基于大模型提高数据直达效率的方法、设备及介质与流程
本发明涉及大模型及数据处理,具体地说是一种基于大模型提高数据直达效率的方法、设备及介质。
背景技术:
1、大数据技术是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合所需的技术,涵盖大数据的采集、存储、处理、分析、挖掘和可视化等各个环节。大数据技术被广泛应用于电商、政务、医疗、传媒、安防、金融、电信、交通、体育、制造业、能源和公用事业等领域。
2、数据实时处理是指计算机对现场数据在其发生的实际时间内进行收集和处理的过程。
3、故如何减少大数据处理过程中数据传输和处理的时间延迟,确保数据时的完整性和一致性的同时,提高数据直达的时效性是目前亟待解决的技术问题。
技术实现思路
1、本发明的技术任务是提供一种基于大模型提高数据直达效率的方法、设备及介质,来解决如何减少大数据处理过程中数据传输和处理的时间延迟,确保数据时的完整性和一致性的同时,提高数据直达的时效性的问题。
2、本发明的技术任务是按以下方式实现的,一种基于大模型提高数据直达效率的方法,该方法具体如下:
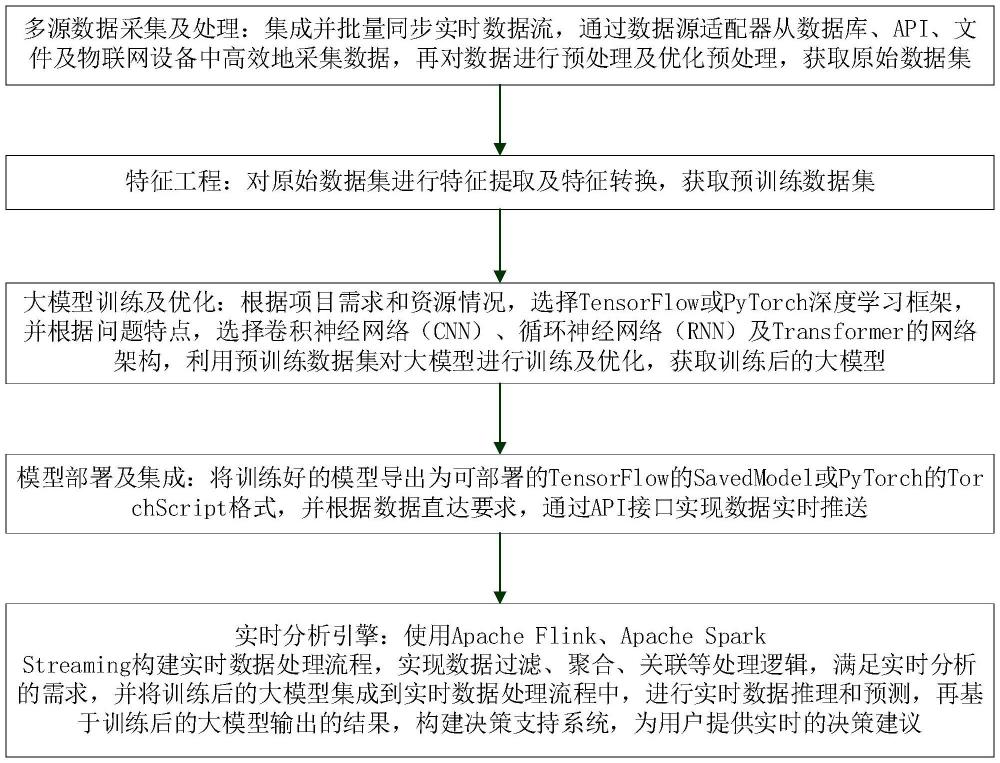
3、多源数据采集及处理:集成并批量同步实时数据流,通过数据源适配器从数据库、api、文件及物联网设备中高效地采集数据,再对数据进行预处理及优化预处理,获取原始数据集;
4、特征工程:对原始数据集进行特征提取及特征转换,获取预训练数据集;
5、大模型训练及优化:根据项目需求和资源情况,选择tensorflow或pytorch深度学习框架,并根据问题特点,选择卷积神经网络(cnn)、循环神经网络(rnn)及transformer的网络架构,利用预训练数据集对大模型进行训练及优化,获取训练后的大模型;
6、模型部署及集成:将训练好的模型导出为可部署的tensorflow的savedmodel或pytorch的torchscript格式,并根据数据直达要求,通过api接口实现数据实时推送;
7、实时分析引擎:使用apache flink、apache spark streaming构建实时数据处理流程,实现数据过滤、聚合、关联等处理逻辑,满足实时分析的需求,并将训练后的大模型集成到实时数据处理流程中,进行实时数据推理和预测,再基于训练后的大模型输出的结果,构建决策支持系统,为用户提供实时的决策建议。
8、作为优选,集成实时数据流具体为:采用apache kafka、apache flink或amazonkinesis流处理框架,实现数据的实时采集和传输,并实时监控数据流状态,确保数据采集的连续性和稳定性;
9、批量同步数据具体为:设置定时任务,使用cron作业或apache airflow定期行数据源同步数据,并采用增量数据同步机制仅同步采集后的新增或变更数据,减少数据传输量;
10、数据源适配器采用插件式架构,允许动态添加新的数据源适配器,以适应不断变化的数据源需求。
11、作为优选,对数据进行预处理及优化预处理具体如下:
12、数据清洗:根据识别并处理异常值、缺失值的数据清洗规则自动化清洗数据,并根据数据直达的实时反馈,动态调整清洗规则,以适应数据源的变化;
13、格式转换:统一数据格式,确保所有采集的数据都转换为大模型能够处理的json或parquet标准格式;
14、特征标准化:利用大模型对数据进行特征标准化,使得数据在进入大模型之前具有一致的分布和尺度;
15、数据脱敏:使用大模型辅助识别敏感数据字段,确保在数据直达过程中遵守数据保护法规,并根据数据的使用场景和用户权限,动态应用脱敏策略,如加密、掩码等;
