基于无监督学习知识图谱构建方法及系统
本发明涉及知识图谱,具体为基于无监督学习知识图谱构建方法及系统。
背景技术:
1、知识图谱是一种结构化的语义知识库,用于描述实体及其关系,在智能搜索、问答系统、推荐系统等领域有广泛应用。
2、传统的知识图谱构建方法主要依赖人工定义的实体和大量标注数据,费时费力。
3、现有的文本知识图谱构建方法主要分为基于规则、基于监督学习和基于无监督学习三类。
4、基于规则的方法需要人工定义复杂的模板和规则,泛化能力差;基于监督学习的方法需要大量高质量的标注数据,人力成本高;基于无监督学习的方法无需人工定义规则和标注数据,可以自动挖掘文本中蕴含的知识,但抽取的知识质量和丰富度有待提高。
5、在实体识别方面,传统方法主要基于词典匹配、条件随机场等方法,泛化能力有限。
6、近年来,基于深度学习的命名实体识别方法取得了显著进展,特别是预训练语言模型如bert、roberta等,可以充分利用大规模语料中的语义知识,大幅提升实体识别效果。
7、然而,仅识别出实体还不够,还需要对同名实体进行消歧,链接到知识库中的标准实体。
8、在关系抽取方面,早期的方法主要基于模式匹配、启发式规则等,容易受限于人工定义的规则和模式。
9、随着语义解析技术的发展,研究者们提出了一些基于监督学习的关系抽取方法,从句法分析树或语义依存图中抽取实体对和关系触发词,然后使用分类模型判断关系类型。
10、这类方法可以处理复杂的句子结构,提取隐含的关系,但需要大量标注数据。
11、因此,亟须一种端到端的、高效准确的知识图谱构建方法,能够充分挖掘文本数据中的结构化知识,减少人工成本,提高知识抽取的质量和效率。
12、本发明正是在此背景下提出的,旨在提供一种基于无监督学习知识图谱构建方法及系统。
技术实现思路
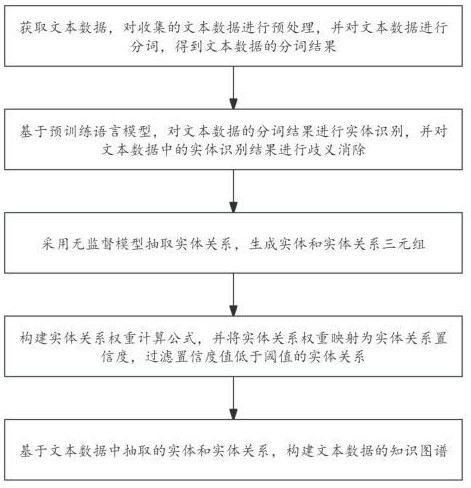
1、为解决上述技术问题,本发明提供如下技术方案:基于无监督学习知识图谱构建方法,包括:
2、获取文本数据,对收集的文本数据进行预处理,并对文本数据进行分词,得到文本数据的分词结果;
3、基于预训练语言模型,对文本数据的分词结果进行实体识别,并对文本数据中的实体识别结果进行歧义消除;
4、采用无监督模型抽取实体关系,生成实体和实体关系三元组;
5、构建实体关系权重计算公式,并将实体关系权重映射为实体关系置信度,过滤置信度值低于阈值的实体关系;
6、基于文本数据中抽取的实体和实体关系,构建文本数据的知识图谱。
7、作为本发明所述基于无监督学习知识图谱构建方法的一种优选方案,其中:对文本数据进行预处理,去除文本数据中的标签数据和符号数据;基于词典和分词工具,将文本数据中的文本划分为词语序列;
8、基于预定义的词典和规则,采用正向最大匹配算法对文本进行分词:将文本数据表示为由个词语组成的序列:;
9、定义词典,其中包含个词语:从左到右扫描文本,找出最长词语匹配;
10、设为当前扫描位置,为词语结束位置对于,判断子串是否在词典中;若子串在词典中,则将作为一个词语,并将移动到的位置;若子串不在词典中,则将移动到的位置;重复扫描过程,直到,得到文本数据的分词结果。
11、作为本发明所述基于无监督学习知识图谱构建方法的一种优选方案,其中:选择roberta预训练模型作为实体识别模型,并在roberta预训练模型的基础上,对roberta预训练模型进行调整,添加实体识别特定的网络层,包括线性层和crf层;
12、将分词结果输入调整后的模型,得到每个分词的标签概率分布,使用维特比算法解码,得到最优标签序列;提取实体及类型,得到实体识别结果;
13、对每个实体识别结果,从roberta预训练模型的知识库中检索同名候选实体,计算知识库中的实体与候选实体的相似度;选择相似度最高的候选实体作为链接对象:
14、其中,是知识库中的实体集合,将知识库中的实体链接到选定的候选实体,消除歧义。
15、作为本发明所述基于无监督学习知识图谱构建方法的一种优选方案,其中:选择openie模型作为无监督实体关系抽取模型;
