一种空气质量情况预测及污染预警方法
本发明公开了一种空气质量情况预测及污染预警方法,具体涉及对空气质量指数aqi的预测以及对空气污染程度预警方法。
背景技术:
1、随着我国现代化和城市化进程的加快,空气污染问题日益严峻,空气质量面临着多重挑战。因此,要进一步科学有效地改善空气质量,需要充分利用新一代信息技术对大气环境进行监测与预测,分析和解决具有挑战性的生态环境问题。这样,空气质量的决策和治理才能更加智能化。空气质量预测是环境管理和污染防治的一项基础性工作,为空气质量的动态调控和突发性污染事件的应急响应提供了重要参考。近年来,随着物联网技术和人工智能的快速发展,逐渐出现了性能优良、稳定性好、响应快速的空气质量检测传感器。通过收集多种空气质量传感器的数据,可以实时获取各类空气质量指标,为大气环境的实时监测与管理提供科学依据。
2、空气质量预测实际上也是一个时间序列预测的问题。通常根据历史空气质量数据,建立预测模型以预估未来一段时间内的空气质量变化趋势。目前,时间序列预测的方法主要分为传统统计方法和深度学习方法。传统方法中最常用的是arima(差分整合移动平均自回归模型),它能够捕捉特征之间的线性关系,但仅适用于平稳时间序列预测,仅考虑时间序列内部的变化规律,忽略了对空气质量有显著影响的外部因素,如天气条件和人类活动,因此在复杂的空气质量预测中应用受限。深度学习方法中,rnn(循环神经网络)可以捕获时间序列的长期依赖关系,lstm(长短期记忆网络)则有效解决了rnn中的梯度爆炸或消失问题。然而,这些方法中的超参数选择和优化依赖主观经验和反复试验。此外,这些方法通常通过对非平稳时间序列进行平稳化处理来进行预测,忽视了空气质量数据本身的非平稳特性及外部因素的动态影响。
技术实现思路
1、发明目的:针对以上技术存在的不足点,本发明提出了一种基于改进的tft模型对空气质量时间序列预测方法。该方法综合考虑区域位置、气象数据、污染源分布等对空气成分可能产生影响的额外变量,克服了传统预测模型单一变量的局限性。模型能够自动分析并提取对空气污染物浓度有重要影响的特征,从而避免了以人为主观经验为主的特征选择过程。主要预测变量包括pm2.5、pm10、so2、no2、co和o3六种主要污染物的浓度变化。采用平稳化处理非平稳的空气质量时间序列进行处理,通过去平稳的注意力机制获得各污染物浓度间的时间相关性,最后再通过去平稳化恢复到原始的非平稳性,以保持空气质量时间序列的非平稳特性,从而提高预测的准确性。
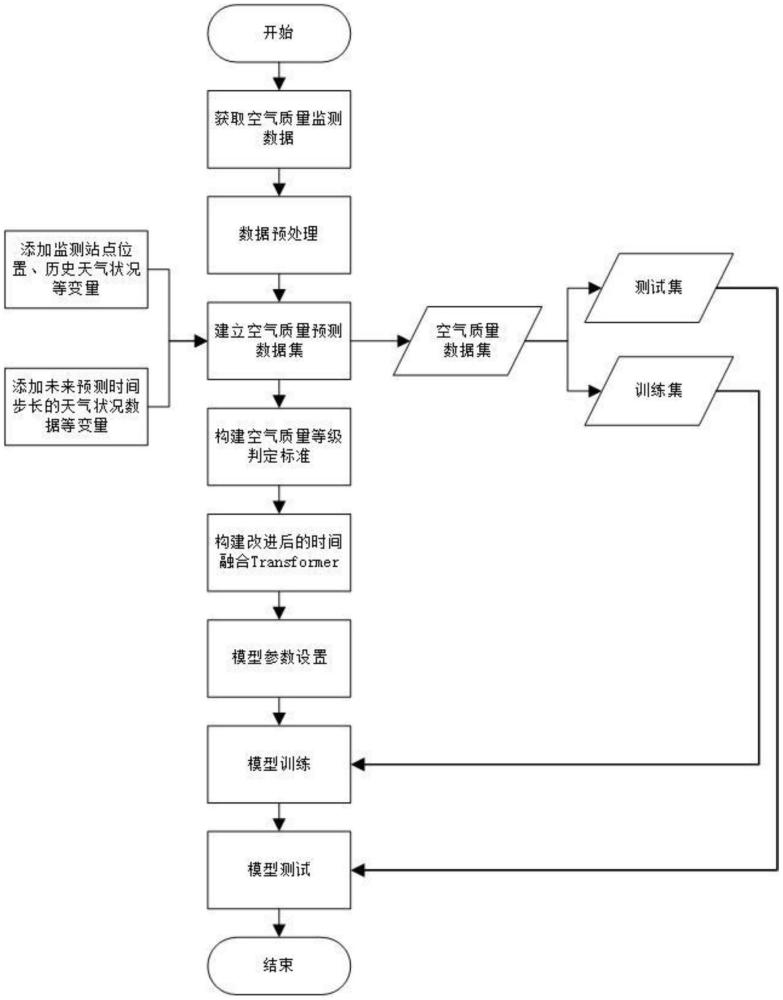
2、技术方案:为实现上述目的,本发明提出了一种基于改进的tft模型对空气质量时间序列的预测方法,包括如下步骤:
3、s1:建立空气质量监测数据库,通过在预设监测站点放置空气质量监测传感器,获取预设时间段内站点的监测数据,如pm2.5、pm10、臭氧、二氧化硫、二氧化氮、一氧化碳浓度等,对收集的监测数据进行预处理,通过对监测到的数据进行数据清洗等操作,对于采集故障、数据传输异常等原因导致数据缺失、异常值或者噪声等现象问题进行处理,存入空气质量监测数据库中;
4、s2:建立多变量空气质量预测数据集,对空气质量预测数据集变量进行手动扩充,添加额外来源的变量数据;
5、s3:划分多变量空气质量预测数据集;
6、s4:构建空气质量健康指标体系;
7、s5:基于改进的时间融合transformer模型,构建空气质量综合健康状态计算与趋势预测模型,对空气质量数据集进行训练,利用最小化分位数损失对超参数进行调优;
8、s6:通过训练好的空气质量预测模型对未来空气质量数据进行预测,为管理决策者提供未来空气质量预测信息。
9、进一步地,所述s1中建立空气质量监测数据库的方法:
10、通过在预设监测站点放置空气质量监测传感器,监测频率为每1小时监测一次,监测数据包括pm2.5、pm10、so2、no2、co、o3等主要污染物浓度。对收集的监测数据进行预处理,通过数据清洗操作来提高数据质量。