16、预处理优化:利用分布式计算框架(如apache spark)并行处理数据预处理任务,提高处理效率,并使用大模型预测和指导预处理过程,例如预测哪些数据字段可能需要更多的清洗工作。
17、作为优选,特征提取具体如下:
18、数据探索:对原始数据进行探索性分析,获取数据分布、异常值及缺失值的情况;
19、特征识别:使用统计方法和机器学习算法(如决策树、随机森林)自动识别重要特征;
20、特征构建:根据业务知识和领域专家意见,构建新的特征,如时间窗口统计特征、文本嵌入特征等;
21、作为优选,特征转换具体如下:
22、标准化:应用z-score标准化或min-max标准化方法,使特征数据具有统一的标准尺度;
23、编码:通过独热编码(one-hot encoding)或标签编码(label encoding)对类别特征进行编码处理;
24、降维:使用主成分分析(pca)及t-sne方法减少特征维度,提高模型训练效率。
25、作为优选,大模型训练及优化具体如下:
26、数据集准备:将数据集划分为训练集、验证集和测试集;
27、超参数调优:通过交叉验证方法调整学习率、批次大小、层数、神经元数量超参数;
28、训练过程:使用gpu或tpu硬件加速训练过程,监控训练损失和准确率指标;
29、正则化:应用l1、l2正则化或dropout方法防止过拟合;
30、模型剪枝:减少模型中的冗余参数,提高模型效率和推理速度;
31、量化:通过模型量化减少模型大小和提升推理速度。
32、更优地,模型部署及集成具体如下:
33、服务器配置:配置服务器硬件和软件环境,确保满足训练后的大模型运行需求;
34、容器化:使用docker容器技术,将训练后的大模型及其依赖封装为一个可移植的容器;
35、api封装:为训练后的大模型创建api接口,使训练后的大模型被其他系统调用;
36、数据流集成:确保训练后的大模型输入和输出与数据采集、预处理和后处理环节无缝对接;
37、性能监控:部署后监控训练后的模型的性能和资源消耗,确保系统稳定运行;
38、接口定义:根据数据直达的需求,定义restful api接口,明确接口的功能、参数和返回格式;
39、接口实现:利用框架如flask或fastapi,实现api接口,确保接口的高性能和安全性;
40、数据推送:通过websocket或server-sent events(sse)技术实现数据的实时推送;
41、消息队列选择:使用rabbitmq或apache kafka消息队列系统,实现数据的异步处理和传输;
42、消息格式:定义统一的消息格式,确保数据的一致性和可解析性;
43、消息可靠性:确保消息队列的可靠性,防止数据丢失。
44、一种基于大模型提高数据直达效率的系统,该系统用于实现如上述的基于大模型提高数据直达效率的方法;该系统包括:
45、多源数据采集及处理单元,用于集成并批量同步实时数据流,通过数据源适配器从数据库、api、文件及物联网设备中高效地采集数据,再对数据进行预处理及优化预处理,获取原始数据集;
46、特征工程单元,用于对原始数据集进行特征提取及特征转换,获取预训练数据集;
47、大模型训练及优化单元,用于根据项目需求和资源情况,选择tensorflow或pytorch深度学习框架,并根据问题特点,选择卷积神经网络(cnn)、循环神经网络(rnn)及transformer的网络架构,利用预训练数据集对大模型进行训练及优化,获取训练后的大模型;
48、模型部署及集成单元,用于将训练好的模型导出为可部署的tensorflow的savedmodel或pytorch的torchscript格式,并根据数据直达要求,通过api接口实现数据实时推送;
