一种基于改进长短时记忆深度学习模型的大坝渗流预测方法
本发明属于大坝渗流领域,具体为一种基于改进长短时记忆深度学习模型的大坝渗流预测方法。
背景技术:
1、在水利工程中,大坝的安全性对防洪、灌溉、水力发电和生态环境保护等方面至关重要。大坝渗流是影响大坝稳定性和安全性的关键因素之一,精确预测大坝渗流量有助于及时采取预防和维护措施,防止灾害的发生。然而,大坝渗流受多种因素影响,包括上游水位、下游水位、上下游水位差,温度以及降雨量等,这些因素的复杂动态变化增加了预测的难度。
2、传统的渗流预测方法往往依赖于经验模型或简单的统计方法,难以充分捕捉渗流量变化的复杂时空关系。随着人工智能技术的迅猛发展,长短时记忆深度学习模型作为一种特殊的递归神经网络,在处理时间序列数据方面展现了强大的能力。该网络能够记忆并捕捉长时间序列中的重要信息,适用于渗流量的动态变化预测。
3、然而,长短时记忆网络的性能高度依赖于超参数的选择和网络结构的设计,传统的手工调参方法不仅耗时耗力,还难以找到全局最优解。遗传算法作为一种全局优化算法,能够通过模拟自然进化过程,对网络的超参数进行自动优化,但常规的遗传算法容易陷入局部最优,且收敛速度较慢。
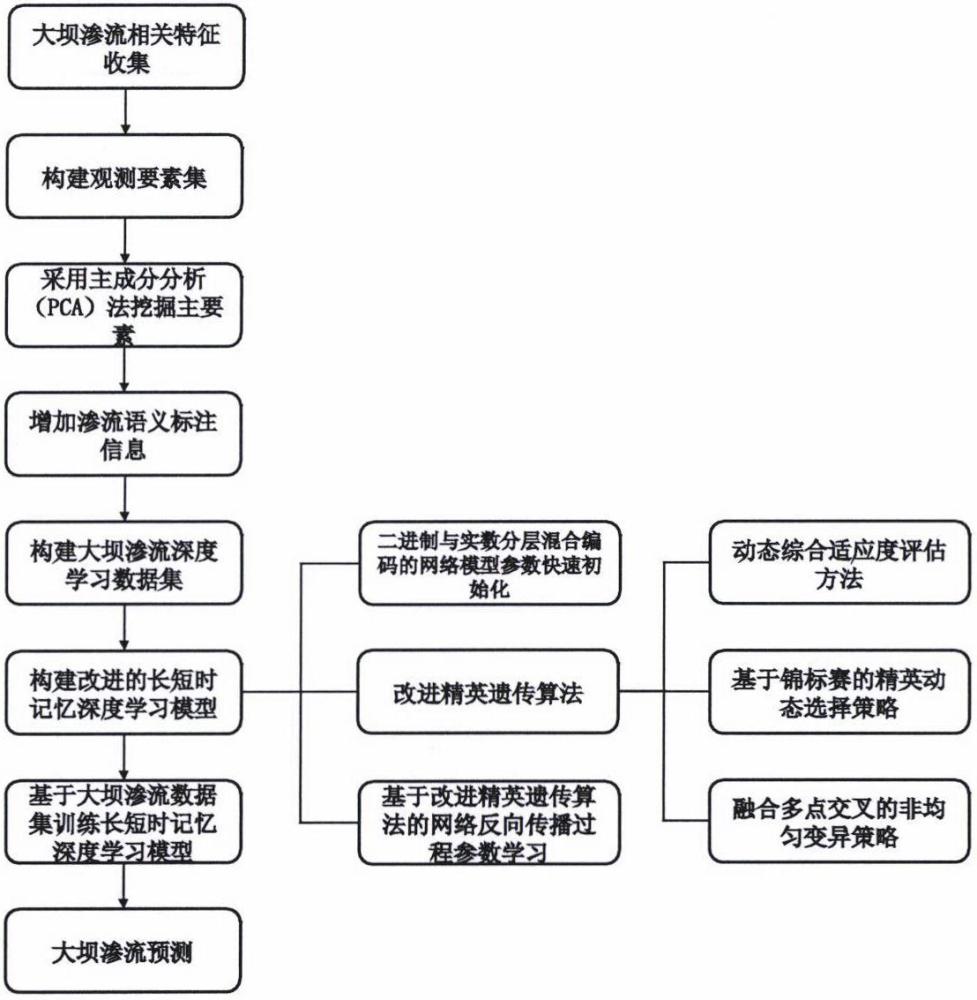
4、因此,本发明提出了一种基于改进长短时记忆深度学习模型的大坝渗流预测方法。首先通过主成分分析(pca)法从水文特征、气象特征及其交互特征中挖掘出与大坝渗流相关性最强的五大主因素-上游水位、下游水位、上下游水位差、温度及降雨量,并通过增加是否发生渗流标注信息,共同形成深度学习模型训练和测试所需的时序数据集。其次,构建改进的长短时记忆深度学习模型,该模型的创新点包括二进制与实数分层混合编码的网络模型参数快速初始化、协同精英锦标赛策略和动态综合适应度评估的改进精英遗传算法及基于改进精英遗传算法的网络反向传播过程参数学习方法。再次,基于构建的模型和数据集进行模型训练,并完成渗流预测。最后,在实际监测的数据上验证了该发明提出的方法在预测精度和泛化能力上均有较强的优势,为实现大坝渗流智能精准预测具有较强的理论价值。
技术实现思路
1、发明目的:为了实现了大坝渗流智能精准预测,本发明引入一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,为及时预防大坝渗流提供理论支持。
2、技术方案:为实现上述发明目的,本发明所采用的技术方案是:一种基于改进的长短时记忆深度学习模型的大坝渗流预测方法,包括如下步骤:
3、1.一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,其特征在于,所述方法包括如下步骤:
4、(1)构建大坝渗流深度学习数据集,包括大坝渗流关联水文特征、气象特征及其交互特征的汇集;基于主成分分析(pca)法挖掘得到大坝渗流相关性最强五大主因素-上游水位、下游水位、上下游水位差、温度及降雨量;增加是否发生渗流语义标注信息,联合五大主因素及渗流语义信息共同形成深度学习模型训练和测试所需的时序数据集;
5、(2)构建改进的长短时记忆深度学习模型,包括二进制与实数分层混合编码的网络模型参数快速初始化、协同精英锦标赛策略和动态综合适应度评估的改进精英遗传算法及基于改进精英遗传算法的网络反向传播过程参数学习方法;
6、(3)基于构建的模型和数据集进行模型训练,并完成渗流预测。
7、2.一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,其特征在于,所述步骤(1)中的数据集构建过程包括:
8、(1)构建包含水文特征、气象特征及其交互特征等13个与渗流相关的观测要素集,具体为要素观测日期、上游水位、下游水位、温度、降雨量、水位差、季节性水位、累积降雨量、降雨强度、温度变化率、极端温度、上游水位与降雨量累积、温度与降雨量累积;
9、(2)对于构建的13个观测要素,采用pca法挖掘主要素,确定对大坝渗流影响最大的五大主因素:
10、上游水位,下游水位、上下游水位差、温度及降雨量。为提高模型对渗流预警的准确性,在此基础上增加渗流语义标注信息。得到样本模型d如式(1)所示:
11、
12、其中,dup表示上游水位,ddown表示下游水位,ddiff表示上下游水位差,dtem表示温度,drain表示降雨量,dtag表示渗流语义标注信息。n表示数据集d的样本数量。最终构建的数据集包括5000个样本,其中训练集4000个样本,测试集500个样本,验证集500个样本。
13、3.一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,其特征在于,所述步骤(2)中的二进制与实数分层混合编码的网络模型参数快速初始化包括:
14、(1)基于预训练模型初始化网络模型中时间窗口值、神经元数量、网络层数、学习率和dropout值五类参数的取值范围;
15、(2)对于学习率和dropout值的取值区间离散化;
16、(3)对五类参数取值区间边界值进行二进制编码,对该区间内的实数进行实数编码,其中二进制编码公式如式(2)所示。
17、
18、其中,x表示待转换的实数,和分别表示整数部分和小数部分的转换,rk表示每次取余得到的结果,表示二进制位,m为二进制位数,且r0是最低位。bj为小数部分转换为二进制时的取整结果,p为小数部分的位数。实数编码公式如式(3)所示:
19、
20、其中,actual_value为参数实际值,scale_factor为归一化系数;
21、(4)基于二进制与实数分层混合编码模式,在时间窗口值、神经元数量、网络层数、学习率和dropout值的初始区间内进行寻优;
22、(5)通过寻优结果基于实数编码对学习率和dropout值进行精细调整,调整公式如下所示。
23、p=p0+(1+α×δ) (4)
24、其中,p表示调整后的参数值,p0表示寻优得到的参数值,α为调整系数,取值范围为[0.9,1.1],δ为随机扰动项,服从[-0.1,0.1]区间内的均匀分布。
25、4.一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,其特征在于,所述步骤(2)中的协同精英锦标赛策略和动态综合适应度评估的改进精英遗传算法包括:
26、(1)构建一种动态综合适应度评估方法,以精确评估网络模型中的时间窗口值、神经元数量、网络层数、学习率和dropout值的优劣;
27、(2)构建一种基于锦标赛的精英动态选择策略,通过组内竞争保留优良参数的同时加速参数优化速度;
28、(3)构建一种融合多点交叉的非均匀变异策略,在交叉演进中融合变异,保障变异的安全性;
29、5.一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,其特征在于,所述步骤(4)中构建的动态综合适应度评估方法包括:
30、(1)从遗传算法的视角,将评估网络模型中所求参数优劣的性能指标分为适应度指标和多样性指标;
31、(2)参数寻优进程中基于每次遗传迭代的多样性和适应度目标自适应动态调整两类指标在参数评估过程中的权重,对应的动态综合适应度评估公式为:
32、f=wa·s+wd·d+δf(t) (5)
33、其中,s是综合适应度指标,d是多样性指标,wa是适应度权重,wd是多样性权重,δf(t)是基于当前迭代数t的适应度增量。
34、(3)其迭代初期,随机选择20%的超参数作为多样性指标进行评估,降低种群陷入局部最优解的风险,提升整体搜索能力;