11、对收集数据中的错误值、缺失值和离群值进行处理:删除错误值,利用线性插值法填补缺失值,基于箱型图,用第三四分位数代替高离群值,用第一四分位数代替低离群值。处理完成后,数据存入空气质量监测数据库中。
12、进一步地,所述步骤s2中建立多变量空气质量预测数据集的方法为:
13、a1:建立数据存储文件,作为空气质量预测数据集文件。
14、a2:获取监测站点传感器的地理位置,通过气象局获取历史及未来预设时间段内每个时间步长的气象数据,包括气温、气压、湿度、风速、降水量等,作为可能影响空气质量的特征变量。
15、a3:对传感器监测到的数据变量进行扩充,增加监测站点的地理位置、历史气象数据、年、月、日、季节、未来气象数据等项。
16、a4:按时间顺序将这些变量存储到数据文件中,形成空气质量预测数据集文件。
17、进一步地,所述步骤s3中具体划分变量的方法为:
18、将输入的多变量数据划分为三类不同的输入,分别是静态变量、历史观测值变量以及未来已知变量。将监测站点的地理位置作为静态变量输入,将历史监测到的空气质量数据、历史气象数据、年、月、日、季节作为历史观测值变量,将未来的年、月、日、季节和气象数据作为未来的已知输入。
19、进一步地,所述步骤s4中构建空气质量健康指标体系的方法为:
20、构建设备健康状态指标体系,通过查阅资料以及专业人士评估,构建不同空气质量等级的各指标树状层次结构图;
21、设计调查问卷,邀请专业人士对指标进行评价,对各污染物指标两两比较重要性程度;
22、利用区间层次分析法计算指标权重,构造重要性矩阵,利用幂法计算矩阵特征值,并计算指标的组合权重。
23、进一步地,所述步骤s5中构建改进的时间融合transformer模型的方法为:
24、b1:改进tft模型中对非平稳时间序列的处理方法,在进行变量选择中,将选择后的时间序列变量进行平稳化处理:
25、
26、其中s是时间序列的长度,μx是单个变量的均值,是单个变量的方差,x'i是经过平稳化操作后的变量,平稳化处理后,减小了各个输入的时间序列之间的分布差异,使得输入的分布更加稳定。
27、b2:在tft模型中的静态增强层之后增加一个具有线性特性的embedding layer。此线性特性指:f(ax+by)=af(x)+bf(y)。
28、b3:改进tft模型中的注意力机制算法,将其换成去平稳注意力机制(de-stationary attention),改进后的注意力求解方法:
29、
30、来近似于得到未进行平稳化处理的注意力,可以从原始的未平稳化的数据中发现特定的时间相关性。其中τ和δ是缩放和移动的消平稳因子,用来逼近和kμq。使用多层感知机作为映射器,从统计量μx,σx和非平稳序列x中来学习平稳因子τ和δ。
31、b4:改进tft模型中的输出方法,在输出前进行去平稳化操作。
32、
33、其中y'i是预测的结果,μx是均值,σx是标准差。这样设计使得模型对时间序列有平移和缩放扰动等变化,从而有利于空气质量数据这种非平稳时间序列的预测。
34、将预测数据集按7:2:1分为三个部分的数据集,分别为训练集、验证集以及测试集。对模型进行训练,训练结束后,将预测值与已知结果进行比较,联合最小化分位数损失对超参数进行调优。
35、所述步骤s5中分位数损失计算方法为:
36、
37、对所有样本的损失求和计算方法为:
38、
39、最小化损失,求出最优超参数,建立空气质量预测模型。
40、进一步地,所述步骤s6中具体的评估指标的方法为:利用训练好的模型,对未来一周的空气质量指标进行预测,根据预测结果与指定空气污染阈值对比,若某个指标超过阈值,则表示达到空气污染程度,提前发出预警。
41、有益效果:本发明与现有技术相比,具备如下优点:
42、1、能够对空气质量这种复杂的时间序列实现多元预测,解决了单变量预测模型存在的预测时间长、无法并行处理等问题,有效地提高了预测效率。
43、2、能够综合考虑对空气质量造成影响的多种外部因素,结合多变量数据特征,使预测结果更加精准。
44、3、能够对空气质量这种非平稳性数据进行处理,使得注意力机制专注于空气质量本身的非平稳数据特征之间的相关性,从而更好地揭示污染物间的动态关系。
- 还没有人留言评论。精彩留言会获得点赞!