至少一个分支被共享,孪生网络是利用多个样本组训练得到的;每个样本组是由样本对象的第一样本图像、第二样本图像以及第三样本图像构成的;第二样本图像为第一样本图像中第一区域对应的局部图像;第三样本图像为第一样本图像中第二区域对应的局部图像。
29、第五方面,本技术还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
30、获取座舱内目标对象的第一图像,并基于第一图像确定第二图像和第三图像;第二图像为第一图像中第一区域对应的局部图像,第一区域为与目标对象的第一待识别行为相关的区域;第三图像为第一图像中第二区域对应的局部图像,第二区域为与目标对象的第二待识别行为相关的区域;
31、将第一图像、第二图像以及第三图像输入到孪生网络中,得到第一图像的第一图像特征和第二图像的第二图像特征之间的第一相似概率,以及第一图像特征和第三图像的第三图像特征之间的第二相似概率;
32、基于第一相似概率,确定针对目标对象的第一待识别行为的识别结果,以及,基于第二相似概率,确定针对目标对象的第二待识别行为的识别结果;
33、其中,孪生网络中至少一个分支被共享,孪生网络是利用多个样本组训练得到的;每个样本组是由样本对象的第一样本图像、第二样本图像以及第三样本图像构成的;第二样本图像为第一样本图像中第一区域对应的局部图像;第三样本图像为第一样本图像中第二区域对应的局部图像。
34、第六方面,本技术还提供了一种车辆,包括车辆处理器和图像采集设备;图像采集设备用于采集座舱内包括目标对象的图像;车辆处理器用于对图像进行处理,得到目标对象的第一图像,并执行第一方面所设计的方法中的步骤,以确定针对目标对象的待识别行为的识别结果。
35、上述车辆座舱内的对象行为识别方法、车辆及存储介质,车辆可获取座舱内目标对象的第一图像,并基于第一图像确定第二图像和第三图像;第二图像为第一图像中第一区域对应的局部图像,第一区域为与目标对象的第一待识别行为相关的区域;第三图像为第一图像中第二区域对应的局部图像,第二区域为与目标对象的第二待识别行为相关的区域将第一图像、第二图像以及第三图像输入到孪生网络中,得到第一图像的第一图像特征和第二图像的第二图像特征之间的第一相似概率,以及第一图像特征和第三图像的第三图像特征之间的第二相似概率;基于第一相似概率,确定针对目标对象的第一待识别行为的识别结果,以及,基于第二相似概率,确定针对目标对象的第二待识别行为的识别结果;其中,孪生网络中至少一个分支被共享,孪生网络是利用多个样本组训练得到的;每个样本组是由样本对象的第一样本图像、第二样本图像以及第三样本图像构成的;第二样本图像为第一样本图像中第一区域对应的局部图像;第三样本图像为第一样本图像中第二区域对应的局部图像。采用该方法,相比于在进行多对象行为识别时,部署两个同一种分类模型的方法而言,车辆可利用多任务学习的方式,将第一图像(全图图像)、第二图像(与第一待识别行为相关的第一区域对应的局部图像)和第三图像(与第二待识别行为相关的第一区域对应的局部图像)共同输入到孪生网络中,得到第一图像特征、第二图像特征以及第三图像特征三者之间的相似概率,之后,基于相似概率,确定针对所述目标对象的多个行为的识别结果,从而,可减少算力资源的浪费。
- 还没有人留言评论。精彩留言会获得点赞!