35、(4)根据每一次迭代代的遗传速度和适应度评估更新适应度评分,促进种群的精英特性持续提升,适应度更新公式为:
36、f′(t+1)=f(t)+δf(t) (6)
37、其中δf(t)是基于当前迭代数t的适应度增量:
38、6.一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,其特征在于,所述步骤(6)中构建的基于锦标赛的精英动态选择策略包括:
39、(1)迭代初期,将种群随机分组,基于锦标赛组内个体适应度最强者进行遗传个体的锦标赛选择,迭代演化进程中,锦标赛的组数和每组中的个体数量根据每次迭代遗传速度自适应调整,通过扩大组员数量选拔出锦标赛中更优秀的获胜者,加快遗传速度,其中动态调整分组规模的公式为:
40、
41、其中,k(t)是第t代的分组规模,t是总进化代数;
42、(2)基于组内锦标赛获胜者的适应度完成精英个体选择:
43、
44、(3)其中,w是锦标赛组内所有获胜者集合,e是精英个体集合,f(x)表示个体x的适应度评分;
45、将精英与锦标赛获胜者形成下一代的交叉和变异操作的种群;
46、7.一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,其特征在于,所述步骤(4)中构建的融合多点交叉的非均匀变异策略包括:
47、(1)在变异阶段,构建基于演进过程的个体变异概率计算公式:
48、
49、其中pm(i)是第i个个体的变异概率,p0是初始变异概率,g是当前迭代数,gmax是最大迭代数,α是用于控制变异幅度的调节因子,rand(0,1)是区间[0,1]内的随机数;当个体变异概率值大于设置的阈值时,基因位则发生变异;
50、(1)基于锦标赛的获胜者随机选择多个交叉点进行基因交换操作,交叉点处的父代个体基因将被分割成c+1段,并交替组合生成新的后代个体,公式为:
51、o=(p1[0:p1]+p2[p1:p2]+l+(-1)cpc+1[pc:l]) (10)
52、其中,o是新生成的后代个体,pi表示第i个父代个体,符号“+”表示基因片段的拼接;
53、(2)初始阶段每个基因位设置一个变异阈值,在每次变异前融合多点交叉操作,在变异不断演进中保障变异群体的安全性不断更新变异概率,当求得的个体变异概率值大于设置的阈值时,基因位则发生变异;
54、8.一种基于改进长短时记忆深度学习模型的大坝渗流预测方法,其特征在于,所述步骤(2)中基于改进精英遗传算法的网络反向传播过程参数学习方法:
55、(1)构建基于改进的精英遗传算法的网络参数优化模型,其中目标函数为改进的长短时记忆神经网络模型的损失函数,决策变量为不断迭代过程中生成的种群个体的动态综合适应度;
56、(2)构建改进的长短时记忆神经网络模型损失函数:
57、
58、其中y是实际输出,是模型预测输出,n是样本数量;
59、(3)基于改进的精英遗传算法对网络参数最优解持续学习优化,利用优化目标约束求解所得参数的误差满足设定阈值为止
60、有益效果:本发明构建的基于改进长短时记忆深度学习模型的大坝渗流预测方法,可有效解决传统渗流预测方法难以捕捉复杂时空关系的问题。由于传统预测方法依赖经验模型和简单统计,难以应对多因素动态变化的预测需求,因此,基于深度学习的智能预测方法研究具有重要的实用价值。同时,该方法在长短时记忆网络超参数优化方面的创新也具有重要的理论价值。通过引入二进制与实数分层混合编码的快速初始化方法、协同精英锦标赛策略和动态综合适应度评估的改进精英遗传算法,既显著提升了预测精度,又实现了模型参数的自动优化,相比传统手工调参方法可节省大量人力成本,为大坝安全智能监测提供了可靠的技术支撑。
- 还没有人留言评论。精彩留言会获得点赞!