针对大视场小目标的多尺度图像目标检测方法与流程
本发明属于人工智能和图像目标检测。
背景技术:
1、图像目标检测是计算机视觉领域的一项重要任务,其目的是在图像中准确地定位和识别出感兴趣的目标。随着深度学习的兴起,图像目标检测技术取得了显著进步,基于深度学习的方法如faster r-cnn、yolo、ssd等已经成为目标检测领域的主流方法,解决了图像识别和视觉应用相关的众多问题。
2、基于深度学习的图像目标检测算法的核心是卷积神经网络等可训练结构,由于神经网络对输入数据的维度和长度一般有严格要求,目标检测算法在处理输入图像时,需将图像强制转换到某个特定的尺寸,或者经过逐层特征提取后将数据转换到某个特定尺寸,然后才能将数据输入分类层完成最终的目标分类识别。具体实现时,基于深度学习的目标检测算法一般通过设置超参数对数据的维度和长度等数据尺寸进行限制,这种处理方法虽然解决了模型对于图像尺寸变化的适应性,也可以适应大部分常见的图像目标检测应用场景,但对于目标成像尺寸变化较大的目标检测场景适应性不足,特别是对目标成像后的像素尺寸差别很大时,如对地遥感、高空侦察、远距离探测成像等大视场小目标场景,将会导致严重的算法泛化问题。另外,必须注意到的是,大视场小目标在现实中是普遍存在的问题,因为随着光学系统视场变化,本身物理尺寸再大的目标也可能变成小目标,物理尺寸再小的目标也会变成大目标,也就是说,大视场小目标是一种相对变化的情况,而不是绝对的概念。
3、通过超参数强制变换输入数据尺寸的风险在于将输入图像强制变换为某个尺寸时,图像数据和信息的损失是不可控的。输入图像原本尺寸大损失的数据和信息多,输入图像原本尺寸小则损失的数据和信息就少;如果目标成像后的像素尺寸大,损失的数据和信息就多,反之则损失的数据和信息少。由此可见,当一个模型需要同时检测不同类别的目标,或者同一目标成像后的像素尺寸变化较大时,由于对输入图像进行强制尺寸变换导致的数据和信息损失不可控引起的目标检测困难将愈发突出。
4、虽然基于深度学习的目标检测算法本身对不同目标类型及目标成像后的尺度变化也有所考虑,如采用不同尺寸和高宽比的锚框,即多尺度锚框法,但是为了不过分增加计算复杂度,目标检测采用的锚框尺寸和高宽比的数量只能采用有限的几种,并不能很好地解决大视场小目标检测问题。
5、因此,基于深度学习的目标检测方法,如faster r-cnn、r-fcn、yolo和ssd等,虽然已经成为领域内主流通用算法,但由于基于深度学习的目标检测框架在最后分类时对数据的维度和长度等数据尺寸进行限制,容易导致小尺度图像目标的信息损失不可控,主流的faster r-cnn、r-fcn、yolo和ssd等基于深度学习的图像目标检测算法一般只适用于视场内大型或中等成像尺寸的目标检测,难以适应现实中广泛存在的大视场小目标检测问题。
6、总的来说,针对国防工业、军民应用等特殊领域客观存在的成像尺度大范围变化的目标检测问题,难以直接应用当前主流的基于深度学习的算法框架有效解决,亟需一种可以针对性解决大视场小目标检测问题的创新方法。
7、既然基于深度学习的目标检测算法后端进行分类时必须将数据维度转换到一个固定尺寸是导致输入图像数据和信息损失不可控,从而造成当前主流目标检测框架难以有效应对目标成像尺度剧烈变化场景的根本原因,似乎可以通过突破这种限制来解决问题。然而,虽然图像金字塔、随机剪枝等技术可以让神经网络适应不同尺寸的数据输入或使神经网络内部的连接机制可以动态变化,但是神经网络输出层及其内部结构神经元数量是不可随意改变的,目前也难以提出使神经网络结构弹性可变的有效方法。因此,现阶段难以通过优化神经网络内部结构来改进基于深度学习的目标检测算法适应大视场小目标检测问题。
8、通过研究发现,目标检测识别效果除了与算法模型本身有直接关联外,待检测图像本身属性也会影响目标检测效果,这些影响因素除了众所周知的图像清晰图、对比度等相关的图像质量外,图像尺寸大小也会直接影响目标检测效果。具体表现为,出现一张图像上同一个目标以不同尺寸数据输入目标检测算法模型时,有些尺寸可以准确检测出该目标,而有些尺寸却出现漏检的情况。由此可见,目标成像尺寸与图像本身的数据尺寸的相对大小也会影响目标检测效果,出现这种情况的根本原因正是前文分析的强制变换输入数据尺寸导致的图像数据和信息损失不可控问题。
