基于在线切换的无人驾驶网约车订单分配方法
本发明涉及无人网约车调度运筹领域,具体涉及基于在线切换的无人驾驶网约车订单分配方法。
背景技术:
1、随着无人驾驶网约车技术的不断发展,无人驾驶网约车的订单分配成为了新的研究方向。与传统网约车模式相比,无人驾驶网约车订单不会受到驾驶员主观判断影响,需要更好的算法来进行多车协同和全局调度优化,确保车辆能够高效地分配和利用。
2、传统算法基于预设的规则或优化模型,在处理动态变化情况时缺乏灵活性,且传统算法以当前时刻的最优匹配为目标,忽视长期成本最小化。强化学习算法以成本最小化为目标,但在应用模型中得到的结果为局部最优解,非全局最优解。
技术实现思路
1、本发明的技术问题是:当无人驾驶网约车的数量和订单的数量不断增加时,通过在线切换,实现多车协同和全局调度优化,在满足当前无人驾驶网约车订单分配时全局最优的情况下,也追求长期成本最小化。
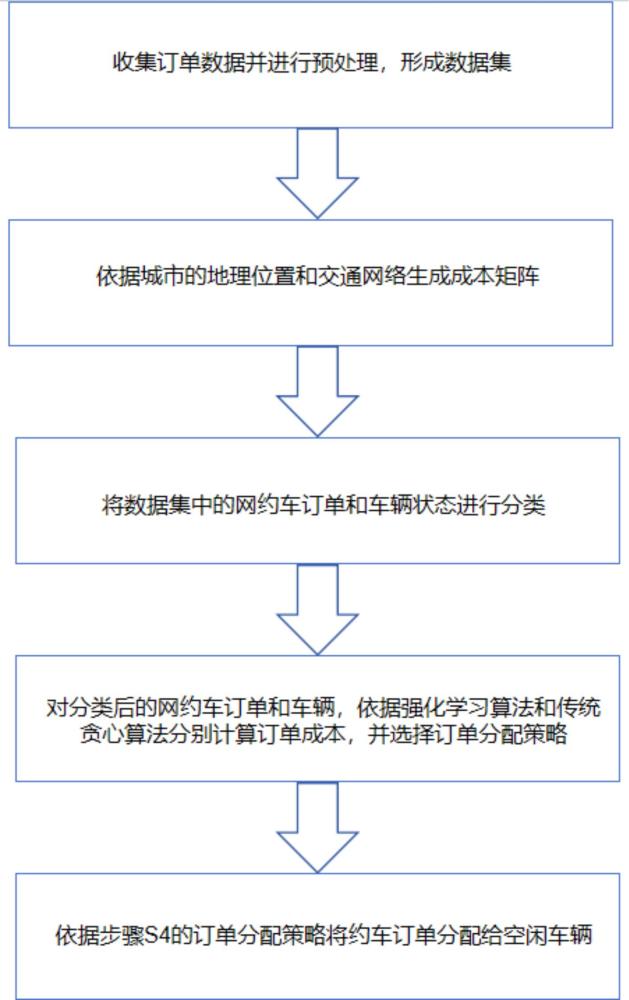
2、本发明的目的是解决上述问题,提出基于在线切换的无人驾驶网约车订单分配方法,包括如下步骤:
3、s1:收集订单数据并进行预处理,形成数据集;
4、s2:依据城市的地理位置和交通网络生成成本矩阵;
5、s3:将数据集中的网约车订单和车辆状态进行分类;
6、s4:对分类后的网约车订单和车辆,依据强化学习算法和传统贪心算法分别计算订单成本,并选择订单分配策略;
7、s5:依据步骤s4的订单分配策略将约车订单分配给空闲车辆。
8、优选的,网约车订单依据订单状态、订单时间、起始地点和目的地进行分类。
9、优选的,根据无人驾驶车辆当前位置和空闲状态对车辆状态分类,更新车辆状态。
10、进一步的,生成成本矩阵,包括以下子步骤:
11、1) 获取城市中各个地点的经纬度坐标和城市中交通网络的信息,包含道路连接、交通信号、限速和交通流量;
12、2)将地点之间的直线距离作为成本,依据道路的交通流量和限速等计算地点之间的通行时间;
13、3)将城市中的各个地点的位置作为节点,地点之间的道路作为边,每条边附加权重,作为节点之间的成本;
14、4)依据城市中的地点数量和地点之间的成本创建 n×n的成本矩阵。
15、进一步的,订单优先级根据订单状态设定优先级,等待时间越久的订单优先级越高;
16、优选的,步骤s4,贪心算法包括以下子步骤:
17、1)计算平面坐标系中两个地点的距离:
18、;
19、式中, i,j表示地点,d( i,j)表示地点 i与地点 j的距离, x, y表示坐标;
20、2)计算两个地点之间的时间成本:
21、;
22、式中, t(i,j)表示地点 i与地点 j之间的时间成本,表示从地点 i到地点 j的平均速度;
23、3)车辆和订单的匹配权值,计算公式为:
24、;
25、式中,表示车辆的起始地点,表示订单的目的地,w( )表示车辆和订单的匹配权值, k表示拥堵系数;
26、4)订单优先分配,对匹配权值进行排序,将订单分配给匹配权值最大的空闲车辆;
27、5)最大化总匹配奖励;
28、6)更新车辆状态,将分配订单的车辆的空闲状态更新为忙碌,并将车辆的位置变更为订单的终点位置。
29、优选的,步骤s4中强化学习算法,包括以下子步骤:
30、包括以下子步骤:
31、1)初始化 actor网络、 critic网络、目标网络和经验池模块;
32、2)根据当前订单分配方案,得到订单状态和奖励,并存储至经验池模块中;
33、3)使用目标网络计算目标q值;