16、将预处理后的文本数据和实体识别结果输入到openie模型,openie模型通过句法分析、实体识别、关系触发词识别、关系界定以及三元组生成的步骤抽取实体关系;
17、所述句法分析包括,使用依存句法分析器对输入的文本进行句法分析,识别出句子的主语、谓语和宾语成分;
18、所述实体识别包括,利用预先识别的实体信息,在句子中定位实体;
19、所述关系触发词识别包括,根据句法分析结果和预定义的规则,识别出表示实体关系的触发词;
20、所述关系界定包括,根据触发词和实体提及的位置,界定出实体关系的边界,提取出实体关系;
21、所述三元组生成包括,将实体对和关系描述组合成三元组,表示实体和实体之间存在关系。
22、作为本发明所述基于无监督学习知识图谱构建方法的一种优选方案,其中:构建实体关系权重计算公式,计算实体和实体之间的关系权重:
23、其中,和表示实体;为文本数据的发布日期衰减指数;为文本数据的发布日期;为当前日期;为参数;为文本数据的来源指数;和分别为实体和实体在文章中的词频,为文本数据中的实体最大词频。
24、作为本发明所述基于无监督学习知识图谱构建方法的一种优选方案,其中:对于抽取出的关系,将实体关系权重映射为实体和实体关系置信度:其中,为实体和实体关系置信度,表示实体和实体关系存在的可信程度。
25、作为本发明所述基于无监督学习知识图谱构建方法的一种优选方案,其中:设定置信度阈值,过滤置信度不满足要求的实体和实体关系:
26、若,则认为实体和实体之间的关系不存在;
27、若,则认为实体和实体之间的关系存在。
28、作为本发明所述基于无监督学习知识图谱构建方法的一种优选方案,其中:基于文本数据中抽取的实体和实体关系,构建文本数据的知识图谱;定义无向加权知识图谱,其中表示实体节点集合,表示实体关系边集合,表示实体关系权重集合;
29、对于每一个满足置信度要求的三元组,执行以下步骤:
30、步骤a:将实体和实体添加到节点集合中:;
31、步骤b:将实体关系作为无向边添加到边集合中:
32、;
33、步骤c:将实体关系置信度作为边的权重添加到权重集合中:;
34、步骤d:若实体和实体之间存在多个实体关系,则选择置信度最大的关系作为实体和实体之间的边:;
35、重复步骤a至步骤d,直到所有满足置信度要求的三元组都被处理完毕。
36、作为本发明所述基于无监督学习知识图谱构建方法的一种优选方案,其中:在处理完所有三元组后,得到由实体节点、实体关系边和实体关系权重组成的无向加权知识图谱,其中,节点表示第个实体;边表示实体和实体之间存在语义关系;权重表示边对应的实体关系置信度,反映实体关系的可信程度。
37、基于无监督学习知识图谱构建系统,其用于实现基于无监督学习知识图谱构建方法,包括:数据获取模块、实体识别模块、实体关系抽取模块、实体关系权重计算模块以及知识图谱模块;
38、所述数据获取模块,用于获取文本数据,对收集的文本数据进行预处理,并对文本数据进行分词,得到文本数据的分词结果;
39、所述实体识别模块,基于预训练语言模型,对文本数据的分词结果进行实体识别,并对文本数据中的实体识别结果进行歧义消除;
40、所述实体关系抽取模块,采用无监督模型抽取实体关系,生成实体和实体关系三元组;
41、所述实体关系权重计算模块,构建实体关系权重计算公式,并将实体关系权重映射为实体关系置信度,过滤置信度值低于阈值的实体关系;
42、所述知识图谱模块,基于文本数据中抽取的实体和实体关系,构建文本数据的知识图谱。
43、本发明的有益效果:本发明通过预处理和分词提高了数据质量,为后续步骤提供了结构化的词语序列输入,提升了处理效率和准确性。
44、本发明利用预训练语言模型进行实体识别和歧义消除,充分利用模型学习到的语义知识,提高了实体识别的准确性和一致性。
45、本发明采用无监督模型自动抽取实体关系,无需人工定义复杂规则,减少人力成本,提取出丰富全面的实体关系知识。
46、本发明构建权重计算公式并过滤低置信度关系,综合多因素计算权重,提高了知识图谱中实体关系的可信程度。
47、本发明构建知识图谱实现了从非结构化文本到结构化知识的转换,为知识驱动的任务提供高层语义表示,提升任务性能。
- 还没有人留言评论。精彩留言会获得点赞!