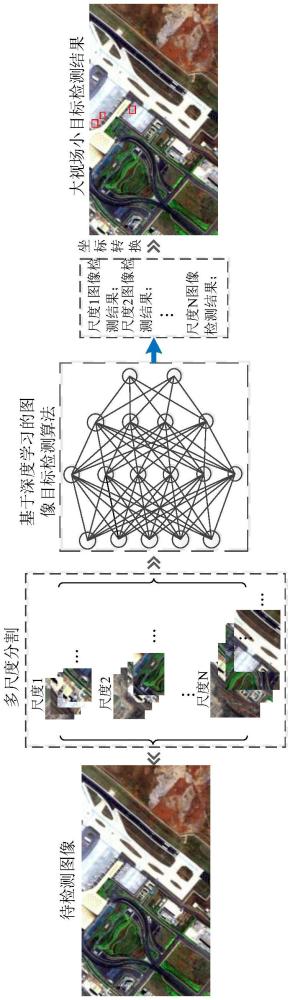
9、针对这一问题,既然神经网络结构不能动态变化调整适应不同成像尺寸目标检测的需要,就只能通过改变图像数据输入目标检测模型的方法来解决该问题。因为图像本身是可以分割和剪切的,在光电设备输出的原始图像基础上,如果将原始图像分割为小图像,就可以改变图像尺寸与目标成像尺寸的相对比例,从而为不同尺度的目标检测带来更多可能。在此基础上,再解决从分割后的小图像检测结果到原始大图像之间的映射关系,就可以将难以直接检测目标的大图像转换为小图像来实现针对小目标的检测,从而为解决大视场小目标检测难题提供一种可行的技术解决思路。
10、基于以上问题和分析,本发明的核心技术思路是,从输入目标检测算法的数据上来解决问题,对于具有大视场小目标特性的问题,将原始图像按不同尺度分割为小图像再输入目标检测算法模型算法,在小图像上检测出小目标后,再将结果映射回原来的大图像,就可以通过小图像检测的方式实现原图像上大视场小目标检测的正对性优化。
技术实现思路
1、本发明针对现实中因为目标尺度和目标成像尺度差异大导致的目标检测困难问题,提出并设计了一种针对大视场小目标的多尺度图像目标检测方法,在faster r-cnn、yolo、ssd等主流的基于深度学习的图像目标检测算法的基础上,通过将待检测的大尺寸图像分割为多尺度小图像后送入目标检测算法做检测处理,解决目前主流目标检测算将输入图像强制变换为某个尺寸时图像数据和和信息损失不可控导致的小目标检测难题,从而改进了现有图像目标检测识别方法,提高了针对大视场小目标场景的应用能力。
2、首先,开发基于深度学习的图像检测模型。针对有大视场小目标特性的目标检测问题,不能直接将原始图像输入卷积神经网络来训练模型,否则会因为小目标信息被剧烈压缩而导致小尺度目标难以检测。正确做法是,在获取图像数据样本后,按照不同类别待检测小目标的成像尺寸,设置合适的大图像切割方法,然后将包含标记信息的小尺寸图像作为数据样本开展模型训练与测试工作。采用这种方法才有可能训练获得具有小目标检测能力的目标检测模型;
3、其次,在训练获得具有小目标检测能力的基于深度学习的目标检测模型后的关键是要设计科学、合理的原始图像分割方法。考虑到图像目标检测往往要同时检测不同类型、不同成像尺度的目标,同类目标或不同类目标的成像尺度会存在剧烈的变化和差异。例如,对于20000×15000像素的原始图像,如果其中a类目标的成像尺度大概在50×50像素,而b类目标测成像尺度大概在1000×1000像素,把20000×15000像素的原始图像直接输入目标检测模型大概率可以完成a类目标检测,而b目标则基本难以检测出来。因此,本发明采用多尺度的图像分割方法,根据不同类别目标成像的尺度特征,设置不同尺度的分割以适应不同类别或不同尺度成像目标的检测需要。图像分割尺度及尺度数量的选择和设置应该根据实际到检测目标成像尺度的差别情况设置,以不过分增加目标检测计算复杂度和时间开销又可以满足不同尺度成像目标的检测为宜。另外,需要进一步说明的是,在进行图像分割时,应该采取有重叠的分割方法,如以10%的左右和上下重叠率将原始大图像分割为小尺寸图像,其作用是避免出现目标被切碎而难以检测的问题,重叠率的设置应根据分割尺寸和目标成像尺寸等灵活设置;
4、然后,将分割后的小图像依次输入图像目标检测模型,图像目标检测模型按正常目标检测流程处理小尺寸图像,就可以在小尺寸图像上检测出小目标,不会因为图像尺寸远大于目标成像尺度而导致目标信息严重损失难以正确检出目标。
5、最后,由于原始图像的像素坐标可能与经纬度、方位、距离等外部物理世界信息相关,因此,在将原始图像分割为多尺度小图像时,应记录小图像素坐标与原始大图像素坐标的映射关系,这样在小图像上检测出目标后,就可以将检测出来的在小图像上的目标像素坐标信息快速转换回大图像素坐标上,实现在原始大图像上的小目标检测。