34、4)使用 critic网络计算当前订单分配的评估值,并构造损失函数进行梯度更新;
35、5)使用 actor网络根据当前订单状态输出订单分配方案,并计算梯度;
36、6)更新目标网络的参数;
37、7)重复步骤2-7,直至达到训练结束条件。
38、优选的,步骤s4中强化学习算法,采用基于 actor-critic结构的 imp-td3算法,包含 actor网络、2个 critic网络、 actor目标网络和2个 critic目标网络。
39、进一步的,2个 critic网络用来减小q值估计的方差,并通过延迟更新和软更新的策略来提高算法的稳定性, critic网络更新的计算式为:
40、;
41、;
42、式中,表示第 i个样本的抽样权值, i表示计数单位, m表示 i的最大值,表示折扣因子,表示噪声的标准差,表示正态分布,表示噪声的限制, θ表示 critic网络参数,表示第 i个样本的 td误差,表示第 i个样本奖励,表示第 i个样本的状态 。
43、优选的,选择最小的q值计算目标估计值,减小过估计偏差,并且,为避免过拟合,向目标 critic网络添加噪声信号作为正则项。
44、优选的, actor目标网络 actor目标网络 actor目标网络通过从数据集中提取行为策略,在新的订单到来时快速作出决策,假设当前的策略为,即在状态下选择动作的概率分布,其目标是最大化期望累积奖励,更新 actor网络的参数的计算公式为:
45、;
46、式中,是actor网络的参数,是 critic网络计算的状态-动作价值函数,表示目标函数,也称为性能指标,表示当前策略在给定状态下选择动作的概率分布;
47、优选的,2个 critic目标网络用于评估车辆状态和评估订单分配的效果,对于 critic目标网络,损失函数通常采用均方误差来衡量估计的q值和实际的目标q值之间的差异,2个 critic目标网络的损失函数表达式为:
48、;
49、;
50、式中,和分别表示2个 critic目标网络状态-动作值函数,和分别为2个 critic目标网络参数,是即时奖励,是折扣因子,s表示当前的状态,表示下一个状态,表示在状态s下动作,表示在状态 s′中的下一个动作,表示第一个 critic网络的参数,表示第一个目标 critic网络的参数。
51、进一步的,在步骤s4中,所述选择订单分配策略,将强化学习算法的成本值与贪心算法的成本值、决策值和偏移值的计算结果,若强化学习算法的成本值大,则订单分配策略选择强化学习算法,否则选择贪心算法;
52、贪心算法的成本值、决策值和偏移值的计算公式为:
53、cost =ρ×rgreedy - c ;
54、式中,cost 表示计算结果的变量,c、ρ均表示人为设定的参数,取值范围分别为ρ∈[0,1],c≥0, rgreedy表示贪心算法的成本值。
55、相比现有技术,本发明的有益效果包括:
56、1)本发明提供基于在线切换的无人驾驶网约车订单分配方法,通过在线切换方法,解决随着无人驾驶网约车和订单不断增加导致的大数据量,实现多车协同和全局调度优化的同时,也满足当前无人驾驶网约车订单分配时全局最优的情况下追求长期成本最小化。
57、2)本发明提供基于在线切换的无人驾驶网约车订单分配方法,在强化学习策略表现较好时,系统优先使用采用;而在强化学习策略表现不佳时,自动切换到更为稳定的贪心算法,能有效应对因环境变化或数据稀缺导致的不确定性,可适应不同数量级的车辆和订单规模。
- 还没有人留言评论。精彩留言会获得点赞!