49、实时分析引擎单元,用于使用apache flink、apache spark streaming构建实时数据处理流程,实现数据过滤、聚合、关联等处理逻辑,满足实时分析的需求,并将训练后的大模型集成到实时数据处理流程中,进行实时数据推理和预测,再基于训练后的大模型输出的结果,构建决策支持系统,为用户提供实时的决策建议。
50、一种电子设备,包括:存储器和至少一个处理器;
51、其中,所述存储器存储计算机执行指令;
52、所述至少一个处理器执行所述存储器存储的计算机执行指令,使得所述至少一个处理器执行如上述的基于大模型提高数据直达效率的方法。
53、一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当处理器执行所述计算机执行时,实现如上述的基于大模型提高数据直达效率的方法。
54、本发明的基于大模型提高数据直达效率的方法、设备及介质具有以下优点:
55、(一)本发明优化了数据流转,以优化数据从源头到目的地的流转过程,减少数据传输和处理的时间延迟;
56、(二)本发明实现了数据融合与整合:利用大模型实现跨部门、跨领域的数据融合,确保数据直达时的完整性和一致性;
57、(三)本发明实现了实时数据处理:通过大模型实现数据的实时处理和分析,提高数据直达的时效性;
58、(四)本发明实现了自动化数据预处理:大模型可以自动处理和清洗数据,识别数据中的错误和不一致性,从而提高数据质量,对于确保数据直达过程中的信息准确性至关重要;
59、(五)本发明实现了智能数据分类和标签化:大模型能够对数据进行智能分类和标签化,这使得在数据直达过程中,相关数据可以更快地被定位和分发到适当的接收者;
60、(六)本发明实现了数据挖掘和洞察:大型模型可以快速从大量数据中提取有用信息,发现数据间的模式和关联,这有助于在数据直达过程中快速生成有价值的洞察;
61、(七)本发明对于非结构化数据,如文本和语音,大模型可以用于理解和提取关键信息,使得这些数据可以在数据直达过程中被有效利用;
62、(八)本发明的大模型可以基于历史数据预测未来趋势或行为,这对于在数据直达中实现自动化决策支持非常有用,例如预测哪些数据对特定基层单位最为重要;
63、(九)本发明使用海量的数据进行训练,确保模型能够捕捉到数据中的复杂模式和关系,并应用深度学习技术,例如神经网络,来构建具有大量参数的大模型;
64、(十)本发明对输入数据进行高效的清洗、归一化和特征提取,减少噪声,提高数据质量,并实施数据增强策略,以扩充数据集,增强模型的泛化能力;
65、(十一)本发明采用模型剪枝、量化等技术减少模型大小,提高模型的推理速度,并实施知识蒸馏,将大模型的知识迁移到更小的模型上,以保持性能的同时减少计算资源消耗;
66、(十二)本发明使用专门的推理引擎,如tensorrt或onnx runtime,来优化模型的推理过程,并支持模型的分布式推理,利用多核cpu、gpu或专用加速器来并行处理数据;
67、(十三)本发明根据数据特征和模型特点,设计智能路由算法,将数据高效地分配到不同的处理路径上,并实施动态路由策略,根据系统负载和模型性能自动调整数据处理流程;
68、(十四)本发明引入高效的缓存机制,对于频繁访问的数据或模型推理结果进行缓存,减少重复计算,并实施基于lru等策略的缓存淘汰机制,保持缓存中的数据是最有用的;
69、(十五)本发明利用实时监控数据,对模型性能进行评估,并根据反馈进行动态调整,并实施在线学习或增量学习策略,使模型能够不断从新数据中学习并更新;
70、(十六)本发明对整个数据处理链路进行端到端优化,减少数据处理和传输的延迟,同时结合硬件特性,如使用特定硬件加速器来优化数据处理速度。
- 还没有人留言评论。精彩留言会获得点赞!