6、通过以上技术途径,即可解决目前主流的基于深度学习的图像目标检测框架对大视场小目标检测能力的不足,提高目标检测算法解决现实中图像目标检测问题的能力,是对现有传统目标检测方法针对大视场小目标检测场景的一种有效改进。
7、本发明的创新点体现在通过对待检测图像进行多尺度分割,针对性地解决了目前主流目标检测方法在在面对具有大场景小目标特性的目标检测任务时输入数据尺寸被强行转换导致小目标信息损失不可控而难检测问题,提高了大视场下的小目标检测能力,并通过原始图像与小图像之间的像素坐标关联,可以实现小图像上的目标检测结果到原始大图像的快速映射转换,达到与目前通用的目标检测方法相同的效果,并不需要额外繁琐的结果处理,是一种经实践证明可用于大视场小目标场景目标检测的实用方法。
8、为了完成本技术的发明目的,本技术采用以下技术方案:
9、本发明的一种针对大视场小目标的多尺度图像目标检测方法,其中:它包括以下步骤:
10、(一)、通过卫星、飞机、无人机、船只或地面站点平台搭载的光电系统获得具有大视场的小目标特性的图像;
11、(二)、确定需检测识别的上述小目标
12、采用labelme或labelimg图像标注工具标注上述图像,并以合适的图像大小剪切出包含小目标特性的图像样本,图像样本的尺寸选择,以输入目标检测算法经强制尺寸变化后,不丧失目标信息为宜;
13、(三)、参照imagenet或coco数据集框架制作图像目标检测数据集,并将上述图像目标检测数据集分为训练集、测试集和验证集三个部分;
14、(四)、搭建基于tensorflow或pytorch的深度学习环境平台;
15、(五)、基于faster r-cnn、yolo或ssd框架构建基于深度学习的图像目标检测模型,使用步骤(三)中制作完成的图像目标检测数据集,在tensorflow或pytorch的深度学习环境平台上训练模型,获得目标检测性能满足应用需求的图像目标检测模型;
16、(六)、基于tensorrt、onnx或openvino平台部署步骤(五)的图像目标检测模型,将其封装为可灵活调用的计算api接口服务;
17、(七)、使用原始大图像多尺度分割工具,采用滑动窗的滑动方式对原始大图像进行第一次滑动窗遍历,滑动窗的数量、大小和高宽比例,根据待检测目标的成像尺度情况设置,并将得到的小图像输入到上述图像目标检测模型中进行目标检测,并记录滑动窗在原始大图像上的像素位置;
18、(八)、在一次滑动窗遍历完成后,改变滑动窗的数量、大小和高宽比参数,重复步骤(七)直到所有设置的滑动窗都使用完为止,获得一系列小图像上的目标检测结果;
19、(九)、根据小图像的像素坐标与原始大图像的像素坐标的映射关系,将一系列小图像上的目标检测结果转换到原始大图像上,并剔除重复的检测结果,获得在原始大图像上的目标检测结果,完成了具有大视场小目标特性的图像数据的目标检测。
20、本发明的针对大视场小目标的多尺度图像目标检测方法,其中:所述滑动窗的大小和高宽比例根据待检测目标的大小尺寸和高宽比例而定。
21、本发明的针对大视场小目标的多尺度图像目标检测方法,其中:所述训练集、测试集和验证集占图像目标检测数据集的70%、20%和10%。
22、本发明的针对大视场小目标的多尺度图像目标检测方法,其中:所述滑动窗的滑动方式是从左向右、从上到下的方式有重叠地遍历原始大图像,选取出与滑动窗的大小一样的小图像。
23、本发明的针对大视场小目标的多尺度图像目标检测方法具有以下有益效果:
24、本发明提出了一种针对大视场小目标的多尺度图像目标检测方法,通过对原始大图像的多尺度分割结合小图像目标检测结果向大图像坐标的关联回传,建立了一种解决大视场下小目标检测难题的有效方法,适合应用在具有大视场小目标特性的众多领域目标检测问题,是对当前只适应中大型目标成像尺寸检测的主流目标检测方法的针对性优化和创新性突破。
- 还没有人留言评论。精彩留言会获得点赞!